CMU創(chuàng)建一個(gè)開(kāi)源的AI代碼生成模型,C語(yǔ)言表現(xiàn)優(yōu)于Codex
最近,語(yǔ)言模型(Language Model, LM)在建模編程語(yǔ)言源代碼方面展現(xiàn)出了令人印象深刻的性能。這些模型擅長(zhǎng)代碼自動(dòng)生成以及從自然語(yǔ)言描述中生成代碼等下游任務(wù)。當(dāng)前 SOTA 大規(guī)模語(yǔ)言代碼模型(如 Austin et al. (2021))在基于 AI 的編程輔助領(lǐng)域已經(jīng)取得了重大進(jìn)展。此外,OpenAI 推出的 Codex 已經(jīng)部署在了現(xiàn)實(shí)世界生產(chǎn)工具 GitHub Copilot 中,用作一個(gè)基于用戶上下文自動(dòng)生成代碼的 in-IDE 開(kāi)發(fā)者助手。
盡管大規(guī)模語(yǔ)言代碼模型取得了巨大成功,但最強(qiáng)大的模型并不是公開(kāi)可用的。這阻止了這些模型在資源充足公司之外的應(yīng)用,并限制了資源匱乏機(jī)構(gòu)在該領(lǐng)域的研究。以 Codex 為例,它通過(guò)黑盒 API 調(diào)用提供了該模型輸出的收費(fèi)訪問(wèn),但模型的權(quán)重和訓(xùn)練數(shù)據(jù)不可用。這阻止了研究人員微調(diào)模型,無(wú)法適應(yīng)代碼完成之外的領(lǐng)域和任務(wù)。無(wú)法訪問(wèn)模型的內(nèi)部也阻止了研究社區(qū)研究它們的其他關(guān)鍵方面,例如可解釋性、用于實(shí)現(xiàn)更高效部署的模型蒸餾以及融合檢索等額外組件。
同時(shí),GPTNeo、GPT-J 和 GPT-NeoX 等中等和大規(guī)模預(yù)訓(xùn)練語(yǔ)言模型是公開(kāi)可用的。盡管這些模型是在包括新聞文章在內(nèi)的多樣化文本、在線論壇以及少量 GitHub 軟件存儲(chǔ)庫(kù)的混合資源上訓(xùn)練的,但它們可以用于生成具有合理性能的源代碼。此外,還有一些僅在源代碼上進(jìn)行訓(xùn)練的全新開(kāi)源語(yǔ)言模型,比如 CodeParrot 是在 180GB 的 Python 代碼上訓(xùn)練的。
遺憾的是,這些模型的大小和訓(xùn)練方案的多樣性以及彼此之間都缺乏比較,許多建模和訓(xùn)練設(shè)計(jì)決策的影響仍不清楚。
在近日一篇論文中,來(lái)自 CMU 計(jì)算機(jī)科學(xué)學(xué)院的幾位研究者對(duì)跨不同編程語(yǔ)言的現(xiàn)有代碼模型——Codex、GPT-J、GPT-Neo、GPT-NeoX 和 CodeParrot 進(jìn)行了系統(tǒng)評(píng)估。他們希望通過(guò)比較這些模型來(lái)進(jìn)一步了解代碼建模設(shè)計(jì)決策的前景,并指出關(guān)鍵的缺失一環(huán),即迄今為止,沒(méi)有大規(guī)模開(kāi)源語(yǔ)言模型專門針對(duì)多編程語(yǔ)言的代碼進(jìn)行訓(xùn)練。研究者推出了三個(gè)此類模型,參數(shù)量從 160M 到 2.7B,并命名為「PolyCoder」。

- 論文地址:https://arxiv.org/pdf/2202.13169.pdf
- 項(xiàng)目地址:https://github.com/VHellendoorn/Code-LMs
研究者首先對(duì) PolyCoder、開(kāi)源模型和 Codex 的訓(xùn)練語(yǔ)評(píng)估設(shè)置進(jìn)行了廣泛的比較;其次,在 HumanEval 基準(zhǔn)上評(píng)估這些模型,并比較了不同大小和訓(xùn)練步的模型如何擴(kuò)展以及不同的溫度如何影響生成質(zhì)量;最后,由于 HumanEval 只評(píng)估自然語(yǔ)言和 Python 生成,他們針對(duì) 12 種語(yǔ)言中的每一種都創(chuàng)建了相應(yīng)未見(jiàn)過(guò)的評(píng)估數(shù)據(jù)集,以評(píng)估不同模型的困惑度。
結(jié)果表明,盡管 Codex 聲稱最擅長(zhǎng) Python 語(yǔ)言,但在其他編程語(yǔ)言中也表現(xiàn)出奇得好,甚至優(yōu)于在 Pile(專為訓(xùn)練語(yǔ)言模型設(shè)計(jì)的 825G 數(shù)據(jù)集)上訓(xùn)練的 GPT-J 和 GPT-NeoX。不過(guò),在 C 語(yǔ)言中,PolyCoder 模型取得的困惑度低于包括 Codex 在內(nèi)的所有其他模型。
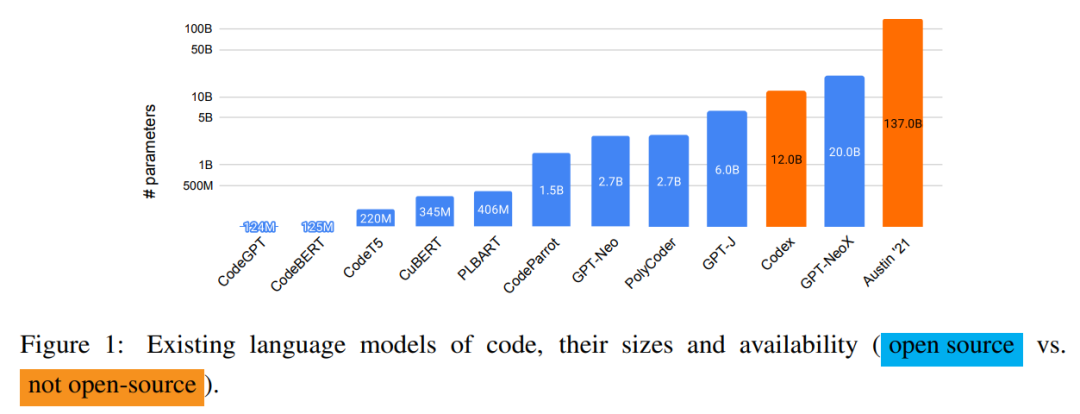
下圖 1 展示了現(xiàn)有語(yǔ)言代碼模型及它們的大小和可用性,除 Codex 和 Austin'21 之外全部開(kāi)源。
研究者還討論了代碼語(yǔ)言建模中使用的三種流行的預(yù)訓(xùn)練方法,具體如下圖 2 所示。

評(píng)估設(shè)置
研究者使用外部和內(nèi)部基準(zhǔn)對(duì)所有模型展開(kāi)了評(píng)估。
外在評(píng)估。代碼建模的最流行下游任務(wù)之一是給定自然語(yǔ)言描述的代碼生成。遵循 Chen et al. (2021),他們?cè)?HumanEval 數(shù)據(jù)集上評(píng)估了所有模型。該數(shù)據(jù)集上包含 164 個(gè)以代碼注釋和函數(shù)定義形式描述的提示,它們包括參數(shù)名稱和函數(shù)名稱以及用于判斷生成代碼是否正確的測(cè)試用例。
內(nèi)在評(píng)估。為了評(píng)估不同模型的內(nèi)在性能,他們?cè)谝唤M未見(jiàn)過(guò)的 GitHub 存儲(chǔ)庫(kù)上計(jì)算了每種語(yǔ)言的困惑度。并且,為了防止 GPT-Neo 和 GPT-J 等模型在訓(xùn)練到測(cè)試的過(guò)程中出現(xiàn)數(shù)據(jù)泄露,他們?cè)谠u(píng)估數(shù)據(jù)集上移除了在 Pile 訓(xùn)練數(shù)據(jù)集的 GitHub 部分出現(xiàn)的存儲(chǔ)庫(kù)。
模型比較
研究者主要選取了自回歸預(yù)訓(xùn)練語(yǔ)言模型,這類模型最適合代碼完成任務(wù)。具體地,他們?cè)u(píng)估了 Codex,OpenAI 開(kāi)發(fā)的這一模型目前部署在了現(xiàn)實(shí)世界,并在代碼完成任務(wù)中展現(xiàn)出了卓越的性能。Codex 在 179GB(重復(fù)數(shù)據(jù)刪除后)的數(shù)據(jù)集上進(jìn)行訓(xùn)練,該數(shù)據(jù)集包含了 2020 年 5 月從 GitHub 中獲得的 5400 萬(wàn)個(gè)公開(kāi) Python 存儲(chǔ)庫(kù)。
至于開(kāi)源模型,研究者比較了 GPT 的三種變體模型 ——GPT-Neo(27 億參數(shù))、GPT-J(60 億參數(shù))和 GPT-NeoX(200 億參數(shù))。其中,GPT-NeoX 是目前可用的最大規(guī)模的開(kāi)源預(yù)訓(xùn)練語(yǔ)言模型。這些模型都在 Pile 數(shù)據(jù)集上進(jìn)行訓(xùn)練。
目前,社區(qū)并沒(méi)有專門針對(duì)多編程語(yǔ)言代碼進(jìn)行訓(xùn)練的大規(guī)模開(kāi)源語(yǔ)言模型。為了彌補(bǔ)這一缺陷,研究者在 GitHub 中涵蓋 12 種不同編程語(yǔ)言的存儲(chǔ)庫(kù)集合上訓(xùn)練了一個(gè) 27 億參數(shù)的模型——PolyCoder。
PolyCoder 的數(shù)據(jù)
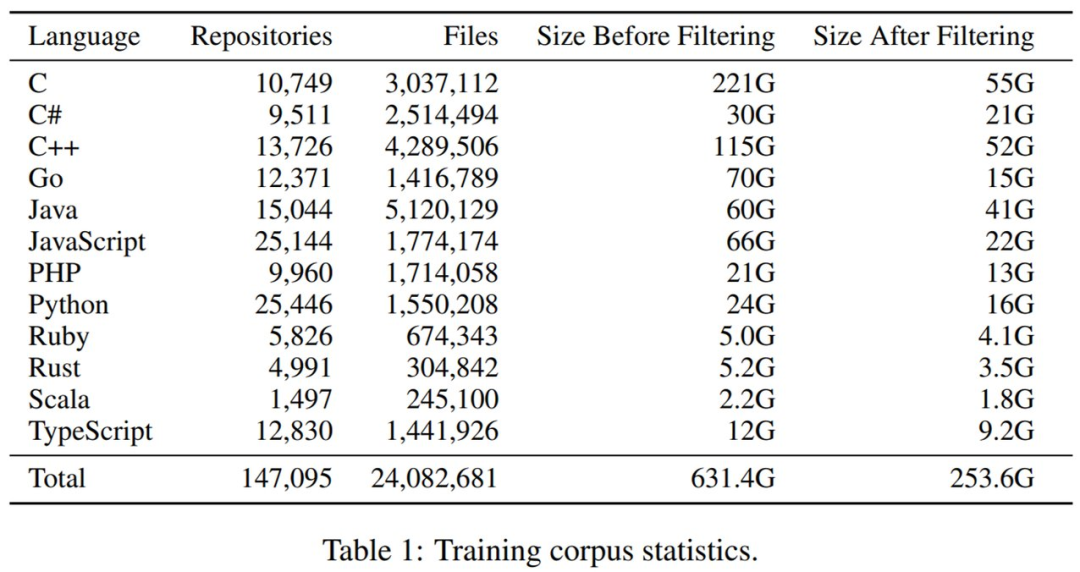
原始代碼庫(kù)集合。研究者針對(duì) 12 種流行編程語(yǔ)言克隆了 2021 年 10 月 GitHub 上 Star 量超 50 的的最流行存儲(chǔ)庫(kù)。最開(kāi)始未過(guò)濾的數(shù)據(jù)集為 631GB 和 3890 萬(wàn)個(gè)文件。
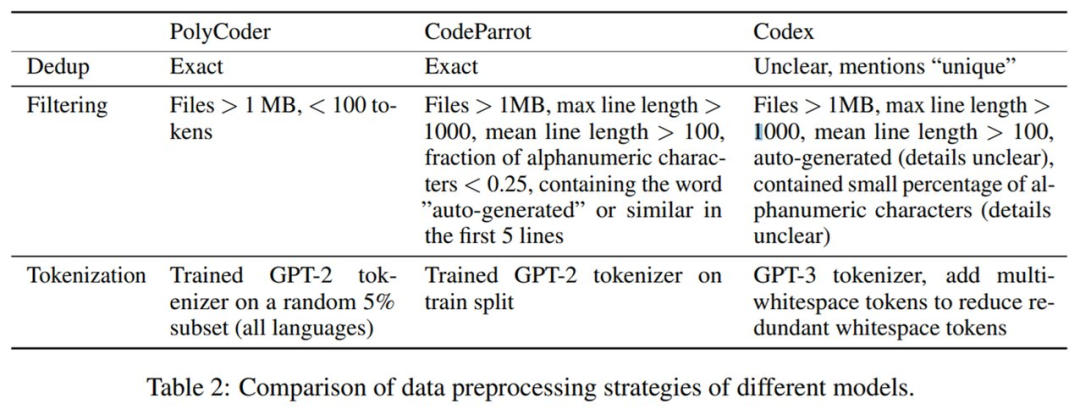
接著進(jìn)行數(shù)據(jù)預(yù)處理。PolyCoder 與 CodeParrot、Codex 的數(shù)據(jù)預(yù)處理策略的詳細(xì)對(duì)比如下表 2 所示。
最后是重復(fù)數(shù)據(jù)刪除和過(guò)濾。整體來(lái)看,過(guò)濾掉非常大和非常小的文件以及刪除重復(fù)數(shù)據(jù),將文件總量減少了 38%,數(shù)據(jù)集大小減少了 61%。下表 1 展示了過(guò)濾前后數(shù)據(jù)集大小的變化。
PolyCoder 的訓(xùn)練
考慮到預(yù)算,研究者選擇將 GPT-2 作為模型架構(gòu)。為了探究模型大小縮放的影響,他們分別訓(xùn)練了參數(shù)量為 1.6 億、4 億和 27 億的 PolyCoder 模型,并使用 27 億參數(shù)的模型與 GPT-Neo 進(jìn)行公平比較。
研究者使用 GPT-NeoX 工具包在單臺(tái)機(jī)器上與 8 塊英偉達(dá) RTX 8000 GPU 并行高效地訓(xùn)練模型。訓(xùn)練 27 億參數(shù) PolyCode 模型的時(shí)間約為 6 周。在默認(rèn)設(shè)置下,PolyCode 模型應(yīng)該訓(xùn)練 32 萬(wàn)步。但受限于手頭資源,他們將學(xué)習(xí)率衰減調(diào)整至原來(lái)的一半,訓(xùn)練了 15 萬(wàn)步。
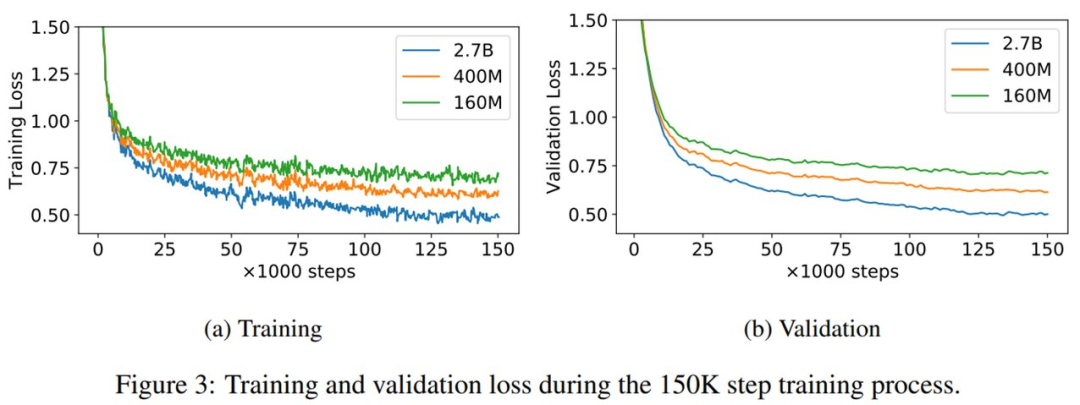
1.6 億、4 億和 27 億參數(shù)量 PolyCode 模型的訓(xùn)練和驗(yàn)證損失曲線如下圖 3 所示。可以看到,即使訓(xùn)練 15 萬(wàn)步之后,驗(yàn)證損失依然降低。
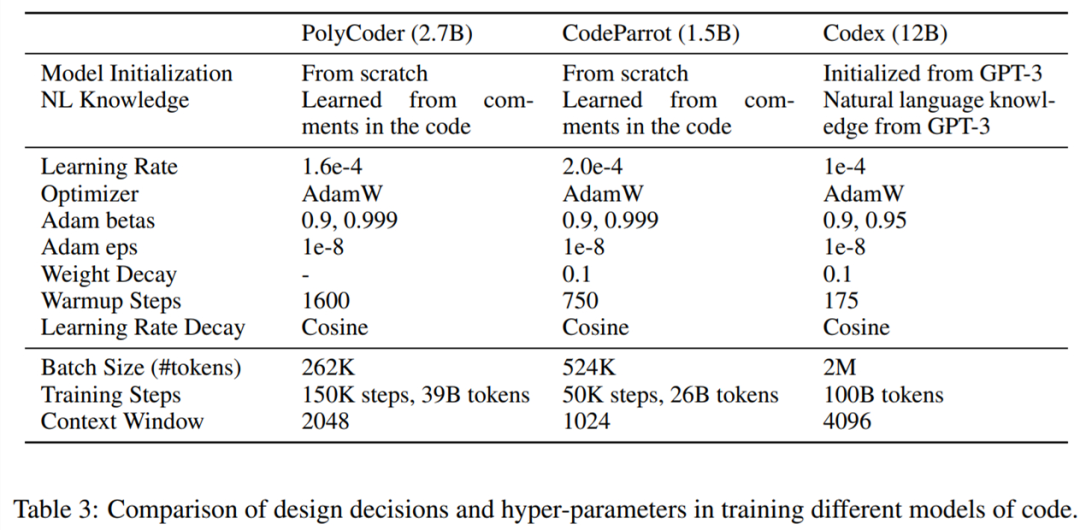
下表 3 展示了訓(xùn)練不同代碼模型中的設(shè)計(jì)決策和超參數(shù)比較情況。
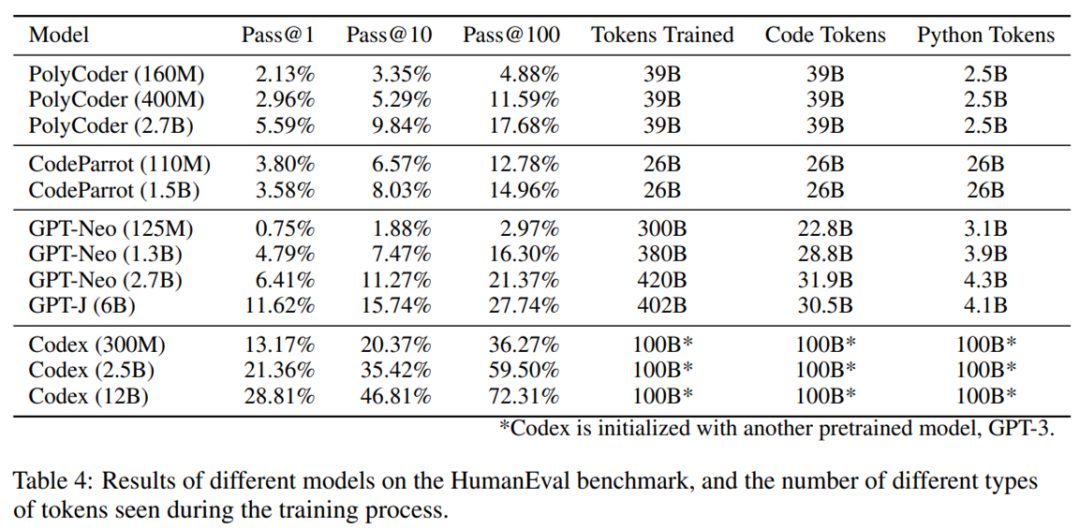
實(shí)驗(yàn)結(jié)果
外在評(píng)估
整體結(jié)果如下表 4 所示。在現(xiàn)有模型中,PolyCoder 弱于類似規(guī)模的 GPT-Neo 和規(guī)模更小的 Codex 300M。總的來(lái)說(shuō),該模型不如 Codex 和 GPT-Neo/J,但強(qiáng)于 CodeParrot。
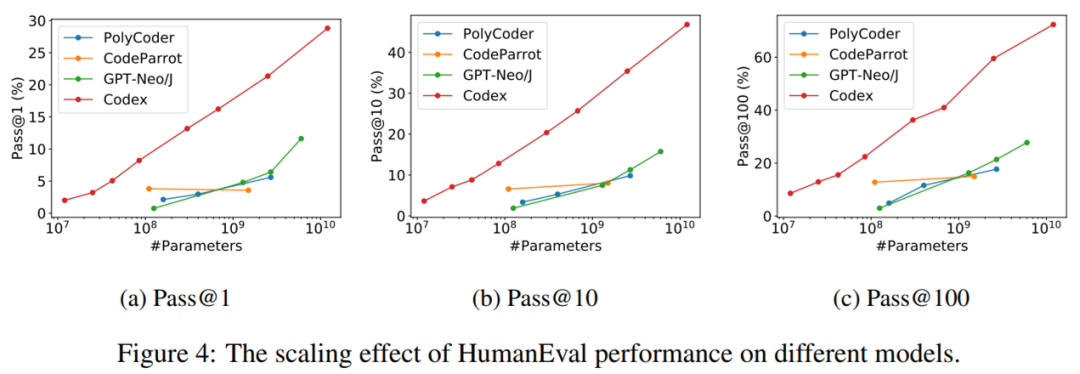
縮放影響。為了進(jìn)一步了解模型參數(shù)量對(duì) HumanEval 代碼完成性能的影響,研究者在下圖 4 中展示了 Pass@1、Pass@10 和 Pass@100 的性能變化。
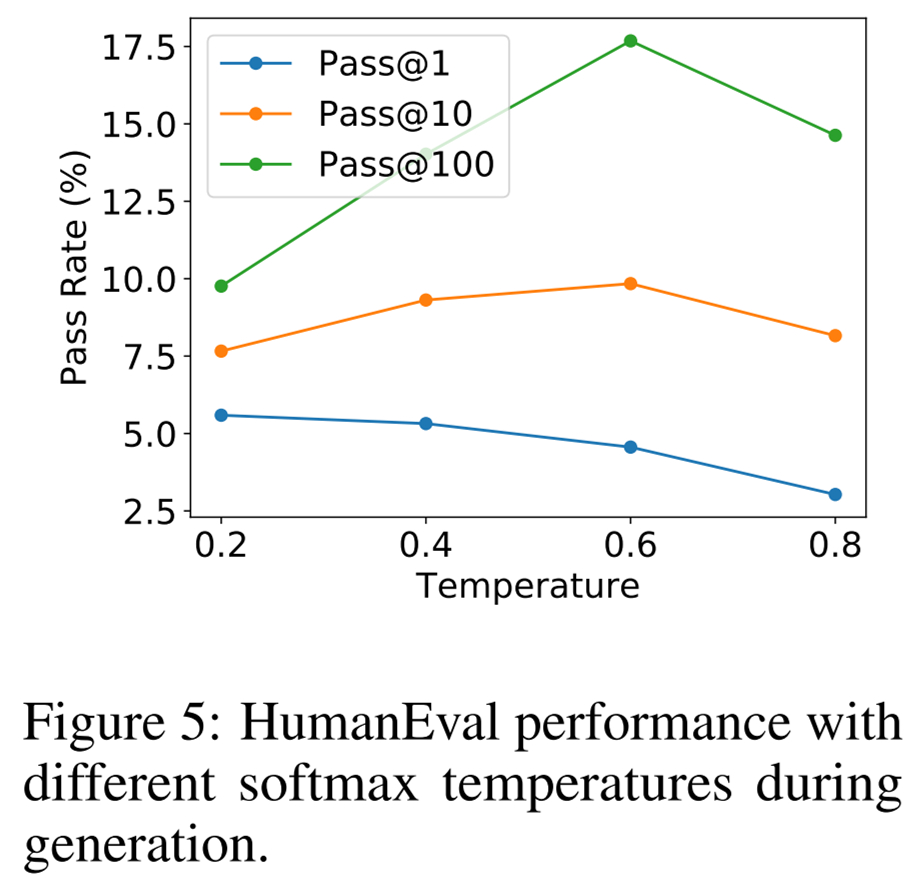
溫度影響。上述所有結(jié)果都是通過(guò)采樣不同溫度的語(yǔ)言模型并為每個(gè)指標(biāo)選擇最佳值獲得的。研究者同樣感興趣的是不同的溫度如何影響最終生成質(zhì)量,結(jié)果如下圖 5 所示。
內(nèi)在評(píng)估
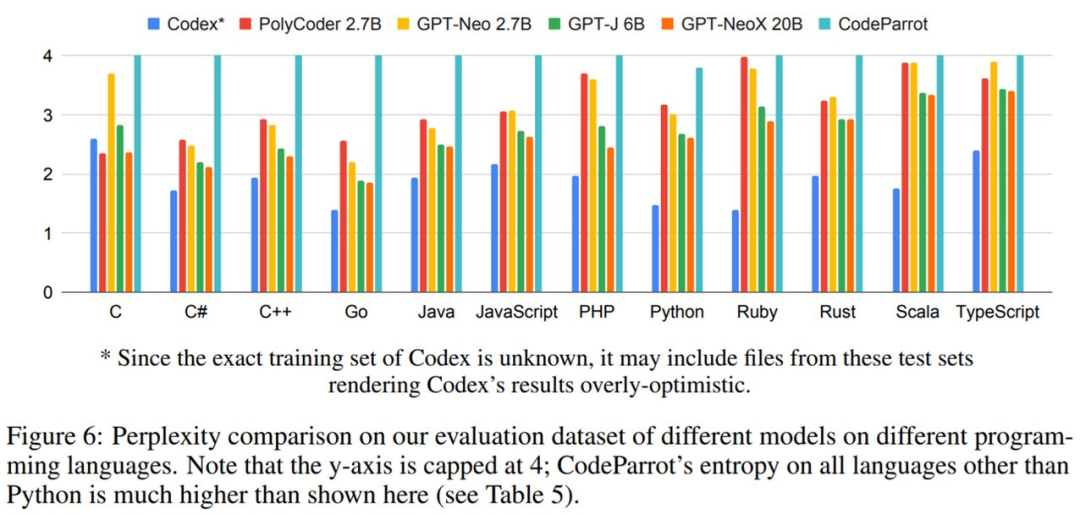
不同模型在評(píng)估數(shù)據(jù)集上的困惑度結(jié)果如下圖 6 所示。困惑度得分最高為 4。可以看到,PolyCoder 在 C 語(yǔ)言中優(yōu)于 Codex 和其他所有模型。并且,僅與開(kāi)源模型相比,PolyCoder 在 C、JavaScript、Rust、Scala 和 TypeScript 中的表現(xiàn)優(yōu)于類似規(guī)模的 GPT-Neo 2.7B。
此外,除 C 語(yǔ)言之外的其他 11 種語(yǔ)言,包括 PolyCoder 在內(nèi)的所有開(kāi)源模型的表現(xiàn)都弱于 Codex。