如何保存和恢復TensorFlow訓練的模型
如果深層神經網絡模型的復雜度非常高的話,那么訓練它可能需要相當長的一段時間,當然這也取決于你擁有的數據量,運行模型的硬件等等。在大多數情況下,你需要通過保存文件來保障你試驗的穩定性,防止如果中斷(或一個錯誤),你能夠繼續從沒有錯誤的地方開始。
更重要的是,對于任何深度學習的框架,像TensorFlow,在成功的訓練之后,你需要重新使用模型的學習參數來完成對新數據的預測。
在這篇文章中,我們來看一下如何保存和恢復TensorFlow模型,我們在此介紹一些最有用的方法,并提供一些例子。
1. 首先我們將快速介紹TensorFlow模型
TensorFlow的主要功能是通過張量來傳遞其基本數據結構類似于NumPy中的多維數組,而圖表則表示數據計算。它是一個符號庫,這意味著定義圖形和張量將僅創建一個模型,而獲取張量的具體值和操作將在會話(session)中執行,會話(session)一種在圖中執行建模操作的機制。會話關閉時,張量的任何具體值都會丟失,這也是運行會話后將模型保存到文件的另一個原因。
通過示例可以幫助我們更容易理解,所以讓我們為二維數據的線性回歸創建一個簡單的TensorFlow模型。
首先,我們將導入我們的庫:
- import tensorflow as tf
- import numpy as np
- import matplotlib.pyplot as plt
- %matplotlib inline
下一步是創建模型。我們將生成一個模型,它將以以下的形式估算二次函數的水平和垂直位移:
- y = (x - h) ^ 2 + v
其中h是水平和v是垂直的變化。
以下是如何生成模型的過程(有關詳細信息,請參閱代碼中的注釋):
- # Clear the current graph in each run, to avoid variable duplication
- tf.reset_default_graph()
- # Create placeholders for the x and y points
- X = tf.placeholder("float")
- Y = tf.placeholder("float")
- # Initialize the two parameters that need to be learned
- h_est = tf.Variable(0.0, name='hor_estimate')
- v_est = tf.Variable(0.0, name='ver_estimate')
- # y_est holds the estimated values on y-axis
- y_est = tf.square(X - h_est) + v_est
- # Define a cost function as the squared distance between Y and y_est
- cost = (tf.pow(Y - y_est, 2))
- # The training operation for minimizing the cost function. The
- # learning rate is 0.001
- trainop = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
在創建模型的過程中,我們需要有一個在會話中運行的模型,并且傳遞一些真實的數據。我們生成一些二次數據(Quadratic data),并給他們添加噪聲。
- # Use some values for the horizontal and vertical shift
- h = 1
- v = -2
- # Generate training data with noise
- x_train = np.linspace(-2,4,201)
- noise = np.random.randn(*x_train.shape) * 0.4
- y_train = (x_train - h) ** 2 + v + noise
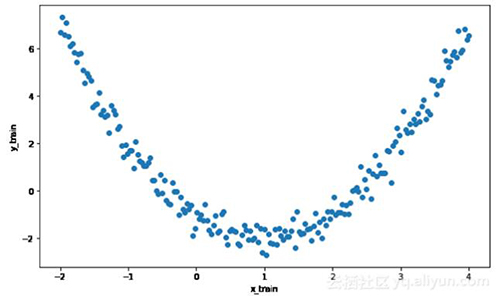
- # Visualize the data
- plt.rcParams['figure.figsize'] = (10, 6)
- plt.scatter(x_train, y_train)
- plt.xlabel('x_train')
- plt.ylabel('y_train')
2. The Saver class
Saver類是TensorFlow庫提供的類,它是保存圖形結構和變量的***方法。
(1) 保存模型
在以下幾行代碼中,我們定義一個Saver對象,并在train_graph()函數中,經過100次迭代的方法最小化成本函數。然后,在每次迭代中以及優化完成后,將模型保存到磁盤。每個保存在磁盤上創建二進制文件被稱為“檢查點”。
- # Create a Saver object
- saver = tf.train.Saver()
- init = tf.global_variables_initializer()
- # Run a session. Go through 100 iterations to minimize the cost
- def train_graph():
- with tf.Session() as sess:
- sess.run(init)
- for i in range(100):
- for (x, y) in zip(x_train, y_train):
- # Feed actual data to the train operation
- sess.run(trainop, feed_dict={X: x, Y: y})
- # Create a checkpoint in every iteration
- saver.save(sess, 'model_iter', global_step=i)
- # Save the final model
- saver.save(sess, 'model_final')
- h_ = sess.run(h_est)
- v_ = sess.run(v_est)
- return h_, v_
現在讓我們用上述功能訓練模型,并打印出訓練的參數。
- result = train_graph()
- print("h_est = %.2f, v_est = %.2f" % result)
- $ python tf_save.py
- h_est = 1.01, v_est = -1.96
Okay,參數是非常準確的。如果我們檢查我們的文件系統,***4次迭代中保存有文件以及最終的模型。
保存模型時,你會注意到需要4種類型的文件才能保存:
- “.meta”文件:包含圖形結構。
- “.data”文件:包含變量的值。
- “.index”文件:標識檢查點。
- “checkpoint”文件:具有最近檢查點列表的協議緩沖區。

圖1:檢查點文件保存到磁盤
調用tf.train.Saver()方法,如上所示,將所有變量保存到一個文件。通過將它們作為參數,表情通過列表或dict傳遞來保存變量的子集,例如:tf.train.Saver({‘hor_estimate’: h_est})。
Saver構造函數的一些其他有用的參數,也可以控制整個過程,它們是:
- max_to_keep:最多保留的檢查點數。
- keep_checkpoint_every_n_hours:保存檢查點的時間間隔。如果你想要了解更多信息,請查看官方文檔的Saver類,它提供了其它有用的信息,你可以探索查看。
- Restoring Models
恢復TensorFlow模型時要做的***件事就是將圖形結構從“.meta”文件加載到當前圖形中。
- tf.reset_default_graph()
- imported_meta = tf.train.import_meta_graph("model_final.meta")
也可以使用以下命令探索當前圖形tf.get_default_graph()。接著第二步是加載變量的值。提醒:值僅存在于會話(session)中。
- with tf.Session() as sess:
- imported_meta.restore(sess, tf.train.latest_checkpoint('./'))
- h_est2 = sess.run('hor_estimate:0')
- v_est2 = sess.run('ver_estimate:0')
- print("h_est: %.2f, v_est: %.2f" % (h_est2, v_est2))
- $ python tf_restore.py
- INFO:tensorflow:Restoring parameters from ./model_final
- h_est: 1.01, v_est: -1.96
如前面所提到的,這種方法只保存圖形結構和變量,這意味著通過占位符“X”和“Y”輸入的訓練數據不會被保存。
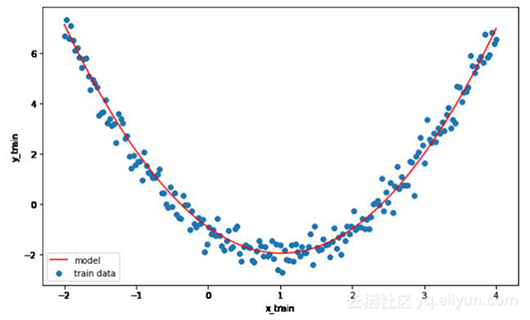
無論如何,在這個例子中,我們將使用我們定義的訓練數據tf,并且可視化模型擬合。
- plt.scatter(x_train, y_train, label='train data')
- plt.plot(x_train, (x_train - h_est2) ** 2 + v_est2, color='red', label='model')
- plt.xlabel('x_train')
- plt.ylabel('y_train')
- plt.legend()
Saver這個類允許使用一個簡單的方法來保存和恢復你的TensorFlow模型(圖形和變量)到/從文件,并保留你工作中的多個檢查點,這可能是有用的,它可以幫助你的模型在訓練過程中進行微調。
4. SavedModel格式(Format)
在TensorFlow中保存和恢復模型的一種新方法是使用SavedModel,Builder和loader功能。這個方法實際上是Saver提供的更高級別的序列化,它更適合于商業目的。
雖然這種SavedModel方法似乎不被開發人員完全接受,但它的創作者指出:它顯然是未來。與Saver主要關注變量的類相比,SavedModel嘗試將一些有用的功能包含在一個包中,例如Signatures:允許保存具有一組輸入和輸出的圖形,Assets:包含初始化中使用的外部文件。
(1) 使用SavedModel Builder保存模型
接下來我們嘗試使用SavedModelBuilder類完成模型的保存。在我們的示例中,我們不使用任何符號,但也足以說明該過程。
- tf.reset_default_graph()
- # Re-initialize our two variables
- h_est = tf.Variable(h_est2, name='hor_estimate2')
- v_est = tf.Variable(v_est2, name='ver_estimate2')
- # Create a builder
- builder = tf.saved_model.builder.SavedModelBuilder('./SavedModel/')
- # Add graph and variables to builder and save
- with tf.Session() as sess:
- sess.run(h_est.initializer)
- sess.run(v_est.initializer)
- builder.add_meta_graph_and_variables(sess,
- [tf.saved_model.tag_constants.TRAINING],
- signature_def_map=None,
- assets_collection=None)
- builder.save()
- $ python tf_saved_model_builder.py
- INFO:tensorflow:No assets to save.
- INFO:tensorflow:No assets to write.
- INFO:tensorflow:SavedModel written to: b'./SavedModel/saved_model.pb'
運行此代碼時,你會注意到我們的模型已保存到位于“./SavedModel/saved_model.pb”的文件中。
(2) 使用SavedModel Loader程序恢復模型
模型恢復使用tf.saved_model.loader,并且可以恢復會話范圍中保存的變量,符號。
在下面的例子中,我們將加載模型,并打印出我們的兩個系數(h_est和v_est)的數值。數值如預期的那樣,我們的模型已經被成功地恢復了。
- with tf.Session() as sess:
- tf.saved_model.loader.load(sess, [tf.saved_model.tag_constants.TRAINING], './SavedModel/')
- h_est = sess.run('hor_estimate2:0')
- v_est = sess.run('ver_estimate2:0')
- print("h_est: %.2f, v_est: %.2f" % (h_est, v_est))
- $ python tf_saved_model_loader.py
- INFO:tensorflow:Restoring parameters from b'./SavedModel/variables/variables'
- h_est: 1.01, v_est: -1.96
5. 結論
如果你知道你的深度學習網絡的訓練可能會花費很長時間,保存和恢復TensorFlow模型是非常有用的功能。該主題太廣泛,無法在一篇博客文章中詳細介紹。不管怎樣,在這篇文章中我們介紹了兩個工具:Saver和SavedModel builder/loader,并創建一個文件結構,使用簡單的線性回歸來說明實例。希望這些能夠幫助到你訓練出更好的神經網絡模型。