根據文本描述從視頻中摳圖,Transformer:這種跨模態任務我最擅長
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
都說Transformer適合處理多模態任務。
這不,在視頻目標分割領域,就有人用它同時處理文本和視幀,提出了一個結構更簡單、處理速度更快(每秒76幀)的視頻實例分割框架。
這個框架只需一串文本描述,就可以輕松將視頻中的動態目標“摳”出來:
可以實現端到端訓練的它,在基準測試中的多個指標上表現全部優于現有模型。
目前,相關論文已被CVPR 2022接收,研究人員來自以色列理工學院。

主要思路
根據文本描述進行視頻目標分割這一多模態任務(RVOS),需要結合文本推理、視頻理解、實例分割和跟蹤技術。
現有的方法通常依賴復雜的pipeline來解決,很難形成一個端到端的簡便好用的模型。
隨時CV和NLP領域的發展,研究人員意識到,視頻和文本可以同時通過單個多模態Transformer模型進行有效處理。
為此,他們提出了這個叫做MTTR (Multimodal Tracking Transformer)的新架構,將RVOS任務建模為序列(sequence)預測問題。
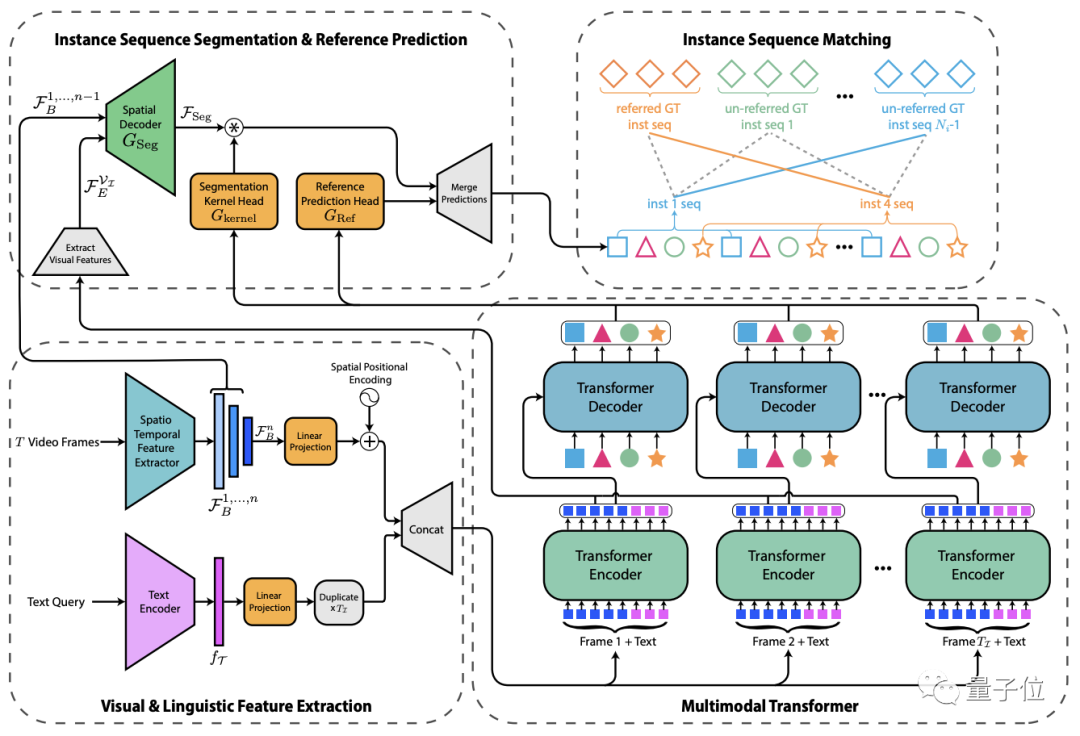
首先,輸入的文本和視頻幀被傳遞給特征編碼器進行特征提取,然后將兩者連接成多模態序列(每幀一個)。
接著,通過多模態Transformer對兩者之間的特征關系進行編碼,并將實例級(instance-level )特征解碼為一組預測序列。
接下來,生成相應的mask和參考預測序列。
最后,將預測序列與基準(ground truth,在有監督學習中通常指代樣本集中的標簽)序列進行匹配,以供訓練過程中的監督或用于在推理過程中生成最終預測。
具體來說,對于Transformer輸出的每個實例序列,系統會生成一個對應的mask序列。
為了實現這一點,作者采用了類似FPN(特征金字塔網絡)的空間解碼器和動態生成的條件卷積核。
而通過一個新穎的文本參考分數函數,該函數基于mask和文本關聯,就可以確定哪個查詢序列與文本描述的對象具有最強的關聯,然后返回其分割序列作為模型的預測。
精度優于所有現有模型
作者在三個相關數據集上對MTTR進行了性能測試:JHMDB-Sentences、 A2D-Sentences和Refer-YouTube-VOS。
前兩個數據集的衡量指標包括IoU(交并比,1表示預測框與真實邊框完全重合)、平均IoU和precision@K(預測正確的相關結果占所有結果的比例)。
結果如下:
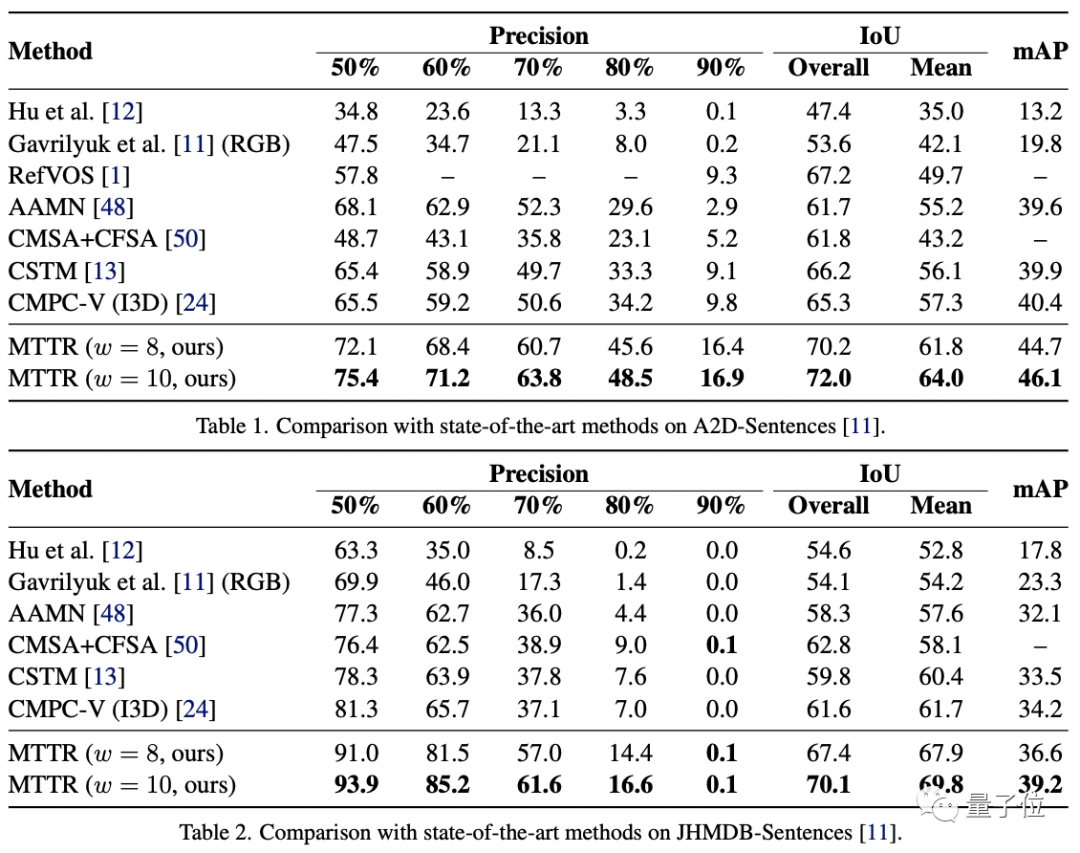
可以看到,MTTR在所有指標上都優于所有現有方法,與SOTA模型相比,還在第一個數據集上提高了4.3的mAP值(平均精度)。
頂配版MTTR則在平均和總體IoU指標上實現了5.7的mAP增益,可以在單個RTX 3090 GPU上實現每秒處理76幀圖像。
MTTR在JHMDBs上的結果表明MTTR也具備良好的泛化能力。
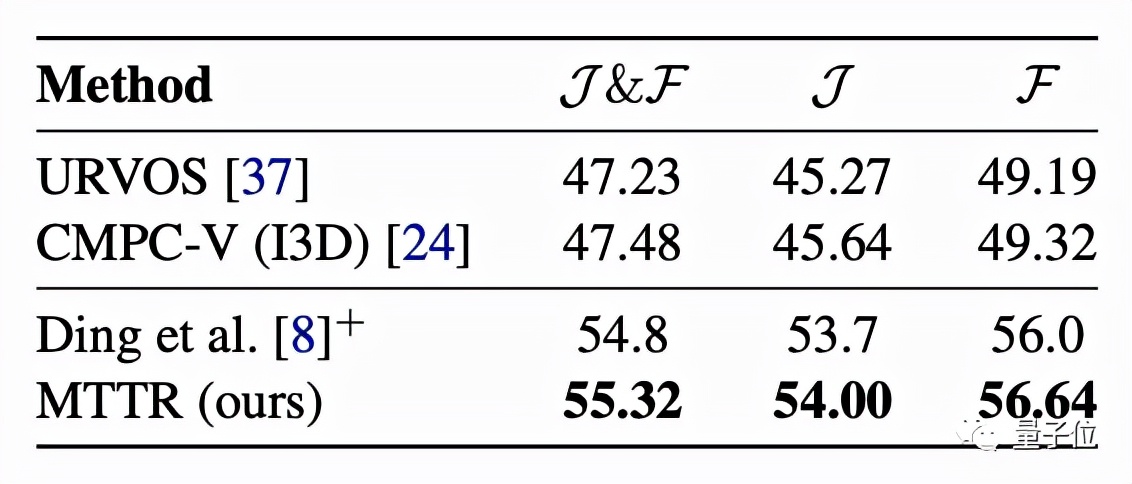
更具挑戰性的Refer-YouTube-VOS數據集的主要評估指標為區域相似性(J)和輪廓精度(F)的平均值。
MTTR在這些指標上全部“險勝”。
一些可視化結果表明,即使在目標對象被類似實例包圍、被遮擋或完全超出畫面等情況下,MTTR都可以成功地跟蹤和分割文本引用的對象。

最后,作者表示,希望更多人通過這項成果看到Transformer在多模態任務上的潛力。
最最后,作者也開放了兩個試玩通道,感興趣的同學可以戳文末鏈接~

△ Colab試玩效果
試玩地址:
??https://huggingface.co/spaces/akhaliq/MTTR??
??https://colab.research.google.com/drive/12p0jpSx3pJNfZk-y_L44yeHZlhsKVra-?usp=sharing??
論文地址:
??https://arxiv.org/abs/2111.14821??
代碼已開源:
??https://github.com/mttr2021/MTTR??