InnoDB原理篇:為什么使用索引會變快?
前言
大家好,我是阿星。
本文就接上一篇文章【??InnoDB原理篇:聊聊數據頁變成索引這件事??】來聊聊索引。
建議看完上篇文章再看本篇,食用效果最佳。
索引
假設給你一本非常厚的《Java編程思想》閱讀,沒有目錄,你想快速找到某一個章節的知識點,那估計得找一會了,如果有目錄就不一樣。
索引其實就是為了提高數據查詢的效率,就像書的目錄一樣,對于數據庫的表而言,索引其實就是它的目錄。
二叉搜索樹
索引的實現種類繁多,比如常見的有序數組、哈希表、樹等,不同的結構都有自己的適用場景和局限性,在數據庫領域中,樹結構是被廣泛使用。
我們先從最基本的二叉搜索樹說起。
二叉搜索樹的特點是:父節點左子樹所有結點的值小于父節點的值,右子樹所有結點的值大于父節點的值,如下圖所示:
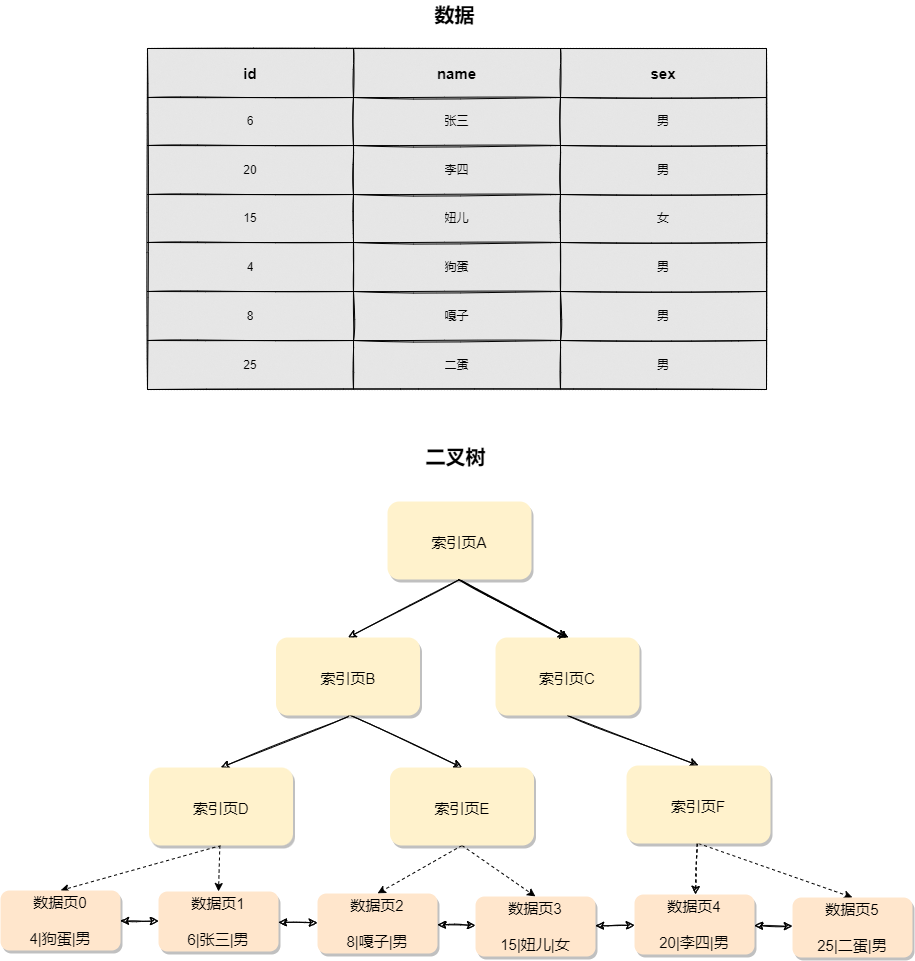
如果要查id=4的數據,按照圖中的搜索順序是索引頁A -> 索引頁B -> 索引頁D -> 數據頁0,時間復雜度是O(log(N))。

也就是說,搜索速度與高度有關,樹越高,性能越差,假設100萬行的表,使用二叉樹來存儲,樹高20,磁盤每次隨機讀一個數據塊需要10ms左右,單獨訪問一個行可能需要20個10ms的時間,這個查詢可真夠慢的。
N叉搜索樹
為了減少磁盤隨機讀IO,就必須控制好樹的高度,那就不應該使用二叉樹,而是使用N叉樹,這里的N代表數據塊的大小。
也就說,你一個索引頁存儲的數據越多,樹會越矮,InnoDB中就使用了B+樹來實現索引。
以InnoDB的整數字段建立索引為例。
一個頁默認16kb,整數(bigint)字段的長度為8B,另外還跟著6B的指向其子樹的指針,這意味著一個索引頁可以存儲接近1200條數據(16kb/14B ≈ 1170)。
如果這顆B+樹高度為4,就可以存1200的3次方的值,差不多17億條數據。

考慮到樹根節點總是在內存中的,樹的第二層很大概率也在內存中,所以一次搜索最多只需要訪問2次磁盤IO。

可能小伙伴會有疑問,為什么樹的根節點與樹的第二層會在內存,第三層、第四層卻沒在?
道理很簡單,看下數據大小就清楚了。
- 樹的根節點就是16kb的索引頁,內存完全可以放下,里面存儲1200條索引目錄
- 樹的第二層總共是1200個索引頁,1200 * 16KB = 20M內存依然放得下的
- 樹的第三層1200 * 1200 = 144w頁,144w * 16kB = 23G放內存就不合適了
- 樹的第四層就是數據頁了,屬于完整數據了,更不可能全部加載進內存了

最后再感受下索引搜索的流程。
假設1億數據量的表,根據主鍵id建立了B+樹索引,現在搜索id=2699的數據,流程如下:
- 內存中直接獲取樹根索引頁,對樹根索引頁內的目錄進行二分查找,定位到第二層的索引頁
- 內存中直接獲取第二層的索引頁,對索引頁內的目錄進行二分查找,定位到第三層的索引頁
- 從磁盤加載第三層的索引頁到內存中,對索引頁內的目錄進行二分查找,定位到第四層數據頁
- 從磁盤加載第四層的數據頁到內存中,數據頁變成緩存頁,對緩存頁中的目錄進行二分查找,定位到具體的行數據