MegaSynth:用70萬合成數據突破3D場景重建瓶頸,PSNR提升1.8dB!
1. 一眼概覽
MegaSynth 提出了一種基于非語義合成數據的大規模 3D 場景重建方法,生成 70 萬個合成場景數據集,訓練大型重建模型(LRMs),相比使用真實數據訓練的模型,PSNR 提升 1.2~1.8 dB,顯著增強 3D 場景重建的廣覆蓋能力。
2. 核心問題
當前 3D 場景重建方法受限于:
- 數據規模受限:現有真實數據集 DL3DV 僅 10K 場景,遠小于物體級數據集(如 Objaverse 80 萬個實例)。
- 數據分布不理想:現有數據集多為人工采集,難以確保場景多樣性,攝像機運動范圍受限,且可能包含噪聲和不精確標注。
- 計算成本高昂:現有優化方法(如 3DGS)計算成本高,推理速度慢,難以應用于大規模場景。
MegaSynth 通過合成數據突破數據瓶頸,使 3D 場景重建更高效、精準,并能泛化至真實數據。
3. 技術亮點
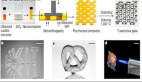
大規模非語義數據生成:提出 MegaSynth 數據集,通過程序化生成 70 萬個場景,無需建模語義信息(如物體屬性和布局),避免語義復雜性帶來的計算開銷。
合成數據+真實數據混合訓練:通過 MegaSynth 預訓練 + 真實數據微調,提高模型泛化能力,實現 1.2~1.8 dB PSNR 提升。
新型 LRM 訓練策略:基于 GS-LRM 和 Long-LRM 兩種模型,利用合成數據進行高效重建,使模型性能與僅用真實數據訓練的模型相當。
4. 方法框架
MegaSynth 通過以下步驟完成 3D 場景重建:
1)合成數據生成:
? 場景布局:生成 3D 立方體空間,隨機分布幾何體(如立方體、球體、圓柱等)。
? 幾何和紋理生成:隨機組合幾何形狀并添加高度場擾動。
? 光照建模:使用環境光、太陽光和發光物體生成多樣化光照條件。
2)數據訓練策略:
? 訓練 GS-LRM 和 Long-LRM,分別基于 Transformer 和 Mamba 架構。
? 混合訓練:先用 MegaSynth 預訓練,再用 DL3DV 真實數據微調,以增強泛化能力。
3) 損失優化:
? 渲染損失(Limg):基于 MSE 誤差和感知損失優化 3D 紋理。
? 幾何損失(Lloc):基于合成數據提供的精準幾何信息,優化 3D 高斯中心位置,提高幾何精度。
5. 實驗結果速覽
? 數據集:
a.訓練:MegaSynth(70 萬場景)+ DL3DV(7K 場景)
b.測試:DL3DV、Hypersim(高真實感渲染)、MipNeRF360、Tanks & Temples(真實世界數據)
? 關鍵實驗結論:
a.訓練包含 MegaSynth 數據的模型在 所有測試數據集 上均優于僅用真實數據訓練的模型,特別是在 Hypersim 和 MipNeRF360 這樣的跨域數據集上提升更明顯。
b.LRMs 僅用 MegaSynth 訓練,性能接近于僅用真實數據訓練的模型,表明 3D 場景重建的本質是低層幾何建模,對語義信息的依賴較小。
6. 實用價值與應用
MegaSynth 及其訓練方法在多個領域有潛在應用:
? 自動駕駛:提升激光雷達與視覺融合的 3D 場景建模精度。
? 機器人導航:增強環境感知,提高路徑規劃可靠性。
? 增強現實(AR)與虛擬現實(VR):支持高質量 3D 資產生成和交互式虛擬場景建模。
? 城市建模與測繪:基于大規模圖像數據進行高精度 3D 重建,提高城市規劃與測繪效率。
7. 開放問題
1)合成數據的泛化性:MegaSynth 在多種數據集上表現良好,但在 超大規模室外場景 或 極端環境光照 下,是否仍能維持高性能?
2)與其他生成式方法的結合:是否可以結合擴散模型或神經輻射場(NeRF),進一步優化數據生成質量?
3) 數據合成策略優化:當前 MegaSynth 采用 非語義建模,如果引入一定的高層語義控制(如物體語義標簽),是否能進一步提升泛化能力?