DeepMind祖師帶出了AI徒弟,用「傳授」而非「訓練」教AI尋寶
?最近,DeepMind又在強化學習領域整了個新活。
用通俗的中文來闡述,DeepMind研究者認為人類獲取知識技能,更多來自于「傳授」而非「訓練」。
也就是說,這個全新智能體可以通過觀察單個人類演示來快速學習新行為,而無需使用人工數據進行預訓練。

日后你惹出禍來,不把為師說出來就行
文化傳授是一種全領域通用的社會技能,它讓智能體之間能以高保真度和召回率實時獲取和使用彼此的經驗信息。
人類社群里,正是基于此技能的積累過程,推動了累積的文化進化,在代際之間擴展了人類的技能、工具和知識。
數千年來,從航海路線到數學,從社會規范到藝術品,人類發現、進化并積累了豐富的文化知識。
定義為有效地將經驗信息從一個人傳遞給另一個人的文化傳授,是人類能力呈指數級增長的積累過程。
大到辛巴達環游七海,小到辦公室同事教你用打印機。這些或顯或隱的經驗性技能,都是以社會性習得的「傳授」、而非像如今「訓練」AI的方式來傳遞的。
AI如果能用這種「傳授」方式獲得知識,不管是人機交互、還是AI自身的智能擴展,效率都將更上層樓。
為此,DeepMind利用深度強化學習技術開發了一種在人工智能體中產生零樣本、高召回率的文化傳授的方法。
經過訓練后,人工智能體可以推斷和回憶專家展示過的指引性知識。這一知識轉移是實時發生的,并且可以概括以前未見過的大量任務。
給AI「傳授」文化
DeepMind研究團隊在程序生成的3D世界中訓練和測試人工智能。
這個3D 世界中包含的彩色球形目標,嵌入在充滿障礙的復雜地形中。行為者必須以正確的順序導航抵達目標,而每種情景里目標的位置都會隨機變化。
由于無法猜測順序,因此單純的探索策略會產生很大的懲罰。作為文化傳授信息的來源,研究團隊生成了一個「專家機器人」腳本,它能始終以正確的順序觸達目標。

對于一個復雜的世界來說,探測任務旨在對跳躍或蹲下的行為以及圍繞垂直障礙物的導航進行清晰的演示。
在所有的探測中,人類的運動模式總是以目標為導向,接近最佳狀態(不會產生任何分數懲罰),但顯然與腳本機器人不同,在最初的幾秒鐘里需要時間來定位,并且不總是兩次采取完全相同的路徑。
智能體(藍色)將跟隨一個專家(紅色)在世界中尋找目標,并跨越不同地形和障礙物,在專家離開之后智能體將繼續完成任務。

專家為智能體

專家為人類
需要注意的是,視頻中的軌跡只是為了讓人類觀察者方便跟蹤,對于智能體來說是不可見的。
方法實現和結果
DeepMind研究團隊通過排除法確定了文化傳授出現所需的、最小數據量級的訓練成分表,這個「入門工具包」被研究者稱為 MEDAL-ADR。

這些訓練成分包括「記憶存儲」 (M)、「專家退出」 (ED)、「對專家的注意力偏見」 (AL) 和「自動域隨機化」 (ADR)。
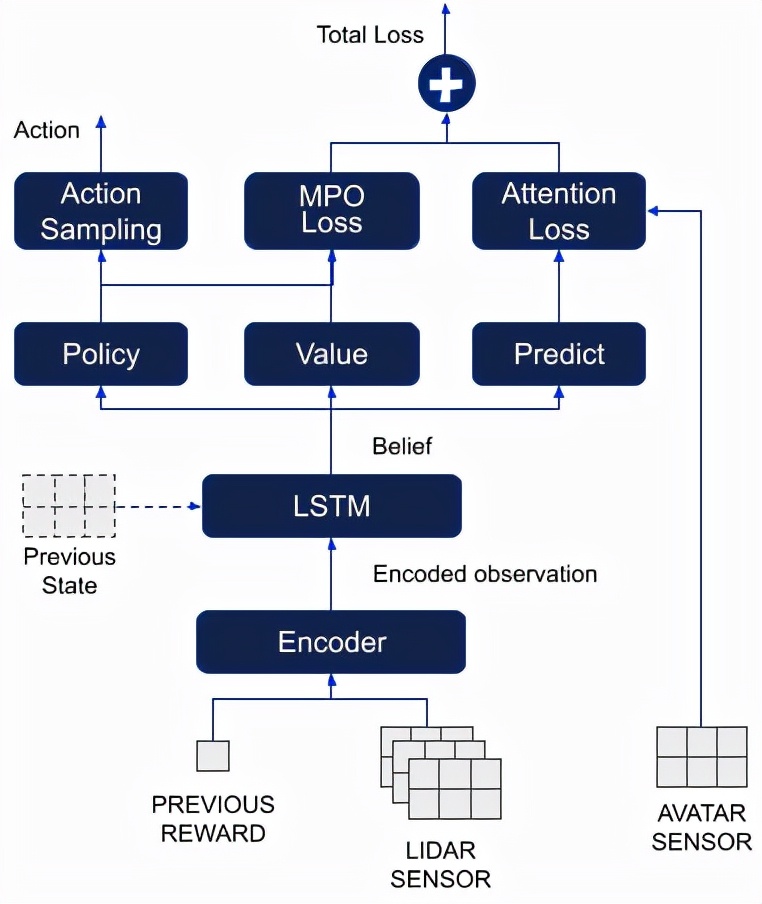
智能體的結構
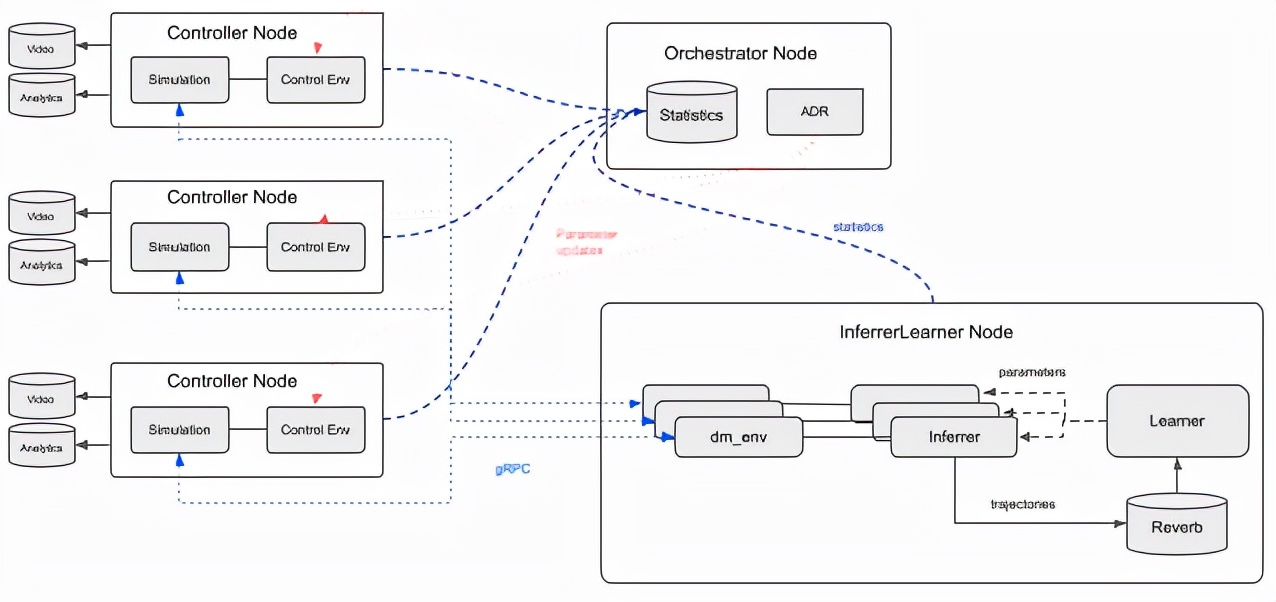
訓練架構
為了更好地感知世界,DeepMind給智能體安裝了一圈激光雷達傳感器。
通過從身上全方位地發出射線,智能體就能get到與障礙物之間的距離了。

在訓練期間,智能體會在某個時間點出現的社會學習行為的進展。

訓練8.6億步:初始探索

訓練15.9億步:模仿

訓練18.2億步:記憶

訓練26.7億步:獨立
泛化:世界空間
世界空間的參數是由地形的大小和顛簸程度以及障礙物的密度決定的。
為了量化空間普適性,DeepMind通過障礙物密度和世界大小的笛卡爾乘積來生成游戲地圖。
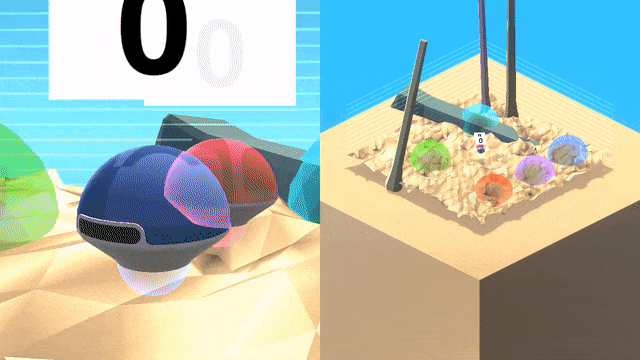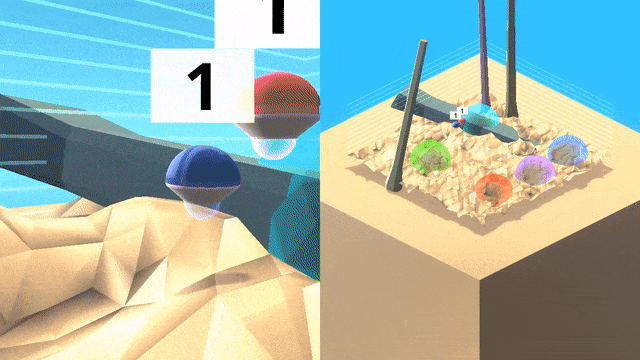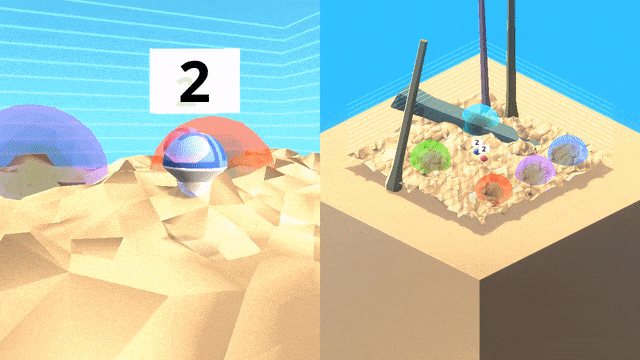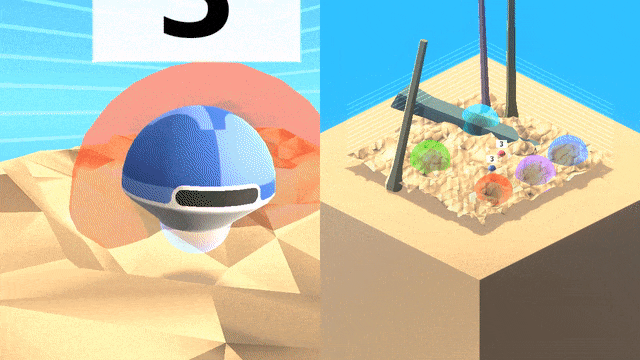
障礙物復雜度: 1.0,地形復雜度: 1.0
泛化:游戲空間
游戲空間是由世界上的目標數量以及它們之間的正確導航路徑所包含的交叉點數量來定義的。
為了量化空間普適性,DeepMind在「N-目標,M-交叉」游戲的規則內生成智能體的任務。

目標球體:5,路徑交叉:4
泛化:專家空間
專家的空間是由專家在世界范圍內采取的速度和行動分布來定義的。
專家可以是腳本化的機器人,也可以是具有更真實和多樣化運動模式的人類玩家。
為了量化空間普適性,DeepMind利用運動速度和動作噪聲的笛卡爾乘積,生成了與專家機器人的行為。

噪聲: 0.5,最大速度: 13.0

噪聲: 0.0,最大速度: 17.0
可以看到,沒有噪聲時機器人會直奔目標,而添加了噪聲之后則會有明顯的「猶豫」。而當專家的速度設置得過快時,智能體到后面就已經要完全追不上了。
經過反復測試,DeepMind開發的智能體在一系列具有挑戰性的任務中都要優于所對比的控制變量,包括最先進的方法ME-AL。
此外,文化傳授在知識轉輸中的泛化程度出人意料地好,并且人工智能體在專家退出后很久還能回憶起示范。
研究團隊觀察人工智能體的「大腦」,發現了負責編碼社會信息和目標狀態的、具有驚人可解釋性的「神經元」。
總而言之,DeepMind開發的流程能訓練出足夠靈活、高召回率、實時文化傳授的智能體,而無需在訓練流水線中使用人工數據。這為文化演進成為開發通用人工智能的算法鋪平了道路。
開發團隊
Lei Zhang是DeepMind為此項目新組建的「通用文化智能團隊」(Cultural General Intelligence Team)的成員。

他是多倫多大學電氣工程博士,本科、碩學位也均在多倫多大學獲得。
在深度強化學習、通用模型、卷積神經網絡、循環神經網絡、分布式訓練、特征探測算法等領域有成就。
曾是OpenAI機械手解決魔方難題團隊的成員,現是DeepMind研究科學家。?