用圖像混合學習更細粒度的特征表示,CMU邢波團隊新論文入選AAAI

這是一篇來自卡耐基梅隆大學和加州伯克利大學 Eric Xing 和 Trevor Darrell 團隊聯合出品的論文,探究如何在自監督雙子結構中通過圖像混合學習更加細粒度的特征表示,并入選 AAAI 2022。

- 論文鏈接:https://arxiv.org/pdf/2003.05438.pdf
- 代碼鏈接:https://github.com/szq0214/Un-Mix
文章核心思想非常直觀易懂:希望去探究在自監督學習常用的雙子結構網絡中,通過在輸入空間做圖像融合來學習更加細粒度的特征表示。核心內容討論了如何來設計數據采樣和構建對應的損失函數,從而去匹配圖像融合之后新的輸入空間。
如下圖所示,首先形象地解釋這一基于圖像融合在自監督學習中實現更加細粒度的距離度量的機制:
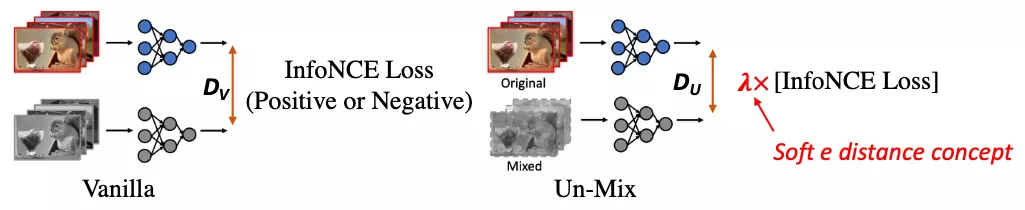
左邊示例表示一般常用的雙子自監督網絡結構的工作原理,它的兩個分支的距離就是默認的距離度量,比如使用 InfoNCE 去分類輸入的圖片對是正對 (positive) 還是負對 (negative)。
右邊是本文 Un-Mix 提出的研究思路,即通過在一個分支上做圖像融合,使得最后的距離度量變為一個 [0,1] 之間的軟化系數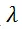 的倍數,從而使兩個分支之間的距離變得更加細微和敏感(該工作是首個在自監督雙子模型中引入了軟距離概念的文章),進而讓模型學習到更加細粒度的輸入信息的隱空間表達。
的倍數,從而使兩個分支之間的距離變得更加細微和敏感(該工作是首個在自監督雙子模型中引入了軟距離概念的文章),進而讓模型學習到更加細粒度的輸入信息的隱空間表達。
實現策略
具體怎么來方便簡單地實現這一機制呢?本文作者提出了如下一種策略:通過在一個 mini-batch 內部通過某種順序做樣本融合,從而得到固定的距離度量,如下圖所示:
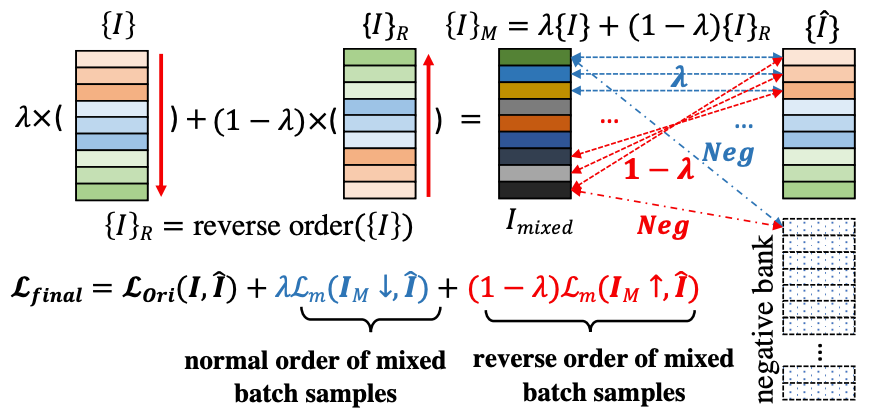
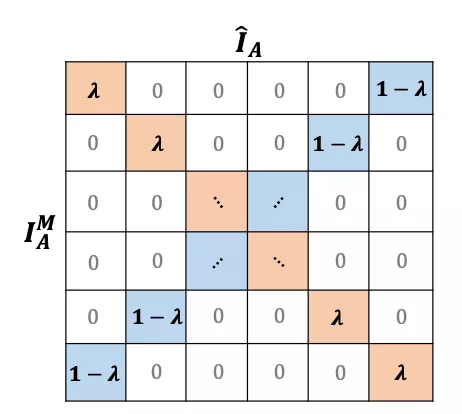
具體地,作者將一個批量(mini-batch)中的樣本做一個倒序,然后跟原來的樣本們做加權融合,兩張原圖的距離分別變成為λ和1-λ ,因此一個批量樣本集合之間相互的語義距離矩陣變為如下形式:
利用這一新的距離度量,我們可以使用新的損失函數來訓練模型,如下所示:
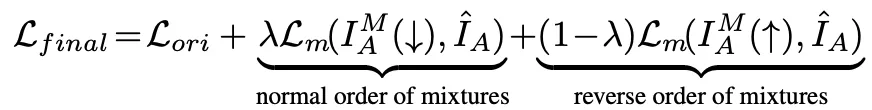
下面是 Un-Mix 算法實現的偽代碼:

實驗結果
作者在多個數據集上進行了大量的實驗。
首先是非 ImageNet 數據集上的訓練和測試曲線:
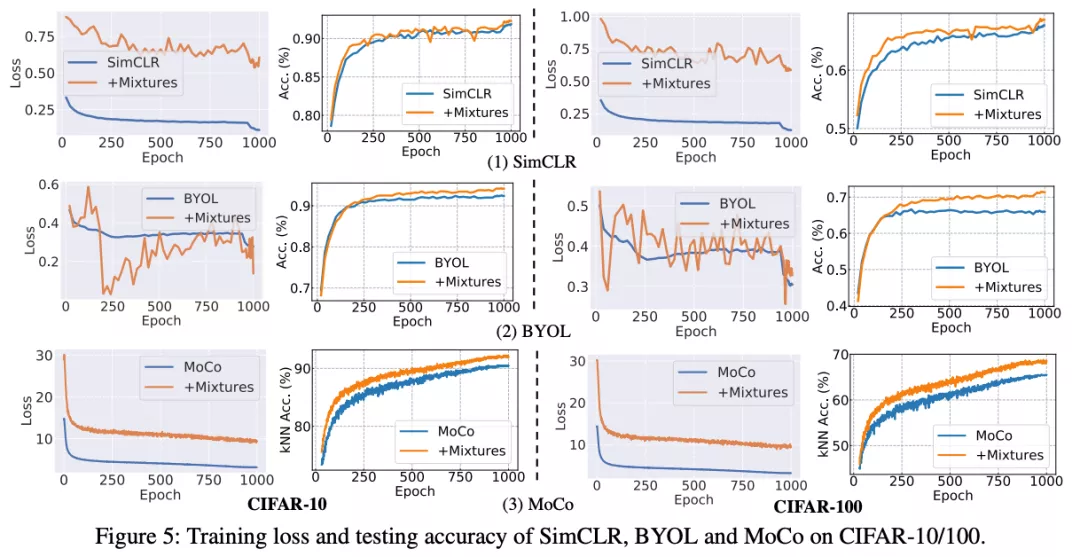
可以發現一個比較有趣的現象:在加入了 Un-Mix 之后,訓練的損失值(training loss)變得非常不穩定,波動很大,這是因為在輸入空間進行圖像融合操作之后導致兩個分支的距離度量變得更加細微多樣和敏感。但是這對模型泛化能力是有幫助的,在做模型測試的時候依然可以取得更好的測試性能。
具體的數值結果對比如下,可以看到在不同數據集和對照方法上結果都有非常明顯的提升。

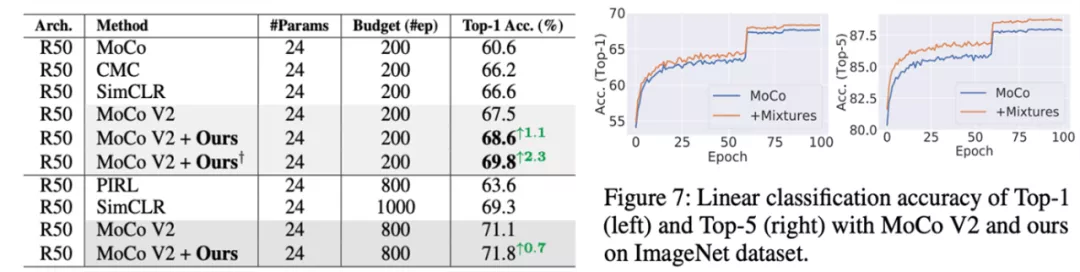
接下來是在 ImageNet 上的結果,文章提出的方法在 200 和 800 epoch 兩種不同的的訓練參數設置下都有比較穩定的提升:
最后是在下游任務目標檢測上的遷移結果,該方法依然有穩定的提升:
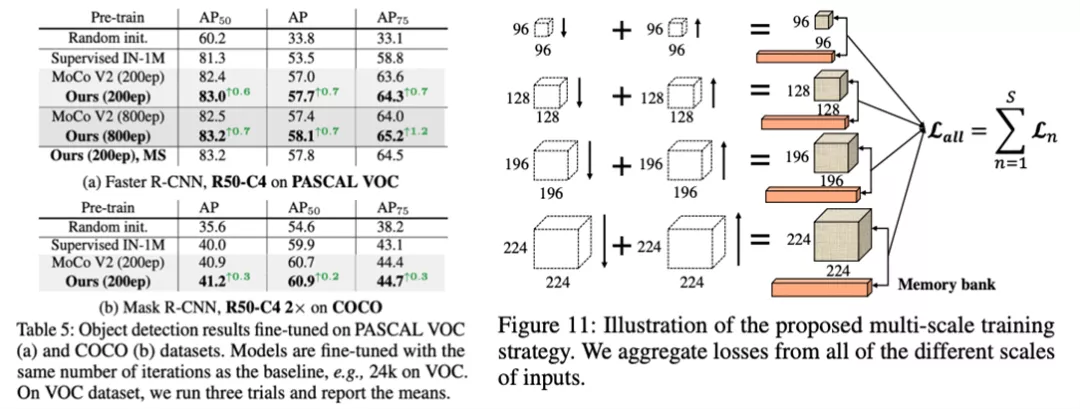
此外,作者還討論了如何處理含有 memory bank 的框架以及如何進行多尺度(multi-scale)訓練(如上圖 11 所示),有興趣的同學可以去閱讀原論文。