













前綴索引,中看也中用!
最近幾篇文章,都是在和大家聊索引的問題,今天我們來(lái)看看前綴索引。
1.什么是前綴索引
所謂前綴索引說(shuō)白了就是對(duì)文本的前幾個(gè)字符建立索引(具體是幾個(gè)字符在建立索引時(shí)指定),這樣建立起來(lái)的索引更小,所以查詢更快。這有點(diǎn)類似于 Oracle 中對(duì)字段使用 Left 函數(shù)來(lái)建立函數(shù)索引,只不過 MySQL 的這個(gè)前綴索引在查詢時(shí)是內(nèi)部自動(dòng)完成匹配的,并不需要使用 Left 函數(shù)。
那么為什么不對(duì)整個(gè)字段建立索引呢?一般來(lái)說(shuō)使用前綴索引,可能都是因?yàn)檎麄€(gè)字段的數(shù)據(jù)量太大,沒有必要針對(duì)整個(gè)字段建立索引,前綴索引僅僅是選擇一個(gè)字段的部分字符作為索引,這樣一方面可以節(jié)約索引空間,另一方面則可以提高索引效率,當(dāng)然很明顯,這種方式也會(huì)降低索引的選擇性。
這里又涉及到一個(gè)概念,什么是索引選擇性?
2.什么是索引選擇性
關(guān)于索引的選擇性(Index Selectivity),它是指不重復(fù)的索引值(也稱為基數(shù) cardinality)和數(shù)據(jù)表的記錄總數(shù)的比值,取值范圍在 [0,1] 之間。索引的選擇性越高則查詢效率越高,因?yàn)檫x擇性高的索引可以讓 MySQL 在查找時(shí)過濾掉更多的行。
那有小伙伴要問了,是不是選擇性越高的索引越好呢?當(dāng)然不是!索引選擇性最高為 1,如果索引選擇性為 1,就是唯一索引了,搜索的時(shí)候就能直接通過搜索條件定位到具體一行記錄!這個(gè)時(shí)候雖然性能最好,但是也是最費(fèi)空間的,這不符合我們創(chuàng)建前綴索引的初衷。
我們一開始之所以要?jiǎng)?chuàng)建前綴索引而不是唯一索引,就是希望能夠在索引的性能和空間之間找到一個(gè)平衡,我們希望能夠選擇足夠長(zhǎng)的前綴以保證較高的選擇性(這樣在查詢的過程中就不需要掃描很多行),但是又希望索引不要太過于占用存儲(chǔ)空間。
那么我們?cè)撊绾芜x擇一個(gè)合適的索引選擇性呢?索引前綴應(yīng)該足夠長(zhǎng),以便前綴索引的選擇性接近于索引的整個(gè)列,即前綴的基數(shù)應(yīng)該接近于完整列的基數(shù)。
首先我們可以通過如下 SQL 得到全列選擇性:
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
然后再通過如下 SQL 得到某一長(zhǎng)度前綴的選擇性:
SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;
在上面這條 SQL 執(zhí)行的時(shí)候,我們要注意選擇合適的 prefix_length,直至計(jì)算結(jié)果約等于全列選擇性的時(shí)候,就是最佳結(jié)果了。
3.創(chuàng)建前綴索引
3.1 一個(gè)小案例舉個(gè)例子,我們來(lái)創(chuàng)建一個(gè)前綴索引看看。
松哥這里使用的數(shù)據(jù)樣例是網(wǎng)上找的一個(gè)測(cè)試腳本,有 300W+ 條數(shù)據(jù),做 SQL 測(cè)試優(yōu)化是夠用了,小伙伴們?cè)诠娞?hào)后臺(tái)回復(fù) mysql-data-samples 獲取腳本下載鏈接。
我們來(lái)大致上看下這個(gè)表結(jié)構(gòu):

這個(gè)表有一個(gè) user_uuid 字段,我們就在這個(gè)字段上做文章。
Git 小伙伴們應(yīng)該都會(huì)用吧?不同于 Svn,Git 上的版本號(hào)不是數(shù)字而是一個(gè) Hash 字符串,但是我們?cè)诰唧w應(yīng)用的時(shí)候,比如你要做版本回退,此時(shí)并不需要輸入完整的的版本號(hào),只需要輸入版本號(hào)前幾個(gè)字符就行了,因?yàn)楦鶕?jù)前面這一部分就能確定出版本號(hào)了。
那么這張表里邊的 user_uuid 字段也是這意思,如果我們想給 user_uuid 字段建立索引,就沒有必要給完整的字符串建立索引,我們只需要給一部分字符串建立索引。
可能有小伙伴還是不太明白,我舉一個(gè)例子,比如說(shuō)我現(xiàn)在想按照 user_uuid 字段來(lái)查詢,但是查詢條件我沒有必要寫完整的 user_uuid,我只需要寫前面一部分就可以區(qū)分出我想要的記錄了,我們來(lái)看如下一條 SQL:

大家看到,user_uuid 我只需要給出一部分就能唯一鎖定一條記錄。
當(dāng)然,上面這個(gè) SQL 是松哥測(cè)試過的,給定的 '39352f%' 條件不能再短了,再短就會(huì)查出來(lái)兩條甚至多條記錄。
通過上面這個(gè)例子我們就可以看出來(lái),如果給 user_uuid 字段建立索引,可能并不需要給完整的字符串建立索引,只需要給一部分前綴字符串建立索引。
那么給前面幾個(gè)字符串建立索引呢?這個(gè)可不是拍腦門,需要科學(xué)計(jì)算,我們繼續(xù)往下看。
3.2 前綴索引
首先我們通過如下 SQL 來(lái)看一下 user_uuid 全列索引選擇性是多少:
SELECT COUNT(DISTINCT user_uuid) / COUNT(*) FROM system_user;

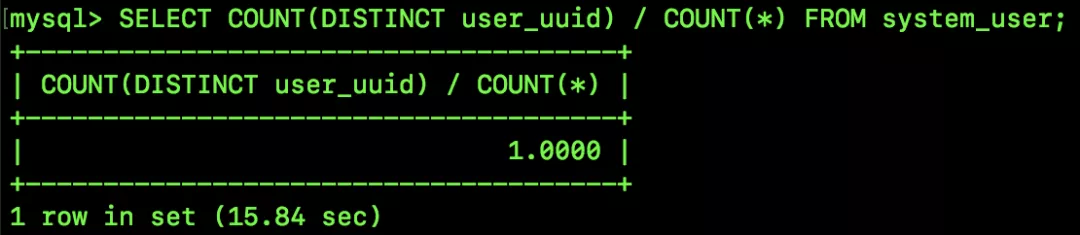
可以看到,結(jié)果為 1。全列選擇性為 1 說(shuō)明這一列的值都是唯一不重復(fù)的。
接下來(lái)我們先來(lái)試幾個(gè)不同的 prefix_length,看看選擇性如何。
松哥這里一共測(cè)試了 5 個(gè)不同的 prefix_length,大家來(lái)看看各自的選擇性:
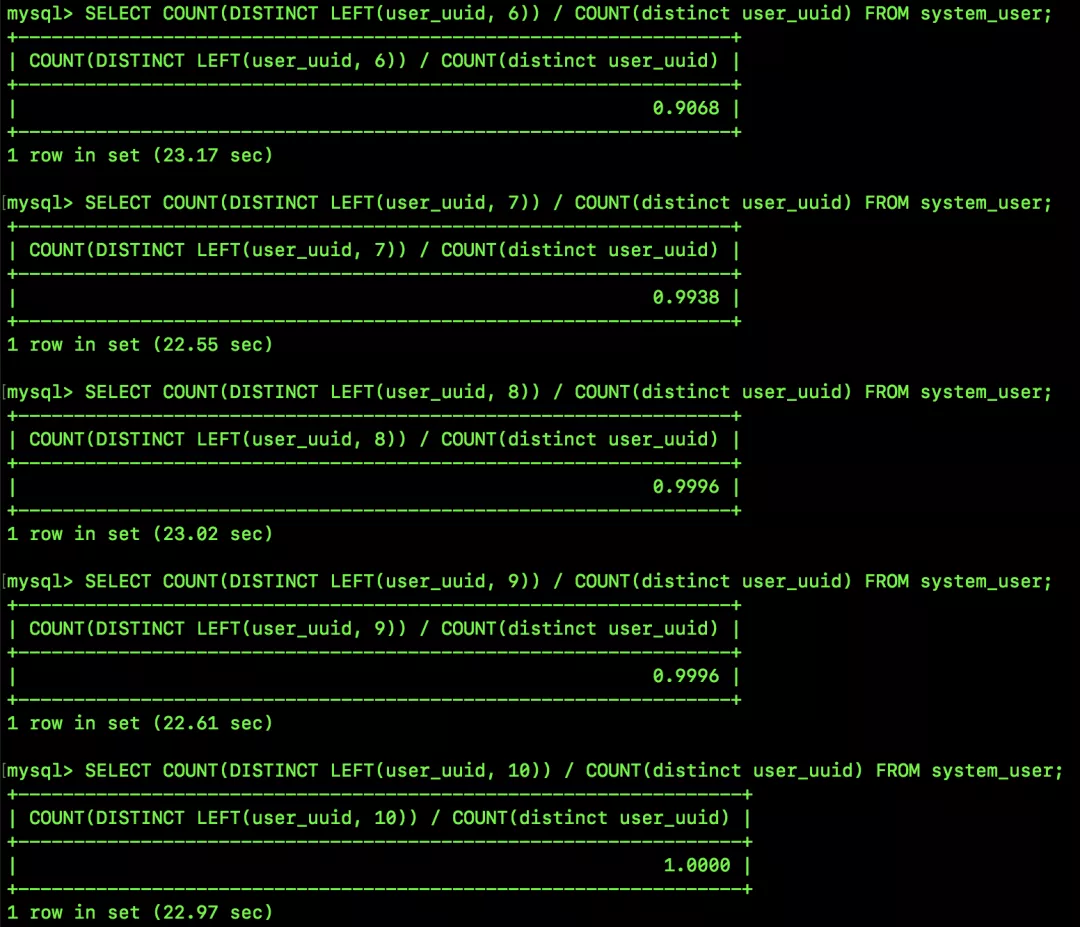
8 和 9 的選擇性是一樣的,因?yàn)樵?uuid 字符串中,第 9 個(gè)字符串是 -,所有的 uuid 第九個(gè)字符串都一樣,所以 8 個(gè)字符和 9 個(gè)字符串的區(qū)分度就一樣。
當(dāng) prefix_length 為 10 的時(shí)候,選擇性就已經(jīng)是 1 了,意思是,在這 300W+ 條數(shù)據(jù)中,如果我用 user_uuid 這個(gè)字段去查詢的話,只需要輸入前十個(gè)字符,就能唯一定位到一條具體的記錄了。
那還等啥,趕緊創(chuàng)建前綴索引唄:
alter table system_user add index user_uuid_index(user_uuid(10));
查看剛剛創(chuàng)建的前綴索引:
show index from system_user;
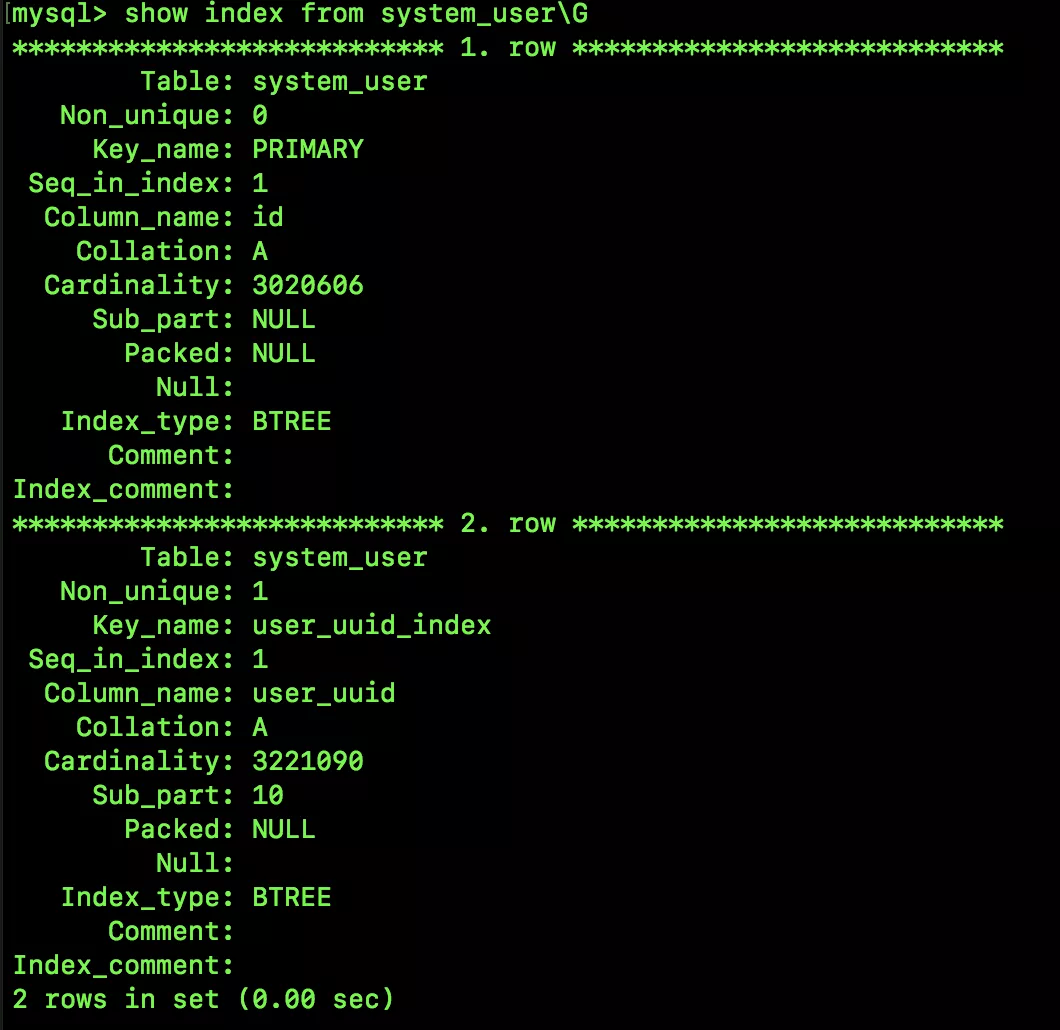
可以看到,第二行就是我們剛剛創(chuàng)建的前綴索引。
接下來(lái)我們分析查詢語(yǔ)句中是否用到該索引:
select * from system_user where user_uuid='39352f81-165e-4405-9715-75fcdf7f7068';
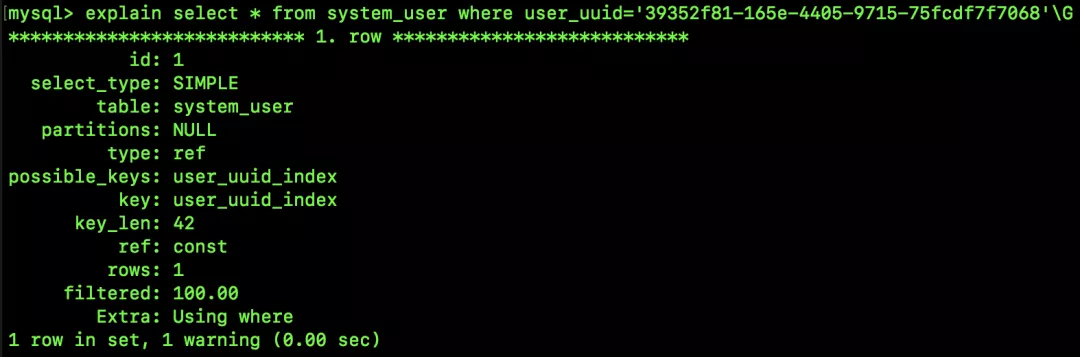
可以看到,這個(gè)前綴索引已經(jīng)用上了。
具體搜索流程是這樣:
- 從 user_uuid_index 索引中找到第一個(gè)值為 39352f81-1 的記錄(user_uuid 的前十個(gè)字符)。
- 由于 user_uuid 是二級(jí)索引,葉子結(jié)點(diǎn)保存的是主鍵值,所以此時(shí)拿到了主鍵 id 為 1。
- 拿著主鍵 id 去回表,在主鍵索引上找到 id 為 1 的行的完整記錄,返回給 server 層。
- server 層判斷其 user_uuid 是不是 39352f81-165e-4405-9715-75fcdf7f7068(所以執(zhí)行計(jì)劃的 Extra 為 Using where)。
- 如果不是,這行記錄丟棄。
- 如果是,將該記錄加入結(jié)果集。
- 索引葉子結(jié)點(diǎn)上數(shù)據(jù)之間是有單向鏈表維系的,所以接著第一步查找的結(jié)果,繼續(xù)向后讀取下一條記錄,然后重復(fù) 2、3、4 步,直到在 user_uuid_index 上取到的值不為 39352f81-1 時(shí),循環(huán)結(jié)束。
如果我們建立了前綴索引并且前綴索引的選擇性為 1,那么就不需要第 5 步了,如果前綴索引選擇性小于 1,就需要第五步。
從上面的案例中,小伙伴們看到,我們既節(jié)省了空間,又提高了搜索效率。
3.3 一個(gè)問題
使用了前綴索引后,我們來(lái)看一個(gè)問題,大家來(lái)看如下一條查詢 SQL:
select user_uuid from system_user where user_uuid='39352f81-165e-4405-9715-75fcdf7f7068';
這次不是 select *,而是 select user_uuid,按照松哥之前的文章(是時(shí)候檢查一下使用索引的姿勢(shì)是否正確了!),大家知道,這里應(yīng)該是要用到覆蓋索引,我們來(lái)看看執(zhí)行計(jì)劃:
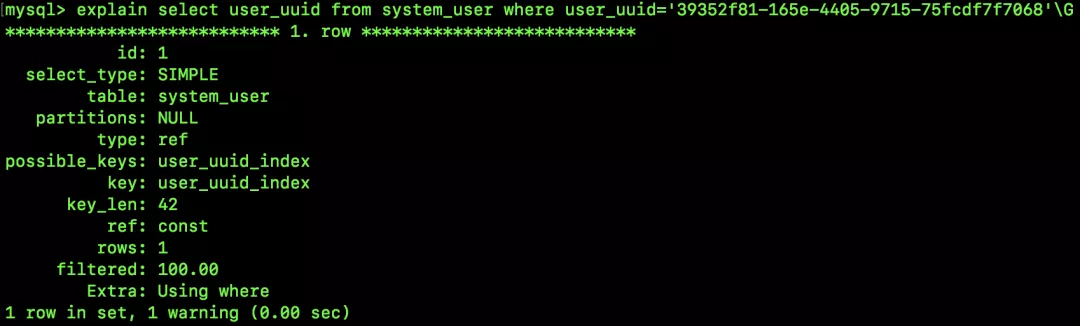
咦,說(shuō)好的索引覆蓋呢?(注意看 Extra 是 Using where)。
大家想想,前綴索引中,B+Tree 里保存的就不是完整的 user_uuid 字段的值,必須要回表才能拿到需要的數(shù)據(jù)。所以,用了前綴索引,就用不了覆蓋索引了。
4.小結(jié)
好啦,這就是前綴索引,請(qǐng)大家結(jié)合自己項(xiàng)目的實(shí)際需求使用。今天就先聊這么多,剩下的我們以后再扯吧~


















