













五秒手機貓片也能重建貓咪3D模型,Meta提出新算法為變形物體建模
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
眾所周知,貓是一種液體。
這也給CVer帶來了極大的煩惱:如何從2D視頻中準確地對一只貓進行3D重建?
在很多情況下,3D重建模型得到的真是一灘液體。

而最近Meta團隊提出的BANMo(Builder of Animatable 3D Neural Models),實現了對貓精確的3D重建。

這種方法既不需要專門的傳感器,也不需要預定義的模板形狀,甚至只用你平時給貓咪拍攝的休閑小視頻,就可以做3D重建。
這篇關于BANMo的論文最近被CVPR 2022接收,作者已經將相關代碼開源。
原理
從單目視頻中重建自由移動的非剛性物體(例如貓),是一項高度約束不足的任務,會面臨三大挑戰:
如何在規范空間中表示目標模型的3D外觀和變形;
如何找到規范空間與每幀之間的映射關系;
如何找到圖像中視角、光線變化、目標變形之間的2D對應關系。
之前像NRSfM、NeRF等方法,要么是無法精確重建表面,要么對拍攝視角與物體的剛性有要求。
針對這些問題,BANMo使用神經混合皮膚,提供了一種限制目標物體變形空間的方法。
BANMo可以實現高保真3D幾何重建。與動態NeRF方法相比,BANMo中使用神經混合皮膚可以更好地處理相機參數未知情況下的姿勢變化和變形。
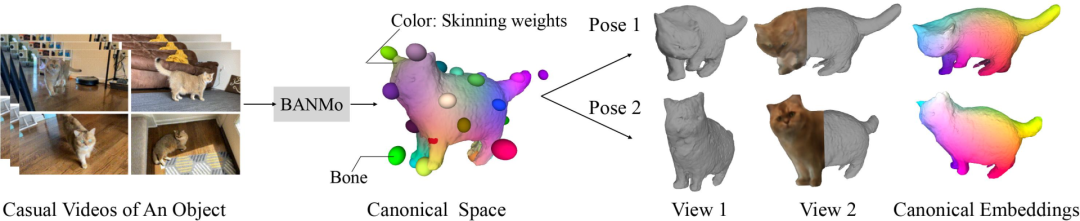
總的來說,BANMo的關鍵在于合并了三種技術:
(1)利用鉸接骨架和混合皮膚的經典可變形形狀模型;
(2)適合基于梯度優化的神經輻射場NeRF;
(3)在像素和鉸接模型之間產生對應關系的規范嵌入。
大致方法如下圖所示:
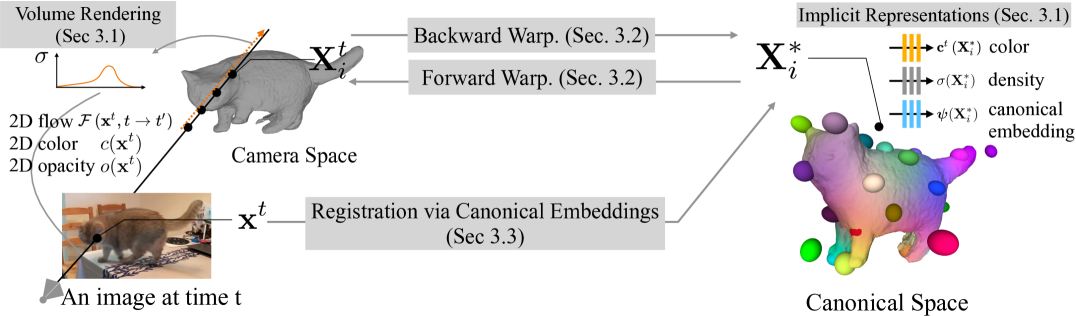
根據可微分的卷渲染框架(3.1)優化一組形狀和變形參數,用像素顏色、輪廓、光流和高階特征描述詞來描述視頻觀測結果。
使用神經混合皮膚模型(3.2)在相機空間和規范空間之間轉換3D點。
聯合優化隱式規范嵌入(3.3),在視頻中注冊像素。
從整體架構上來看,BANMo分為三塊:
1、形狀和外觀模型
這部分用多層感知器(MLP)網絡預測顏色、密度等屬性,并學習相機視角變換和處理大變形。
2、神經混合皮膚變形模型
這是基于近似關節身體運動的神經混合皮膚模型,將物體的扭曲作為剛體變換的組合,每個變換都是可微和可逆的。
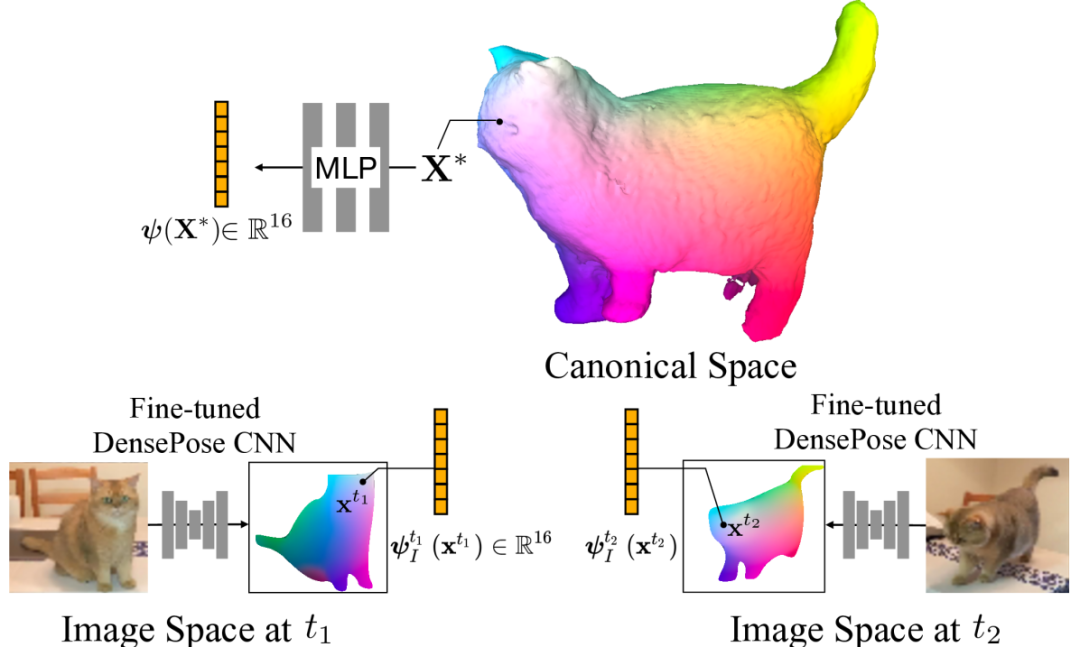
3、規范嵌入像素注冊
嵌入對規范空間中3D點的語義信息進行編碼,在這里作者優化了一個隱式函數,從與2D DensePose CSE嵌入相匹配的3D規范點生成規范嵌入。
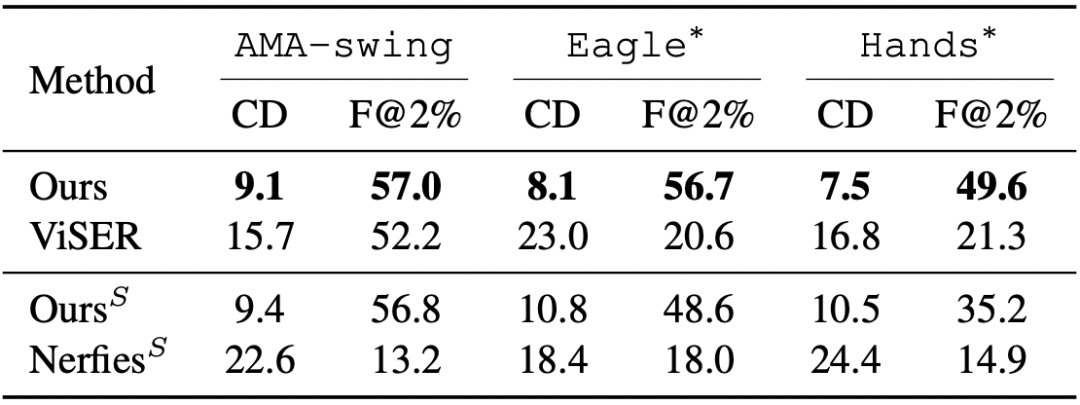
在真實和合成數據集上,BANMo在重建穿衣服的人類和動物方面表現出強大的性能。
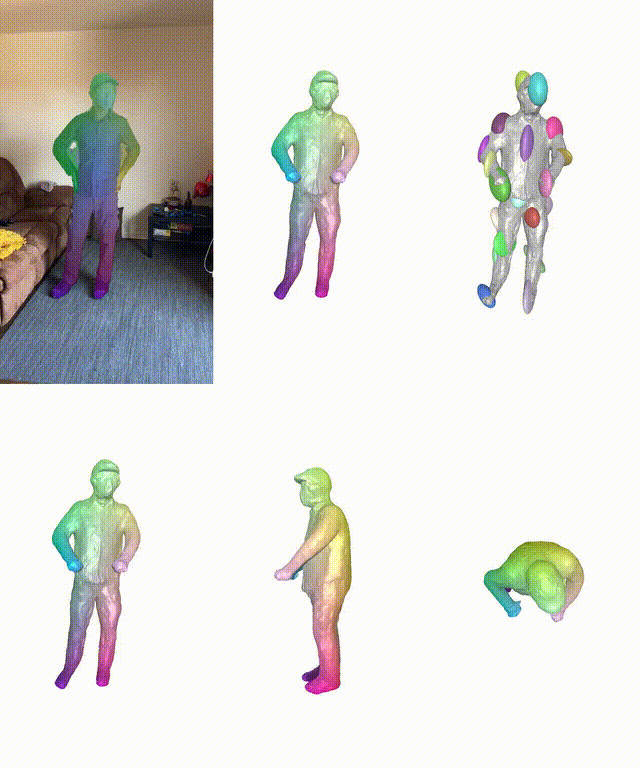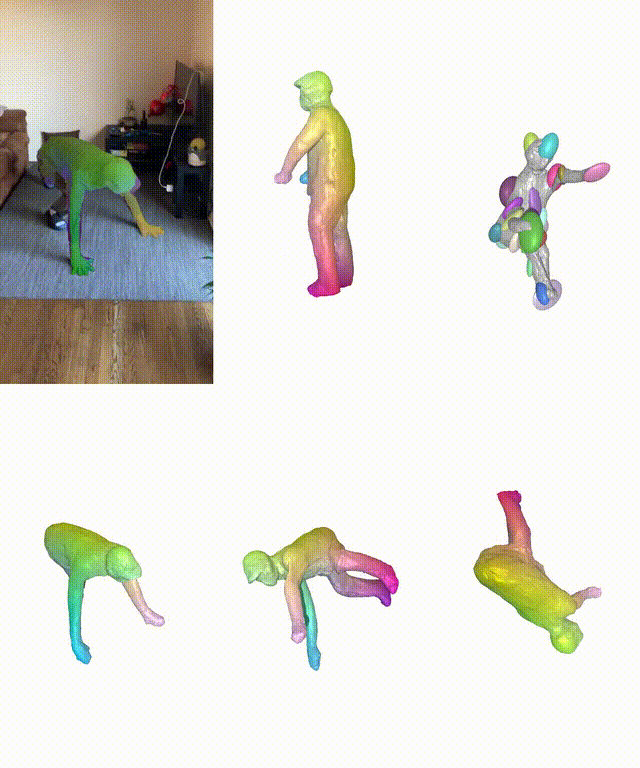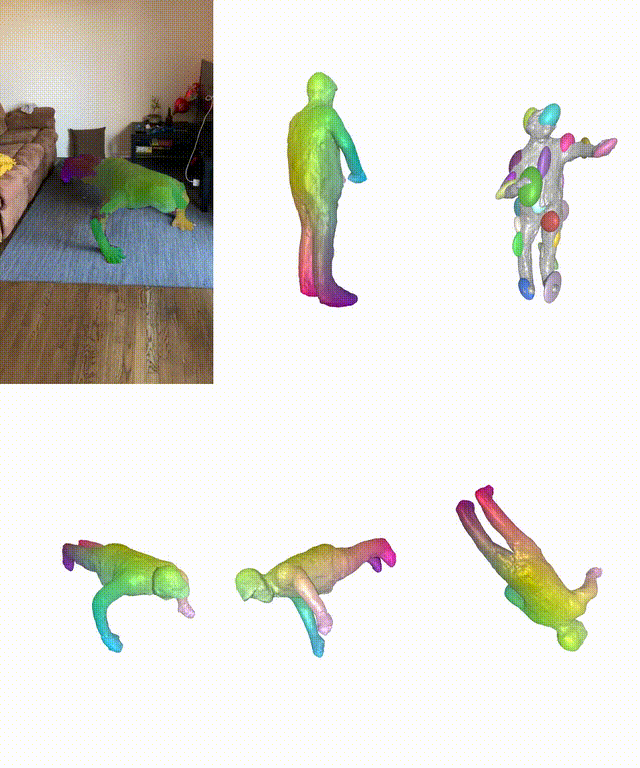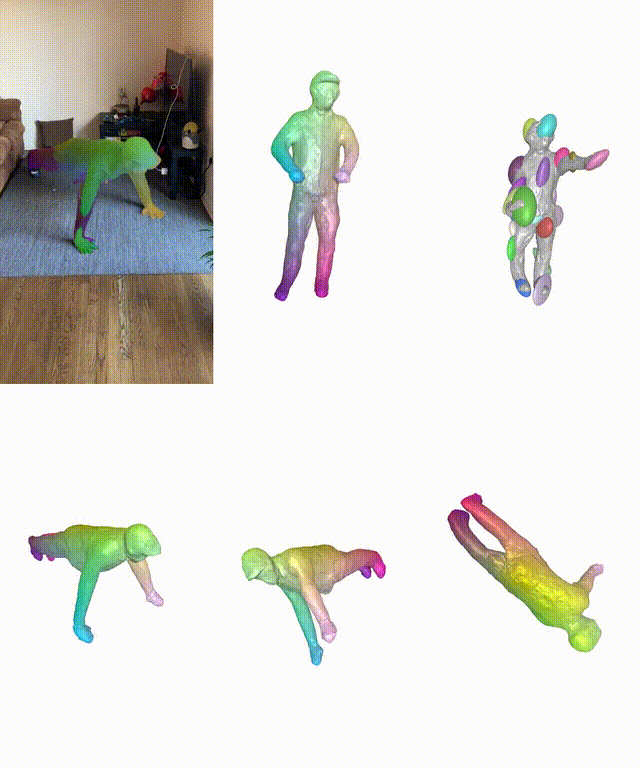
作者簡介
這篇第一作者是楊庚山,畢業于西安交通大學,現在在CMU攻讀博士學位,研究動態結構的3D重建算法。

BANMo這篇論文是他在Meta實習期間完成。
從2019年至今,他共有4篇一作論文被NeurIPS接收、4篇一作論文被CVPR接收。




























