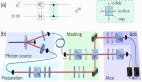
中科大統一輸入過濾框架:首次理論分析可過濾性,支持全數據模態
隨著移動設備算力的提高和對感知數據進行實時分析需求的增長,以移動為中心的人工智能應用愈發普遍。據估計,2022 年將有超過 80% 的商用 IoT 項目將包含 AI 應用。然而多數精度最優的 AI 模型的計算量過大,以至于難以在移動設備上進行高吞吐的推理,甚至當推理任務被卸載到邊緣或云端服務器時其推理效率也難以滿足應用的需求。
冗余的輸入廣泛存在于移動為中心的人工智能應用中,將其過濾是一種有效的提高推理效率的方法。現有工作分別探索過兩類輸入過濾機制:推理跳過和推理重用。其中推理跳過方法旨在跳過那些不會產生有意義輸出的推理計算,例如相冊分類應用可能會在沒有人臉的圖片上運行人臉檢測模型:

智能音箱應用可能將不包含指令的語音上傳至云端進行語音識別:
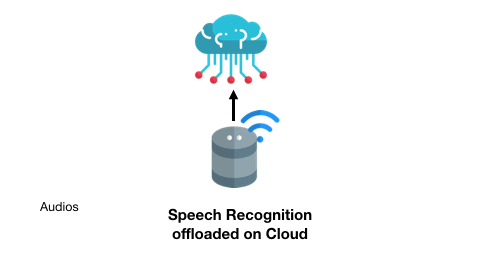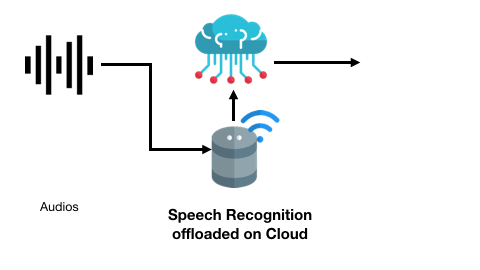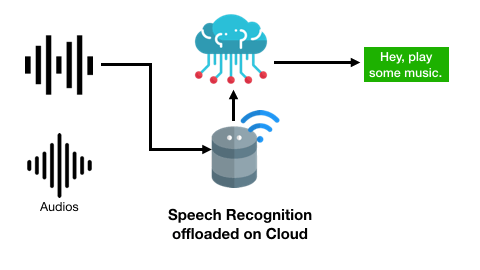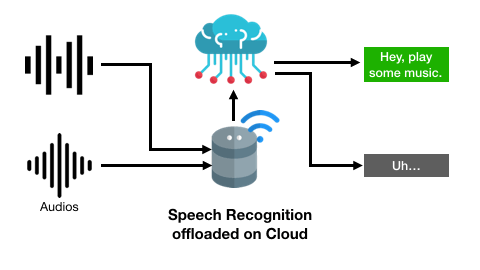
而推理重用方法希望重用已進行過得推理計算結果,從而在新的數據到來時能夠從緩存中更快速地返回結果,例如智能手環上的動作分類模型可能會處理產生相同動作標簽的運動信號:

以及基于無人機和邊緣服務器的交通監控可能會在連續兩個畫面幀中得到不變的車輛計數結果:
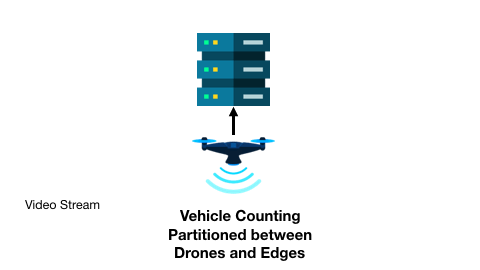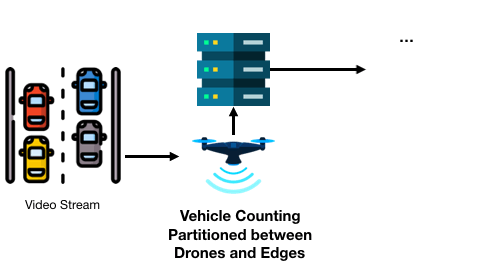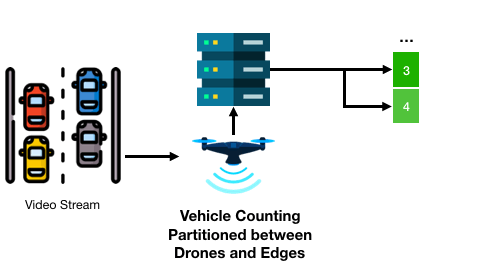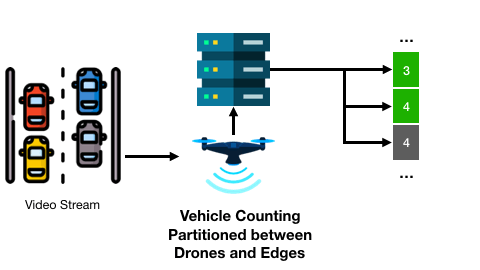
現有工作已針對很多應用設計了有效的輸入過濾方法,然而兩個重要的問題仍未得到解答,并且嚴重影響著輸入過濾方法的應用:
- 推理任務的可過濾性。盡管輸入過濾技術已在很多具體應用中顯示出優化效果,但往往是由主觀的對冗余輸入的觀察而啟發的。如果不能從理論上回答 “哪些推理任務存在輸入過濾的優化機會” 這一問題,則輸入過濾技術的應用難以避免高成本的試錯過程;
- 魯棒的特征可區分性。輸入數據的特征表達直接關系到進行推理跳過和找到可重用推理結果的精度,因此對于輸入過濾的表現有著關鍵影響。現有方法多數依賴手工特征或預訓練深度特征,這些特征在應用過程中沒有魯棒的可區分性,可能完全失去過濾效果。
在 MobiCom 2022 上,中國科學技術大學 LINKE 實驗室針對移動為中心的模型推理場景,提出端到端可學的輸入過濾框架 InFi (INput FIlter)。該工作首次對輸入過濾問題進行了形式化建模,并基于推理模型和輸入過濾器的函數族復雜性對比,在理論層面上對推理任務的可過濾性進行了分析。InFi 框架涵蓋了現有的 SOTA 方法所使用的推理跳過和推理重用機制。基于 InFi 框架,該工作設計并實現了支持六種輸入模態和三種推理任務部署方式的輸入過濾器,在以移動為中心的推理場景中有著廣泛的適用性。在 12 個以移動為中心的人工智能應用上進行的實驗驗證了理論分析結果,并表明 InFi 在適用性、準確性和資源效率方面均優于 SOTA 方法。其中,在一個移動平臺上的視頻分析應用中,相較于原始推理任務,InFi 實現了 8.5 倍的推理吞吐率并節省了 95% 的通信帶寬,同時保持超過 90% 的推理精度。

論文地址:https://yuanmu97.github.io/preprint/InFi_MobiCom22.pdf
項目地址:https://github.com/yuanmu97/infi
可過濾性分析
直觀來說,推理任務的可過濾性指:相較于原始推理任務,能否得到一個低成本、高精度的輸入數據冗余性的預測器。原始的推理任務定義為屬于函數族 H 的模型 h,其將輸入數據映射至推理輸出,例如人臉檢測模型以圖片為輸入,輸出檢測結果(人臉位置的檢測框)。根據推理模型的輸出結果,定義冗余性判斷函數 f_h,其輸出冗余性標簽,例如當人臉位置檢測框輸出為空時,將該次推理計算視為冗余。屬于函數族 G 的輸入過濾器 g 定義為從輸入數據到冗余標簽的映射函數。

假設原始推理模型的目標函數(即提供真實標簽的函數)為 c ,其過濾器的目標函數為
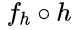
,則可見訓練原始的推理模型和訓練輸入過濾器的區別在于監督標簽的不同:推理預測由原始任務標簽域 Y 監督,而過濾預測由冗余標簽域 Z 監督。那么對于推理任務的可過濾性一個直觀的想法是,如果學習輸入過濾器比學習原始推理模型更簡單,則有潛力得到有效的輸入過濾器。
基于此思路,該工作分析了三類常見推理任務的可過濾性:

分析過程的關鍵在于將輸入過濾器的目標函數與原始推理模型相關聯,從而在兩個學習任務間建立復雜度可比較的橋梁。以分類任務基于置信度進行冗余判別為例,輸入過濾器的目標函數族形式為
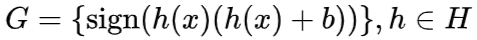
,依此可證明輸入過濾器的函數族的 Rademarcher 復雜度小于等于原始推理模型,進而得到該任務可過濾性的分析結果。
框架設計和實現
以上的可過濾性分析基于將輸入過濾視為一個學習任務得到,因此框架設計需要具有端到端可學性,而不依賴手工特征或預訓練深度特征。同時,框架設計應該統一地支持推理跳過(SKIP)和推理重用(REUSE)機制。該工作基于一個簡潔的思路,即 SKIP 等價于對全零輸入的推理結果的 REUSE,將兩種機制統一到一個框架之中。
框架包含訓練和推理兩個階段。訓練階段通過孿生特征網絡為一對輸入數據抽取特征,計算特征距離后由一個分類網絡得到冗余標簽預測結果。

在推理階段,若采用 SKIP 機制,則將另一個輸入的特征固定為零,退化為基本的分類器,根據預測的冗余性標簽決策是否跳過當前輸入數據;若采用 REUSE 機制,則需要維護一個 “輸入特征 - 推理輸出” 表作為緩存,通過計算當前輸入特征與緩存的輸入特征之間的距離,采用 K - 近鄰方法決策是否重用緩存的推理結果。
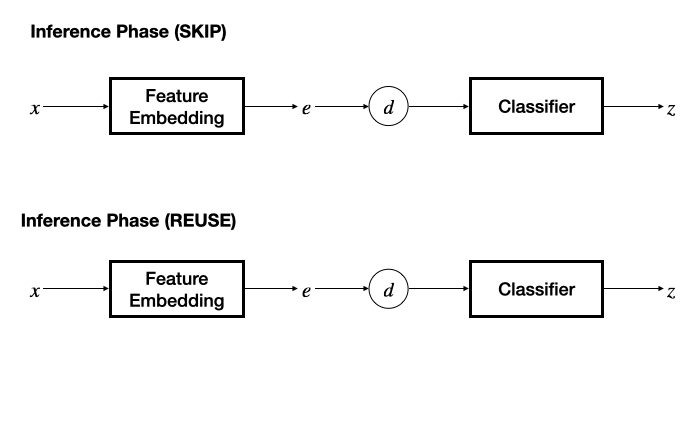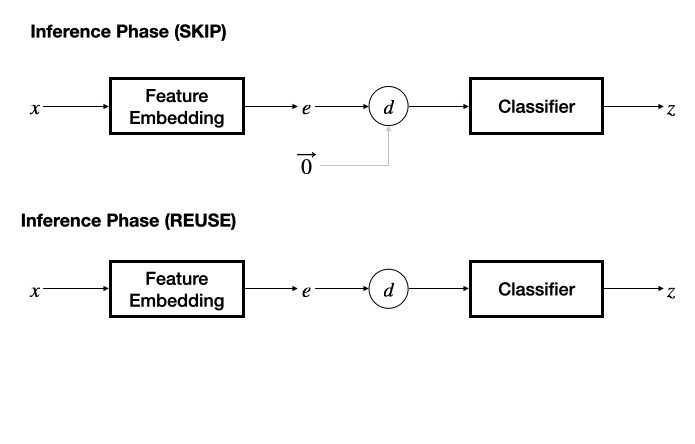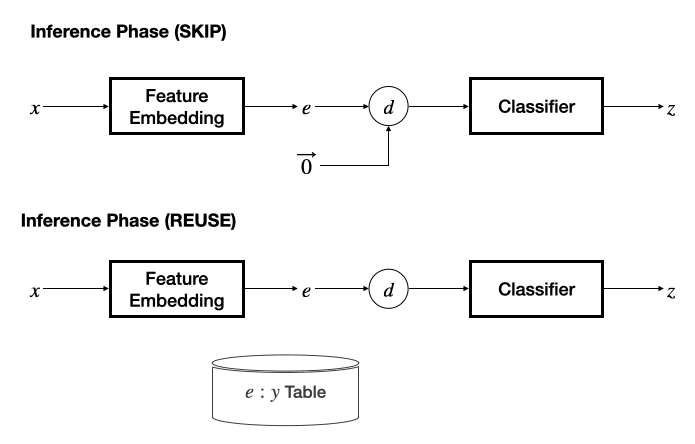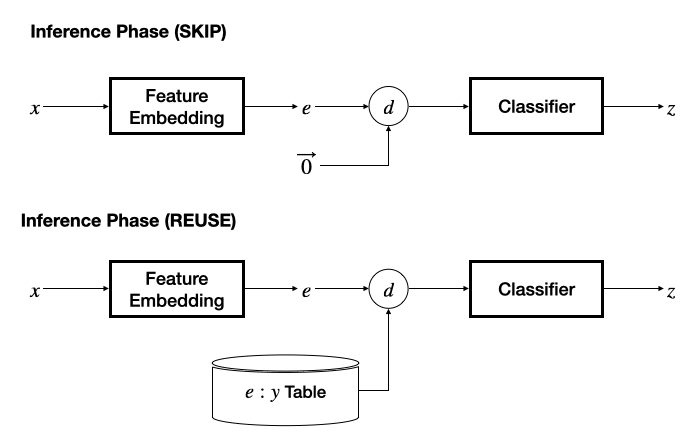
該工作提出了 “模態相關的特征網絡 + 任務無關的分類網絡” 的設計,為文本、圖像、視頻、音頻、感知信號、中間層特征設計了特征抽取網絡,并能夠很容易地擴展至更多數據模態,分類器網絡則設計為多層感知機模型。對輸入模態的靈活支持為 InFi 在不同的任務部署方式上的適用性提供了基礎,包括三種典型的以移動為中心的推理任務部署方式:端上推理、卸載至邊緣推理、端 - 邊模型切分推理。
InFi 使用 Python 實現,深度學習模塊基于 TensorFlow 2.4,目前代碼已開源。
驗證實驗
InFi 在 5 個數據集上的 12 種人工智能推理任務上進行了驗證實驗,涵蓋圖片、視頻、文本、音頻、運動信號、中間層特征六種輸入模態。與三個基線方法的對比實驗表明,InFi 具有更廣泛的適用性,并且在準確性和效率上都更優。
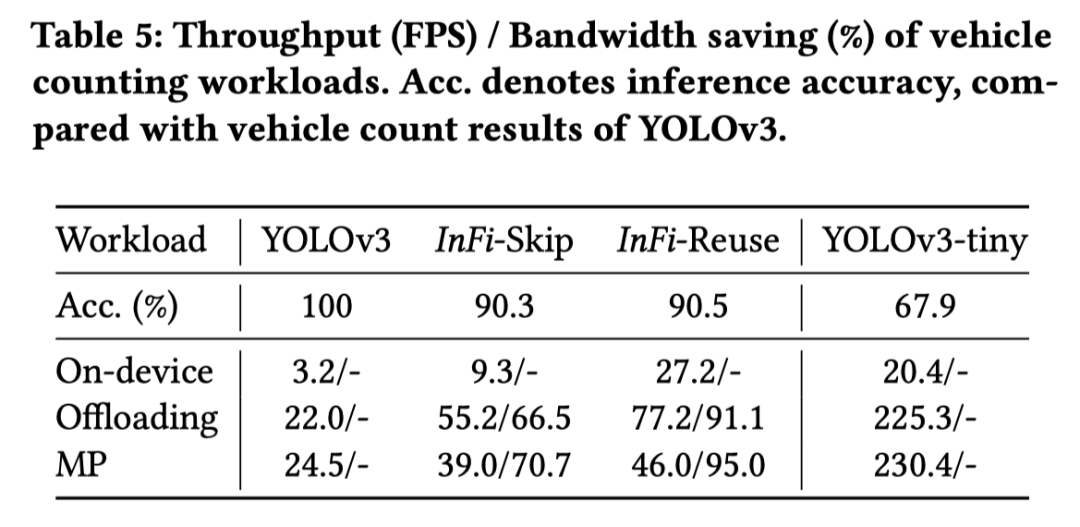
以在城市道路監控視頻中進行車輛計數的任務為例,在端上推理時,相較于原始的工作流,采用 SKIP 和 REUSE 機制的 InFi 方法分別能夠將推理吞吐提升 1.9 和 7.5 倍,同時皆保持超過 90% 的推理精度;在進行端 - 邊模型切分推理時,兩種機制下的 InFi 分別能夠節省 70.7% 和 95.0% 的通信帶寬。
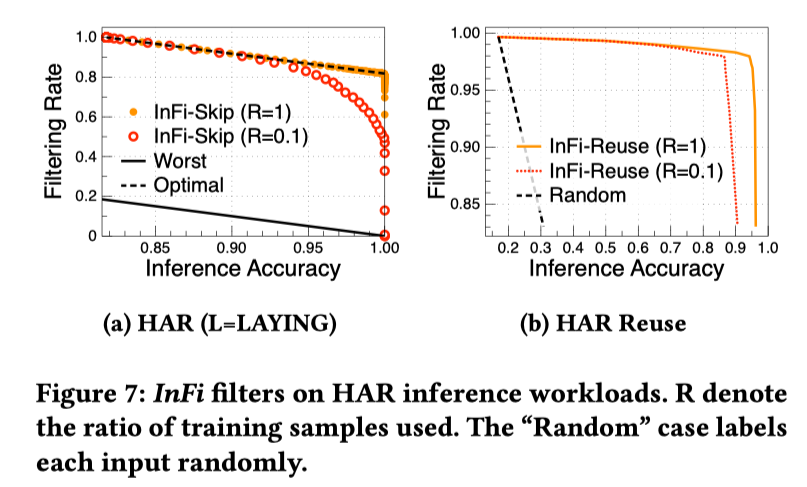
InFi 的訓練成本也很低。在一個基于運動信號的動作識別應用中,僅使用 10% 的訓練數據集即可得到過濾表現接近最優的 SKIP 和 REUSE 結果。InFi 可在保持超過 95% 推理精度的情況下,節省 80% 的推理運算。
結論與未來展望
該工作首次給出了可過濾性的理論分析,提出了統一的端到端可學的輸入過濾框架,并在廣泛的人工智能推理任務中驗證了其設計和實現的優越性,對于實現以移動為中心的資源高效的推理有著重要的意義。InFi 框架的一大優點在于無需人工標注,未來可能會形成新的人工智能模型部署的最佳實踐,即在每個模型的推理服務期間,自監督地訓練輸入過濾器,實現精度 - 資源權衡的模型推理。