如何選擇充血模型和貧血模型
從領域模型說起
回顧一下我們進行領域建模時候的流程:
- 進行需求分析
- 進行用例設計
- 針對用例進行領域建模
- 針對領域模型并行進行數據庫設計和程序設計。
在經過了前面幾步分析后,我們會得到領域模型以及他們之間的關系。在這之后我們要根據領域模型分別進行數據庫設計與程序設計。我們會根據領域模型之間的關系將模型之間的關系映射到系統表設計之間的關系。那么我們該怎么進行對應的程序設計呢?
一般來說:
將領域模型設計轉化為程序設計,有貧血模型與充血模型兩種方法。
貧血模型
在之前的文章中我們舉過一個訂單模型的例子:
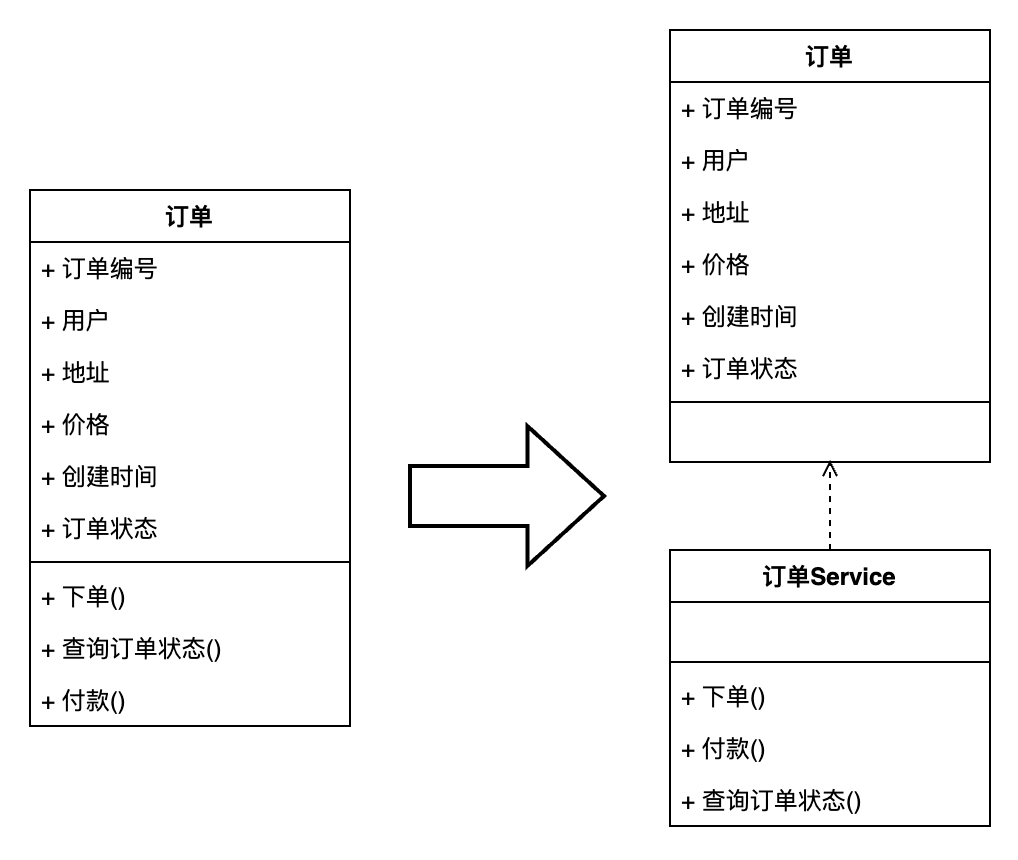
在這個例子中我們經過了設計和抽象得到了一個訂單模型。而根據這個模型,我們可以直接將模型中的屬性抽離成為一個模型設計,將模型中的方法能力抽取為一個服務設計。也就是說:
只由屬性及其賦值器、取值器構成的對象,我們稱之為貧血模型。
那么如果使用貧血模型進行領域模型的程序設計,就會像上圖中的例子一樣,得到一個領域模型的實體對象與服務。實體對象將包含模型對象的所有屬性與數據,服務中包含領域模型中的所有方法。當我們希望使用領域模型中的方法時,是將模型實體作為參數調用服務中領域模型對應的方法。
在利用貧血模型建模后,原有的領域模型中的數據與方法被割裂到了兩個對象中。而這種割裂使得原本被封裝到一個對象中的內容,被分開到了兩個對象中。而打破了原本領域模型的封裝性。
封裝性的打破會帶來新的問題,我舉一個我在實際生產中遇到過的例子:
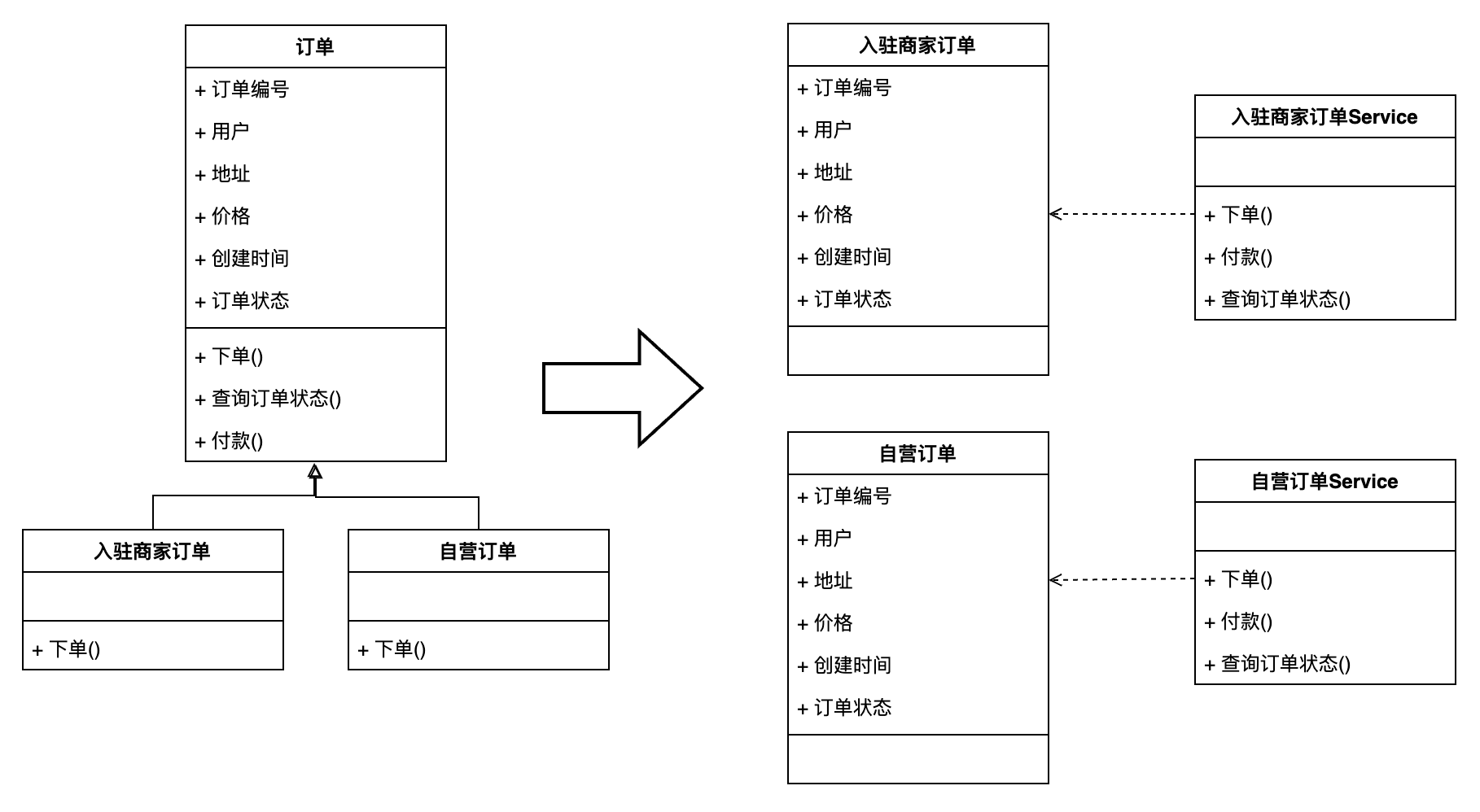
如圖所示,如果對于訂單來說我們出現了兩種子對象:入駐商家訂單、自營訂單。對于這兩種訂單的下單方法中是有不一樣的業務流程的。如果使用貧血模型設計的話,我們很容易就想到將兩個不一樣的下單業務流程分別通過兩個服務來實現。那么對應的,為了區分服務的不同,就需要將訂單也分別分割為兩個對象,并且指定的對象作為入參調用對應的服務。
而當這樣設計了之后,在訂單上游還需要一層業務編排層來對訂單數據的流轉進行處理,以保證對應的對象不會錯誤地進入到。
按照這樣的設計思想,如果在在這個基礎上新增一個“分銷訂單”。我們就需要調整三個地方:新增分銷訂單對象、新增分銷訂單服務、調整上游編排層。顯然這不符合開閉原則,同時業務開發的成本也提高。
注:我們可以通過設計模式優化最終實現的邏輯,但是設計思想是這樣的。
充血模型
貧血模型的問題在于割裂了領域模型的封裝,那么不對模型的封裝進行割裂,而是保留領域模型的原貌進行程序設計,就是充血模型。可以描述為:
將領域模型中的方法直接在領域對象中實現,就是充血模型設計。
根據上文中的訂單領域模型,如果我們換成充血模型設計,就變為了:
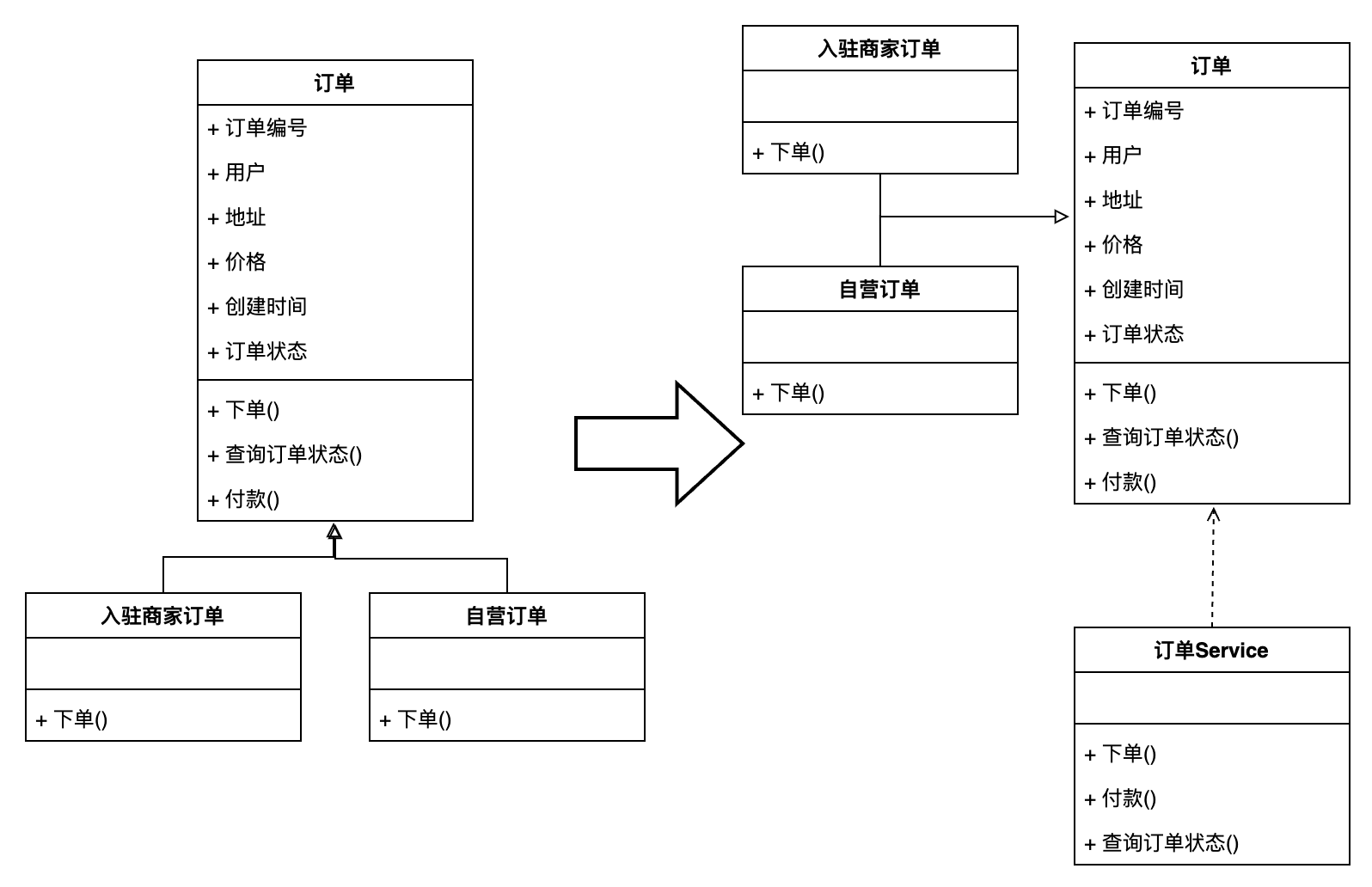
可以看到,如果采用充血模型的設計,訂單的實體對象中是包含領域模型中的方法的,也就是說下單的實際邏輯由訂單對象自己完成。而對于訂單對象中的子對象,也僅需要繼承訂單對象,然后實現自己的下單方法即可。使用充血模型設計后我們發現仍然有訂單對應的服務,但是這個服務僅執行一個調用訂單對象中對應邏輯的作用,而這樣的服務是不關心具體調用的是哪一個子類的。
所以,我們使用充血模型設計,當需要新增一個“分銷訂單”時,就只需要創建一個訂單的新的子類,然后在類中實現對應的下單邏輯就可以了,而這是符合開閉原則的。
而由于充血模型還原的是領域模型的原貌,所以在依據領域模型進行程序設計的時候,其映射關系直觀,所以對應的代碼修改就更直接。
貧血模型VS充血模型
通過上文分析,充血模型是全面優于貧血模型的。但是在實際的開發應用中并非如此。
貧血模型比充血模型實現更簡單
由于充血模型是還原領域模型的原貌,所以在進行程序的操作的時候,需要將模型下的所有組合、聚合對象都進行組裝,以訂單為例,訂單需要:訂單、訂單明細、用戶、用戶地址、商品等5個對象進行封裝。而由于封裝的復雜性,所以還需要設計訂單倉庫、訂單工廠等組件用于創建訂單的對象。同時因為創建后的對象大小可能會比較大,訂單倉庫中一般還需要進行緩存設計。總的來說:
充血模型要依靠強大的技術平臺來維護模型的使用。
而因為貧血模型是通過將模型之間進行分割而實現的,所以當操作訂單的時候,只需根據需要操作訂單、訂單明細就可以。而一般的三層設計Controller、Service、Dao就可以支撐起來訂單的模型設計。由于分割的模型數據不必組裝成領域模型對象,所以在Dao查詢完畢數據后,可以直接返回給Service進行使用,反之亦然。系統的復雜性大大降低。
貧血模型簡單直接,可在經典三層中直接實現。
充血模型需要具備更強的設計能力
由于充血模型是對領域模型的直接表現,所以領域模型設計的優劣會直接影響到系統的整體性能與擴展性。這就要求開發人員有更強的對象分析、對象設計能力。同時由于充血模型中需要對不同領域中的數據進行聚合,所以可能需要在團隊之間提出數據查詢需求,也就需要有更強的團隊協作能力。
而相反的,貧血模型所有業務處理都在service中進行操作,且對模型進行了分割,所以對于數據的外部依賴就更少,層級也更少。大部分邏輯都是直接Dao查詢數據庫后返回,對于開發人員的能力要求就更小。
貧血模型可面向步驟編程
在面對長串的復雜業務場景時,我們可能更傾向于將業務拆解為多個串聯的步驟然后獨立執行。而在使用貧血模型的情況下可以通過編寫多個Service直接進行面向步驟編程。每個Service可以處理對象中的部分數據,在通過多個Service處理后得到最終結果。
盡管充血模型也可以在方法中進行拆分,但是并不如貧血模型來的直接。
貧血模型AND充血模型
盡管上文中對充血模型與貧血模型進行了直接的區分,但是這兩種設計并非二元論的。簡單來說,我們可以根據充血模型與貧血模型的特點,選取我們需要的部分進行使用。例如:
- 將需要封裝的業務邏輯到領域對象中,按照充血模型去設計
- 將不需要封裝的業務邏輯放到Service中,按照貧血模型去設計
那么針對上文中的訂單模型來說設計就變成了:
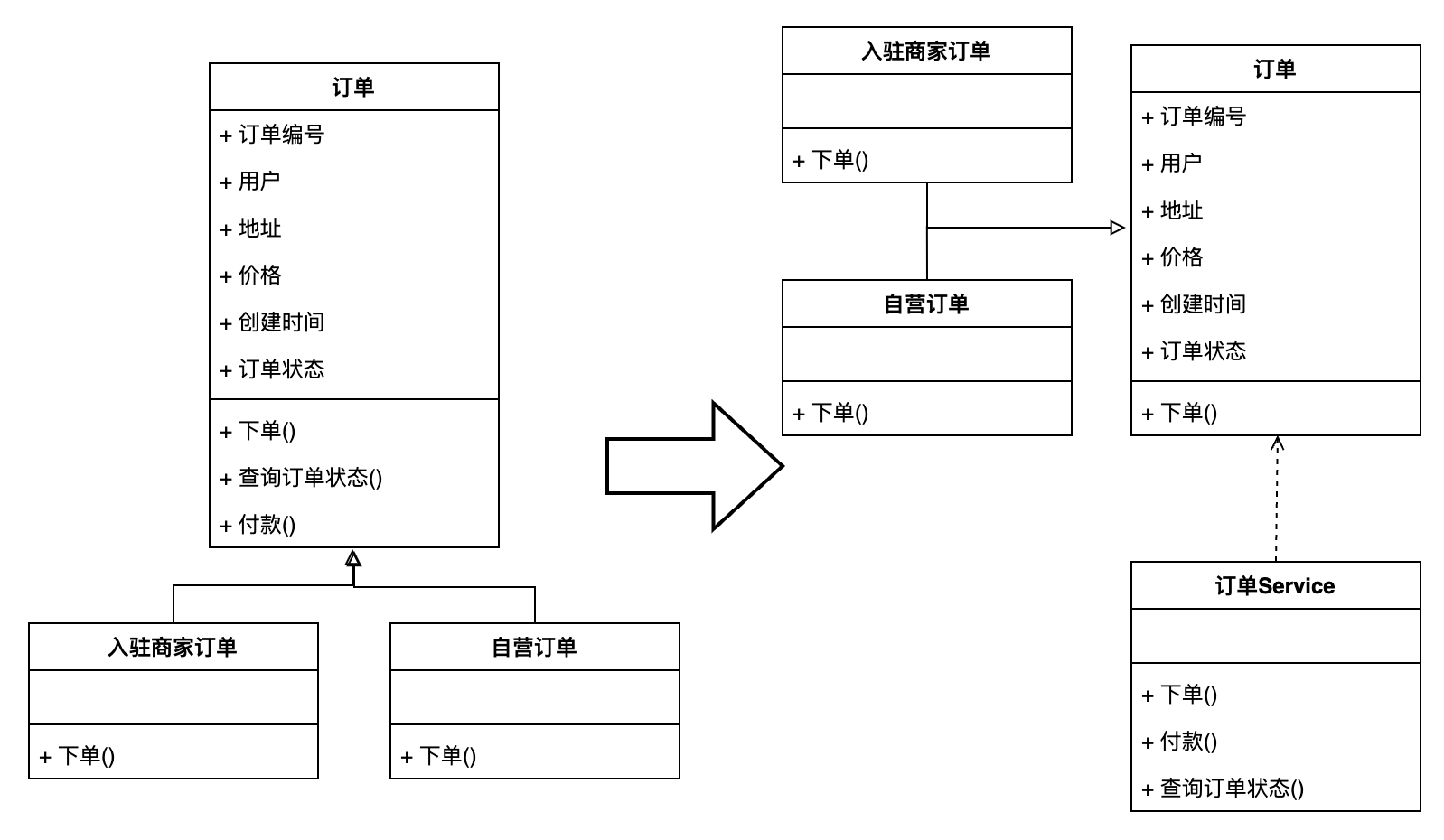
也就是僅將需要封裝的下單邏輯放到了“入駐商家訂單”、“自營訂單”中,而付款、查詢訂單狀態邏輯則仍然放到Service進行主要處理。
事實上,需要封裝的這個概念也是比較模糊的,但是基本上可以參考:
- 存在繼承、多態關系:例如訂單與自營訂單
- 需要編碼轉換:例如根據數值返回對應的枚舉對象
- 需要體現出必要領域關聯性:例如訂單與訂單明細的關系。
最后
盡管經過了合理的分析后,得到的結論是應該根據特性進行貧血和充血模型的混用。但是在實際企業中,如何評判哪些方法可以放到模型中的這個標準是相對模糊的。也就是說更多的還是需要依靠架構設計、開發的個人能力、代碼review,而上述三個都對小團隊、年輕團隊不是很友好。所以我認為如果為了提高下限,則使用貧血模型更加穩妥。