買不起手辦就用AI渲染一個!用網上隨便搜的圖就能合成
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
渲染一個精細到頭發和皮膚褶皺的龍珠3D手辦,有多復雜?

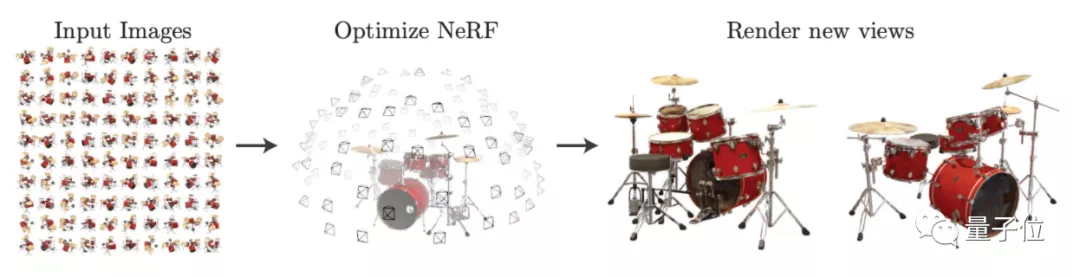
對于經典模型NeRF來說,至少需要同一個相機從特定距離拍攝的100張手辦照片。
但現在,一個新AI模型只需要40張來源不限的網絡圖片,就能把整個手辦渲染出來!

這些照片的拍攝角度、遠近和亮暗都沒有要求,還原出來的圖片卻能做到清晰無偽影:

甚至還能預估材質,并從任意角度重新打光:

這個AI模型名叫NeROIC,是南加州大學和Snap團隊玩出來的新花樣。

有網友見狀狂喜:
不同角度的照片就能渲染3D模型,快進到只用照片來拍電影……

還有網友借機炒了波NFT(手動狗頭)

所以,NeROIC究竟是如何僅憑任意2D輸入,就獲取到物體的3D形狀和性質的呢?
基于NeRF改進,可預測材料光照
介紹這個模型之前,需要先簡單回顧一下NeRF。
NeRF提出了一種名叫神經輻射場(neural radiance field)的方法,利用5D向量函數來表示連續場景,其中5個參數分別用來表示空間點的坐標位置(x,y,z)和視角方向(θ,φ)。
然而,NeRF卻存在一些問題:
- 對輸入圖片的要求較高,必須是同一場景下拍攝的物體照片;
- 無法預測物體的材料屬性,因此無法改變渲染的光照條件。
這次的NeROIC,就針對這兩方面進行了優化:
- 輸入圖片的場景不限,可以是物體的任意背景照片,甚至是網絡圖片;
- 可以預測材料屬性,在渲染時可以改變物體表面光照效果(可以打光)。
它主要由2個網絡構成,包括深度提取網絡(a)和渲染網絡(c)。
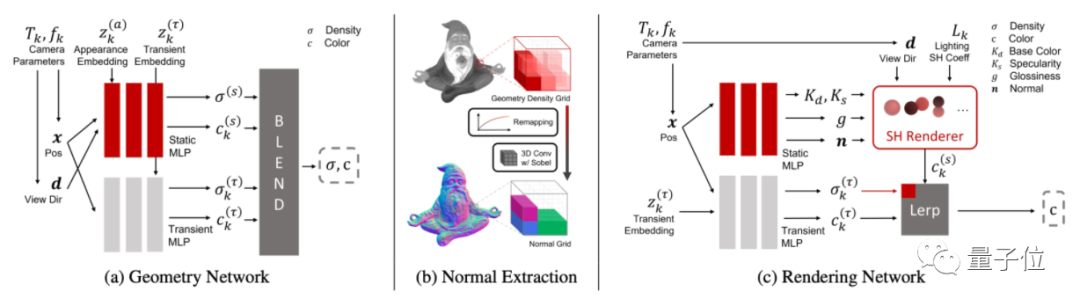
首先是深度提取網絡,用于提取物體的各種參數。
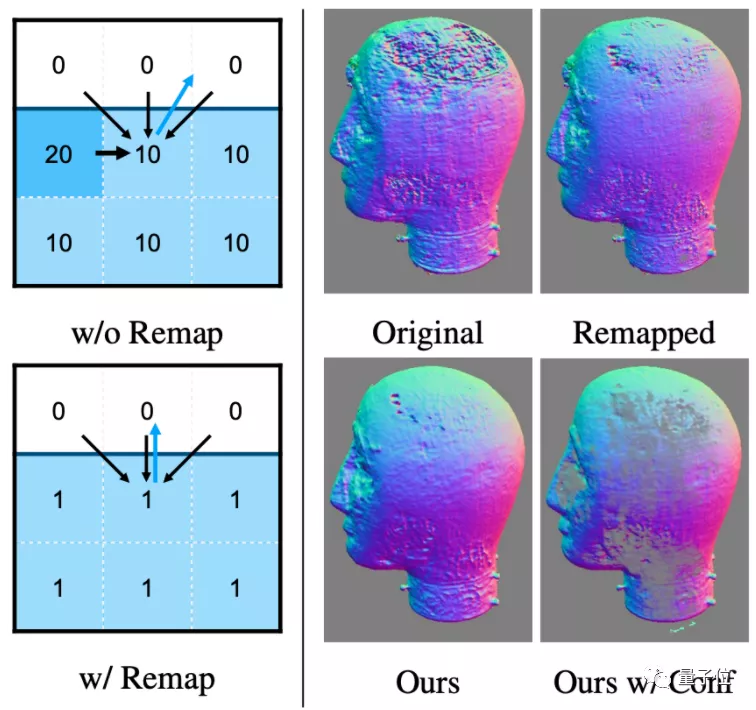
為了做到輸入場景不限,需要先讓AI學會從不同背景中摳圖,但由于AI對相機的位置估計得不準確,摳出來的圖片總是存在下面這樣的偽影(圖左):

因此,深度提取網絡引入了相機參數,讓AI學習如何估計相機的位置,也就是估算圖片中的網友是從哪個角度拍攝、距離有多遠,摳出來的圖片接近真實效果(GT):

同時,設計了一種估計物體表面法線的新算法,在保留關鍵細節的同時,也消除了幾何噪聲的影響(法線即模型表面的紋路,隨光線條件變化發生變化,從而影響光照渲染效果):
最后是渲染網絡,用提取的參數來渲染出3D物體的效果。
具體來說,論文提出了一種將顏色預測、神經網絡與參數模型結合的方法,用于計算顏色、預測最終法線等。
其中,NeROIC的實現框架用PyTorch搭建,訓練時用了4張英偉達的Tesla V100顯卡。
訓練時,深度提取網絡需要跑6~13小時,渲染網絡則跑2~4小時。
用網絡圖片就能渲染3D模型
至于訓練NeROIC采用的數據集,則主要有三部分:
來源于互聯網(部分商品來源于網購平臺,即亞馬遜和淘寶)、NeRD、以及作者自己拍攝的(牛奶、電視、模型)圖像,平均每個物體收集40張照片。
那么,這樣的模型效果究竟如何呢?
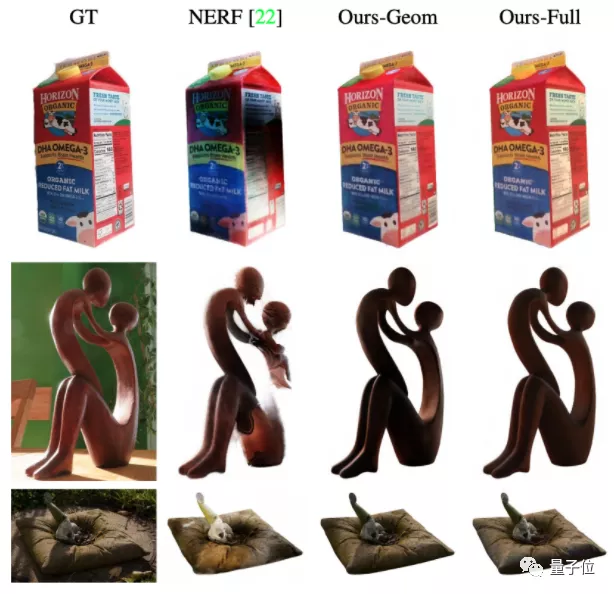
論文先是將NeROIC與NeRF進行了對比。
從直觀效果來看,無論是物體渲染細節還是清晰度,NeROIC都要比NeRF更好。
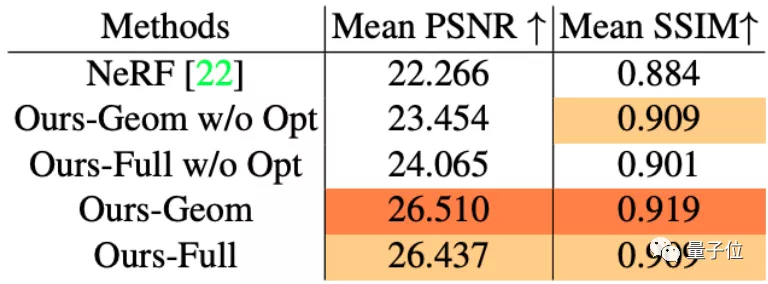
具體到峰值信噪比(PSNR)和結構相似性(SSIM)來看,深度提取網絡的“摳圖”技術都挺不錯,相較NeRF做得更好:
同時,論文也在更多場景中測試了渲染模型的效果,事實證明不會出現偽影等情況:

還能產生新角度,而且重新打光的效果也不錯,例如這是在室外場景:

室內場景的打光又是另一種效果:

作者們還嘗試將照片數量減少到20張甚至10張,對NeRF和NeROIC進行訓練。
結果顯示,即使是數據集不足的情況下,NeROIC的效果依舊比NeRF更好。

不過也有網友表示,作者沒給出玻璃或是半透明材質的渲染效果:

對AI來說,重建透明或半透明物體確實也確實是比較復雜的任務,可以等代碼出來后嘗試一下效果。
據作者表示,代碼目前還在準備中。網友調侃:“可能中頂會、或者在演講之后就會放出”。
一作清華校友

論文一作匡正非,目前在南加州大學(University of Southern California)讀博,導師是計算機圖形學領域知名華人教授黎顥。
他本科畢業于清華計算機系,曾經在胡事民教授的計圖團隊中擔任助理研究員。
這篇文章是他在Snap公司實習期間做出來的,其余作者全部來自Snap團隊。

以后或許只需要幾張網友“賣家秀”,就真能在家搞VR云試用了。

論文地址:
https://arxiv.org/abs/2201.02533
項目地址:
https://formyfamily.github.io/NeROIC/