













突破分辨率極限,字節(jié)聯(lián)合中科大提出多模態(tài)文檔大模型
現(xiàn)在連文檔都有大模型了,還是高分辨率、多模態(tài)的那種!
不僅能準(zhǔn)確識(shí)別出圖像里的信息,還能結(jié)合用戶需求調(diào)用自己的知識(shí)庫(kù)來(lái)回答問(wèn)題。
比如,看到圖中馬里奧的界面,直接就回答出了這是任天堂公司的作品。

這款模型由字節(jié)跳動(dòng)和中國(guó)科學(xué)技術(shù)大學(xué)合作研究,于2023年11月24日上傳至arXiv。
在此研究中,作者團(tuán)隊(duì)提出DocPedia,一個(gè)統(tǒng)一的高分辨率多模態(tài)文檔大模型DocPedia。

在此研究中,作者用一種新的方式解決了現(xiàn)有模型不能解析高分辨文檔圖像的短板。
DocPedia分辨率可達(dá)2560×2560,而目前業(yè)內(nèi)先進(jìn)多模態(tài)大模型如LLaVA、MiniGPT-4等處理圖像分辨率上限為336×336,無(wú)法解析高分辨率的文檔圖像。
那么,這款模型究竟表現(xiàn)如何,又使用了怎樣的優(yōu)化方式呢?
各項(xiàng)測(cè)評(píng)成績(jī)顯著提升
在論文中,作者展示了DocPedia高分辨圖文理解的示例,可以看到DocPedia能理解指令內(nèi)容,準(zhǔn)確地從高分辨率的文檔圖像和自然場(chǎng)景圖像中提取相關(guān)的圖文信息。
比如這組圖中,DocPedia輕松從圖片中挖掘出了車牌號(hào)、電腦配置等文本信息,甚至手寫文字也能準(zhǔn)確判斷。

結(jié)合圖像中的文本信息,DocPedia還可以利用大模型推理能力,根據(jù)上下文分析問(wèn)題。

讀取完圖片信息后,DocPedia還會(huì)根據(jù)其儲(chǔ)備的豐富的世界知識(shí),回答圖像中沒(méi)有展示出來(lái)的擴(kuò)展內(nèi)容。

下表定量對(duì)比了現(xiàn)有的一些多模態(tài)大模型和DocPedia的關(guān)鍵信息抽取(KIE)和視覺(jué)問(wèn)答(VQA)能力。
可以看到,分辨率的提升和有效的訓(xùn)練方法使DocPedia在各項(xiàng)測(cè)試基準(zhǔn)上均取得了不錯(cuò)的提升。

那么,DocPedia是如何實(shí)現(xiàn)這樣的效果的呢?
從頻域出發(fā)解決分辨率問(wèn)題
DocPedia的訓(xùn)練分為兩個(gè)階段:預(yù)訓(xùn)練和微調(diào)。為了訓(xùn)練DocPedia,作者團(tuán)隊(duì)收集了包含各類文檔的大量圖文數(shù)據(jù),并構(gòu)建指令微調(diào)數(shù)據(jù)集。
在預(yù)訓(xùn)練階段,大語(yǔ)言模型被凍結(jié),僅優(yōu)化視覺(jué)編碼器部分,使其輸出token的表征空間與大語(yǔ)言模型對(duì)齊。
在此階段,作者團(tuán)隊(duì)提出主要訓(xùn)練DocPedia的對(duì)感知能力,包括對(duì)文字和自然場(chǎng)景的感知。
預(yù)訓(xùn)練任務(wù)包括文字檢測(cè)、文字識(shí)別、端到端OCR、段落閱讀、全文閱讀,以及圖像文字說(shuō)明。
在微調(diào)階段,大語(yǔ)言模型解凍,整個(gè)模型端到端優(yōu)化。
并且,作者團(tuán)隊(duì)提出感知-理解聯(lián)合訓(xùn)練策略:在原有低階感知任務(wù)的基礎(chǔ)上,增加文檔理解、場(chǎng)景圖像兩種高階的偏語(yǔ)義理解的任務(wù)。
這樣一種感知-理解聯(lián)合訓(xùn)練策略,進(jìn)一步提高了DocPedia的性能。

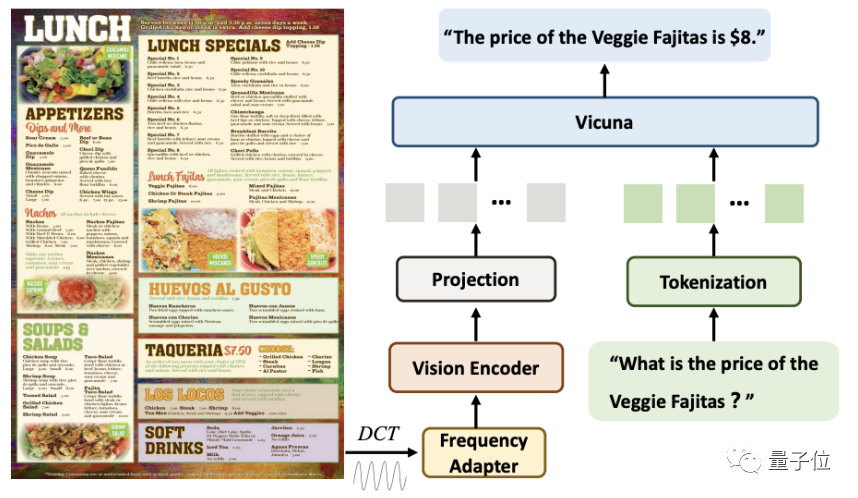
在分辨率問(wèn)題的策略上,與現(xiàn)有方法不同,DocPedia從頻域的角度出發(fā)去解決。
給定一張高分辨率文檔圖像,DocPedia首先提取其DCT系數(shù)矩陣。該矩陣在不損失原圖像圖文信息的前提下,將其空間分辨率下采樣8倍。
然后,通過(guò)一個(gè)級(jí)聯(lián)的頻域適配器(Frequency Adapter),將其輸入視覺(jué)編碼器(Vision Encoder)進(jìn)行進(jìn)一步的分辨率壓縮和特征提取。
通過(guò)此方法,一張2560×2560的圖像,其圖文信息可以用1600個(gè)token表示。
該方法相較于直接將原始圖像輸入到視覺(jué)編碼器(如Swin Transformer)中,token數(shù)量減少4倍。
最后,這些token與指令轉(zhuǎn)換而來(lái)的token進(jìn)行序列維度拼接,輸入到大模型進(jìn)行回答。
消融實(shí)驗(yàn)結(jié)果表明,分辨率的提升和感知-理解聯(lián)合微調(diào)是DocPedia表現(xiàn)增強(qiáng)的兩大關(guān)鍵因素。
下圖對(duì)比了DocPedia對(duì)于一張論文圖像以及同一個(gè)指令,在不同輸入尺度下的回答。可以看到,當(dāng)且僅當(dāng)分辨率提升至2560×2560時(shí),DocPedia回答正確。

下圖則對(duì)比了DocPedia對(duì)于同一張場(chǎng)景文字圖像以及同一個(gè)指令,在不同微調(diào)策略下模型的回答。
由該示例可以看到,進(jìn)行了感知-理解聯(lián)合微調(diào)的模型,能準(zhǔn)確地進(jìn)行文字識(shí)別和語(yǔ)義問(wèn)答。

論文地址:https://arxiv.org/abs/2311.11810




























