作者 | 逸帆 家恒 崢少等
美團內(nèi)部深度定制的TensorFlow版本,基于原生TensorFlow 1.x架構與接口,從大規(guī)模稀疏參數(shù)的支持、訓練模式、分布式通信優(yōu)化、流水線優(yōu)化、算子優(yōu)化融合等多維度進行了深度優(yōu)化。在推薦系統(tǒng)場景中,分布式擴展性提升10倍以上,單位算力性能也有顯著提升,并在美團內(nèi)部業(yè)務中大量使用,本文介紹了相關的優(yōu)化與實踐工作。
1 背景
TensorFlow(下文簡稱TF)是谷歌推出的一個開源深度學習框架,在美團推薦系統(tǒng)場景中得到了廣泛的使用。但TensorFlow官方版本對工業(yè)級場景的支持,目前做得并不是特別的完善。美團在大規(guī)模生產(chǎn)落地的過程中,遇到了以下幾方面的挑戰(zhàn):
- 所有參數(shù)都是用Variable表達, 對于百億以上的稀疏參數(shù)開辟了大量的內(nèi)存,造成了資源的浪費;
- 只支持百級別Worker的分布式擴展,對上千Worker的擴展性較差;
- 由于不支持大規(guī)模稀疏參數(shù)動態(tài)添加、刪除,增量導出,導致無法支持Online Learning;
- 大規(guī)模集群運行時,會遇到慢機和宕機;由于框架層不能處理,導會致任務運行異常。
以上這些問題,并不是TensorFlow設計的問題,更多是底層實現(xiàn)的問題。考慮到美團大量業(yè)務的使用習慣以及社區(qū)的兼容性,我們基于原生TensorFlow 1.x架構與接口,從大規(guī)模稀疏參數(shù)的支持、訓練模式、分布式通信優(yōu)化、流水線優(yōu)化、算子優(yōu)化融合等多維度進行了深度定制,從而解決了該場景的核心痛點問題。首先新系統(tǒng)在支持能力層面,目前可以做到千億參數(shù)模型,上千Worker分布式訓練的近線性加速,全年樣本數(shù)據(jù)能夠1天內(nèi)完成訓練,并支持Online Learning的能力。同時,新系統(tǒng)的各種架構和接口更加友好,美團內(nèi)部包括美團外賣、美團優(yōu)選、美團搜索、廣告平臺、大眾點評Feeds等業(yè)務部門都在使用。本文將重點介紹大規(guī)模分布式訓練優(yōu)化的工作,希望對大家能夠有所幫助或啟發(fā)。
2 大規(guī)模訓練優(yōu)化挑戰(zhàn)
2.1 業(yè)務迭代帶來的挑戰(zhàn)
隨著美團業(yè)務的發(fā)展,推薦系統(tǒng)模型的規(guī)模和復雜度也在快速增長,具體表現(xiàn)如下:
- 訓練數(shù)據(jù):訓練樣本從到百億增長到千億,增長了近10倍。
- 稀疏參數(shù):個數(shù)從幾百到幾千,也增長了近10倍;總參數(shù)量從幾億增長到百億,增長了10~20倍。
- 模型復雜度:越來越復雜,模型單步計算時間增長10倍以上。
對于大流量業(yè)務,一次訓練實驗,從幾個小時增長到了幾天,而此場景一次實驗保持在1天之內(nèi)是基本的需求。
2.2 系統(tǒng)負載分析
2.2.1 問題分析工具鏈
TensorFlow是一個非常龐大的開源項目,代碼有幾百萬行之多,原生系統(tǒng)的監(jiān)控指標太粗,且不支持全局的監(jiān)控,如果要定位一些復雜的性能瓶頸點,就比較困難。我們基于美團已經(jīng)開源的監(jiān)控系統(tǒng)CAT[2],構建了TensorFlow的細粒度監(jiān)控鏈路(如下圖1所示),可以精準定位到性能的瓶頸問題。
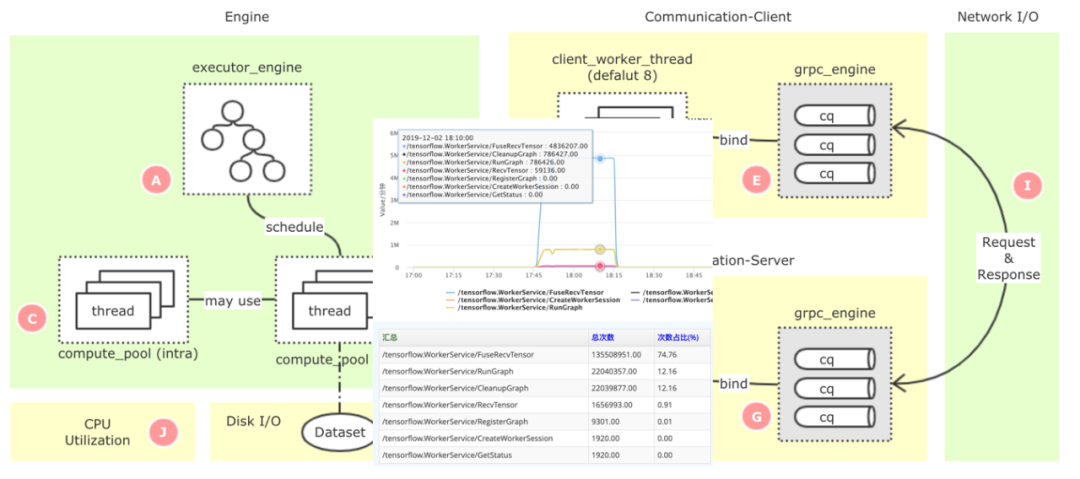
圖1 TensorFlow PS架構全鏈路監(jiān)控同時,在性能優(yōu)化的過程中,會涉及到大量的性能測試和結果分析,這也是一個非常耗費人力的工作。我們抽象了一套自動化的實驗框架(如下圖2所示),可以自動化、多輪次地進行實驗,并自動采集各類監(jiān)控指標,然后生成報告。
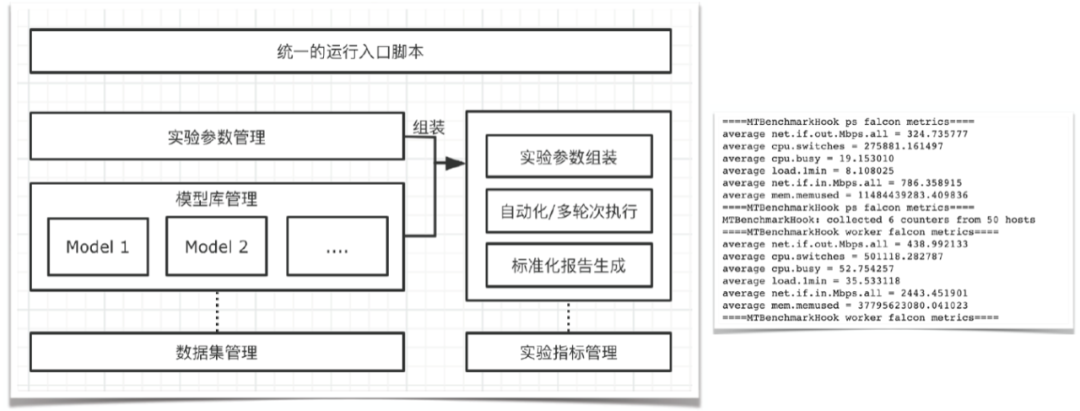
圖2 自動化實驗框架
2.2.2 業(yè)務視角的負載分析
在推薦系統(tǒng)場景中,我們使用了TensorFlow Parameter Server[3](簡稱PS)異步訓練模式來支持業(yè)務分布式訓練需求。對于這套架構,上述的業(yè)務變化會帶來什么樣的負載變化?如下圖3所示:
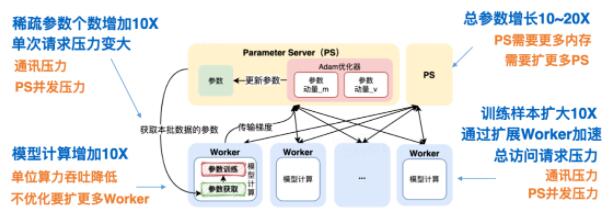

圖3 TensorFlow PS架構大規(guī)模訓練負載分析總結來看,主要包括通信壓力、PS并發(fā)壓力、Worker計算壓力。對于分布式系統(tǒng)來說,通常是通過橫向擴展來解決負載問題。雖然看來起可以解決問題,但從實驗結果來看,當PS擴展到一定數(shù)量后,單步訓練時間反而會增加,如下圖4所示:
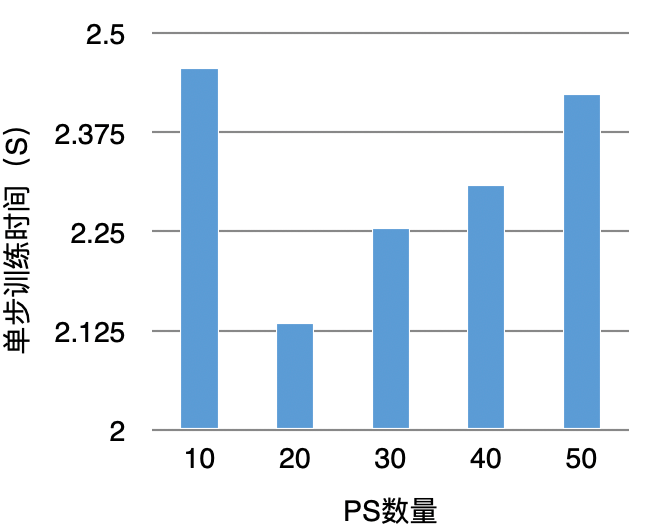
圖4 擴展PS提升訓練性能實驗
導致這種結果的核心原因是:Worker單步訓練需要和所有的PS通信同步完成,每增加1個PS要增加N條通信鏈路,這大大增加了鏈路延遲(如下圖5所示)。而一次訓練要執(zhí)行上百萬、上千萬步訓練。最終導致鏈路延遲超過了加PS算力并發(fā)的收益。
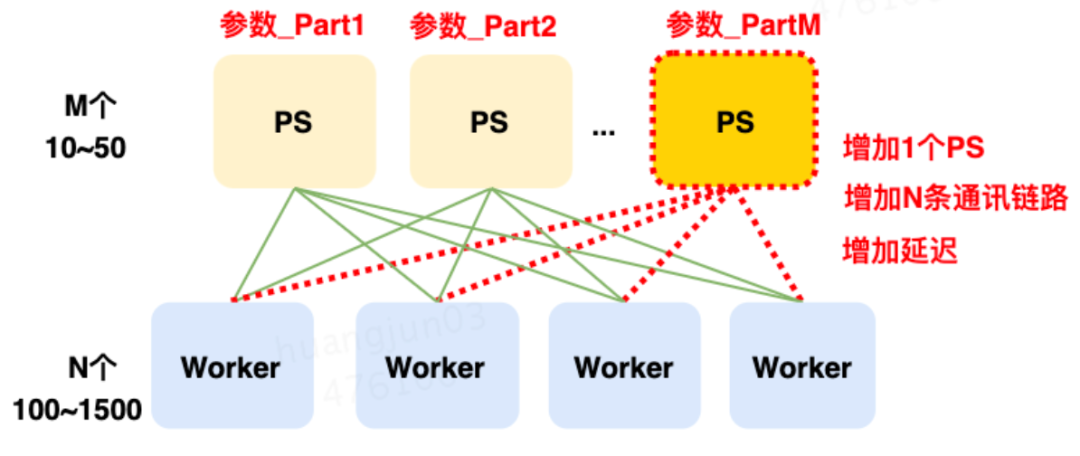
圖5 增加PS帶來的鏈路開銷而對于這個系統(tǒng),優(yōu)化的核心難點在于:如何在有限的PS實例下,進行分布式計算的優(yōu)化。
3 優(yōu)化實踐
3.1 大規(guī)模稀疏參數(shù)介紹
對于推薦系統(tǒng)模型,絕大多數(shù)參數(shù)都是稀疏參數(shù),而對稀疏參數(shù)來說有一個非常重要的操作是Embedding,這個操作通常也是負載最重的,也是后續(xù)優(yōu)化的重點。由于我們對稀疏參數(shù)進行了重新定義,后續(xù)的優(yōu)化也基于此之上,所以我們先介紹一下這部分的工作。在原生的TensorFlow中構建Embedding模塊,用戶需要首先創(chuàng)建一個足夠裝得下所有稀疏參數(shù)的Variable,然后在這個Variable上進行Embedding的學習。然而,使用Variable來進行Embedding訓練存在很多弊端:
- Variable的大小必須提前設定好,對于百億千億的場景,該設定會帶來巨大的空間浪費;
- 訓練速度慢,無法針對稀疏模型進行定制優(yōu)化。
我們首先解決了有無的問題,使用HashTable來替代Variable,將稀疏特征ID作為Key,Embedding向量作為Value。相比原生使用Variable進行Embedding的方式,具備以下的優(yōu)勢:
- HashTable的大小可以在訓練過程中自動伸縮,避免了開辟冗余的存儲空間,同時用戶無需關注申請大小,從而降低了使用成本。
- 針對HashTable方案實施了一系列定制優(yōu)化,訓練速度相比Variable有了很大的提高,可以進行千億規(guī)模模型的訓練,擴展性較好。
- 得益于稀疏參數(shù)的動態(tài)伸縮,我們在此基礎上支持了Online Learning。
- API設計上保持與社區(qū)版本兼容,在使用上幾乎與原生Variable一致,對接成本極低。
簡化版的基于PS架構的實現(xiàn)示意如下圖6所示:
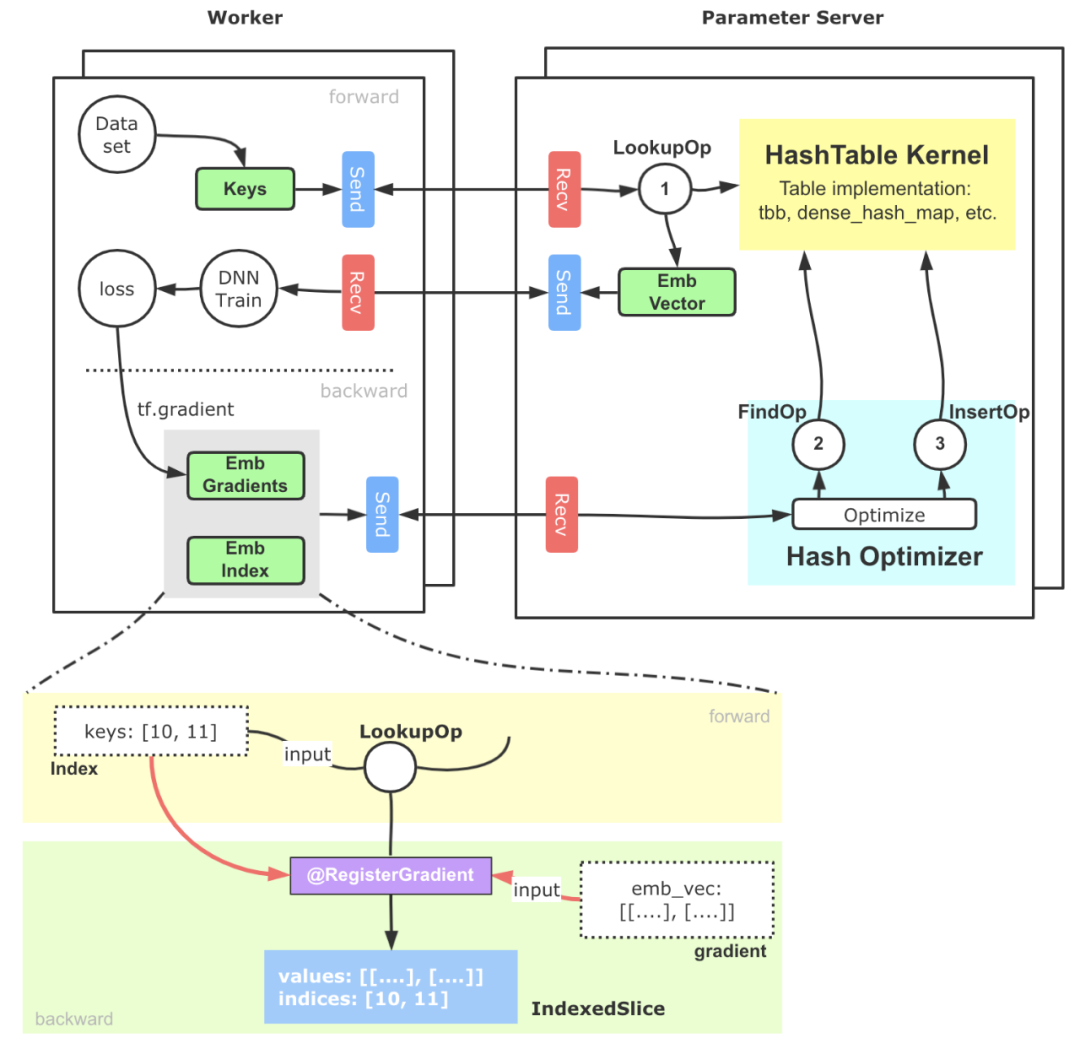
圖6 支撐大規(guī)模稀疏參數(shù)的HashTable方案核心流程大致可以分為以下幾步:
- 稀疏特征ID(通常我們會提前完成統(tǒng)一編碼的工作)進入Embedding模塊,借助TensorFlow搭建的Send-Recv機制,這些稀疏特征ID被拉取到PS端,PS端上的Lookup等算子會實際從底層HashTable中查詢并組裝Embedding向量。
- 上述Embedding向量被Worker拉回進行后續(xù)訓練,并通過反向傳播計算出這部分參數(shù)的梯度,這些梯度進一步被位于PS端的優(yōu)化器拉回。
- PS端的優(yōu)化器首先調(diào)用Find算子,從HashTable獲取到梯度對應的原始稀疏參數(shù)向量和相應的優(yōu)化器參數(shù),最終通過優(yōu)化算法,完成對Embedding向量和優(yōu)化器參數(shù)的更新計算,再通過Insert算子插入HashTable中。
3.2 分布式負載均衡優(yōu)化
這部分優(yōu)化,是分布式計算的經(jīng)典優(yōu)化方向。PS架構是一個典型的“水桶模型”,為了完成一步訓練,Worker端需要和所有PS完成交互,因此PS之間的平衡就顯得非常重要。但是在實踐中,我們發(fā)現(xiàn)多個PS的耗時并不均衡,其中的原因,既包括TensorFlow PS架構簡單的切圖邏輯(Round-Robin)帶來的負載不均衡,也有異構機器導致的不均衡。對于推薦模型來說,我們的主要優(yōu)化策略是,把所有稀疏參數(shù)和大的稠密參數(shù)自動、均勻的切分到每個PS上,可以解決大多數(shù)這類問題。而在實踐過程中,我們也發(fā)現(xiàn)一個比較難排查的問題:原生Adam優(yōu)化器,實現(xiàn)導致PS負載不均衡。下面會詳細介紹一下。在Adam優(yōu)化器中,它的參數(shù)優(yōu)化過程需要兩個β參與計算,在原生TensorFlow的實現(xiàn)中,這兩個β是所有需要此優(yōu)化器進行優(yōu)化的Variabl(或HashTable)所共享的,并且會與第一個Variable(名字字典序)落在同一個PS上面,這會帶來一個問題:每個優(yōu)化器只擁有一個β和一個β,且僅位于某個PS上。因此,在參數(shù)優(yōu)化的過程中,該PS會承受遠高于其他PS的請求,從而導致該PS成為性能瓶頸。
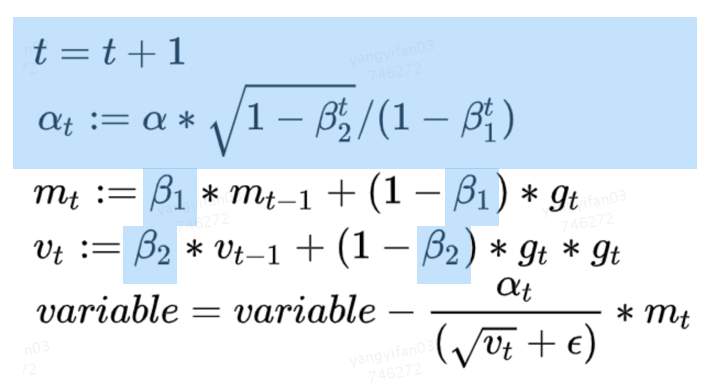
圖7 Adam優(yōu)化算法但是通過觀察Adam的優(yōu)化算法,我們可以看到β和β都是常量,且藍色高亮的部分都是相對獨立的計算過程,各個PS之間可以獨立完成。基于這樣的發(fā)現(xiàn),優(yōu)化的方法也就非常直觀了,我們?yōu)槊恳粋€PS上的Adam優(yōu)化器冗余創(chuàng)建了β參數(shù),并在本地計算t和alpha值,去除了因此負載不均導致的PS熱點問題。該優(yōu)化所帶來的提升具備普適性且效果明顯,在美團內(nèi)部某業(yè)務模型上,通過β熱點去除可以帶來9%左右的性能提升。此外,由于擺脫了對β的全局依賴,該優(yōu)化還能提高PS架構的可擴展性,在擴增Worker數(shù)量的時候相比之前會帶來更好的加速比。
3.3 通信優(yōu)化
通過2.2章節(jié)的分析可知,系統(tǒng)的通信壓力也非常大,我們主要基于RDMA做了通信優(yōu)化的工作。首先簡單介紹一下RDMA,相比較于傳統(tǒng)基于套接字TCP/IP協(xié)議棧的通信過程,RDMA具有零拷貝、內(nèi)核旁路的優(yōu)勢,不僅降低了網(wǎng)絡的延遲,同時也降低了CPU的占用率,RDMA更適合深度學習模型的相關通信過程。RDMA主要包括三種協(xié)議Infiniband、RoCE(V1, V2)、iWARP。在美團內(nèi)部的深度學習場景中,RDMA通信協(xié)議使用的是RoCE V2協(xié)議。目前在深度學習訓練領域,尤其是在稠密模型訓練場景(NLP、CV等),RDMA已經(jīng)是大規(guī)模分布式訓練的標配。然而,在大規(guī)模稀疏模型的訓練中,開源系統(tǒng)對于RDMA的支持非常有限,TensorFlow Verbs[4]通信模塊已經(jīng)很長時間沒有更新了,通信效果也并不理想,我們基于此之上進行了很多的改進工作。經(jīng)過優(yōu)化后的版本,在1TB Click Logs[5]公開數(shù)據(jù)集、DLRM[6]模型、100個Worker以上的訓練,性能提升了20%~40%。在美團的多個業(yè)務模型上,對比TensorFlow Seastar[7]改造的通信層實現(xiàn)也有10%~60%的速度提升。同時也把我們的工作回饋給了社區(qū)。
3.3.1 Memory Registration優(yōu)化
RDMA有三種數(shù)據(jù)傳輸?shù)姆绞絊END/RECV、WRITE、READ,其中WRITE、READ類似于數(shù)據(jù)發(fā)送方直接在遠程Memory進行讀寫,Receiver無法感知,WRITE和READ適用于批量數(shù)據(jù)傳輸。在TensorFlow內(nèi)部,基于RDMA的數(shù)據(jù)傳輸方式使用的是WRITE單邊通信模式。
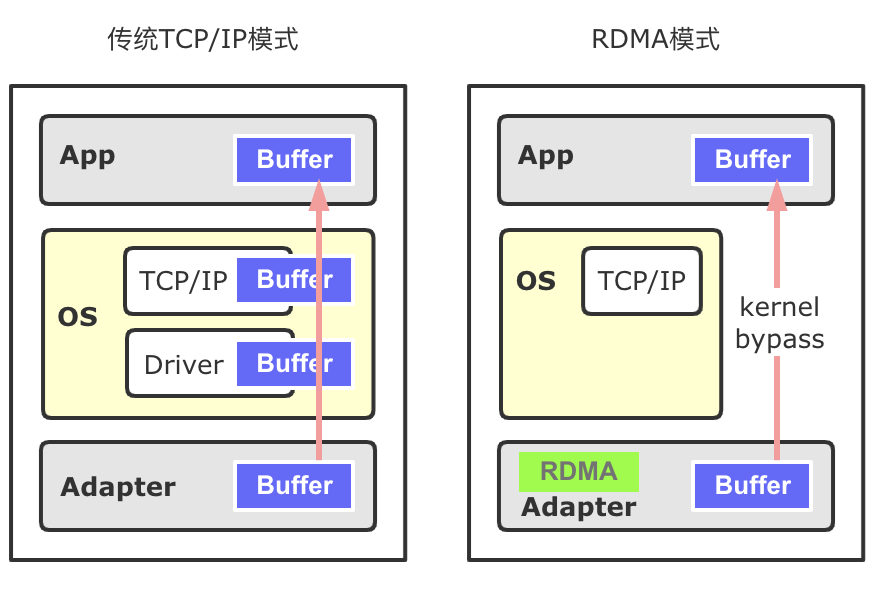
圖8 RDMA傳輸方式在RDMA傳輸數(shù)據(jù)時,需要提前開辟內(nèi)存空間并將其注冊到網(wǎng)卡設備上(Memory Registration過程,下稱MR),使得這片空間可以被網(wǎng)卡直接操作。開辟新的內(nèi)存并注冊到設備上,整個過程是比較耗時的。下圖9展示了不同大小的內(nèi)存綁定到網(wǎng)卡設備上的耗時,可以看到隨著注冊內(nèi)存的增大,綁定MR的耗時迅速增加。
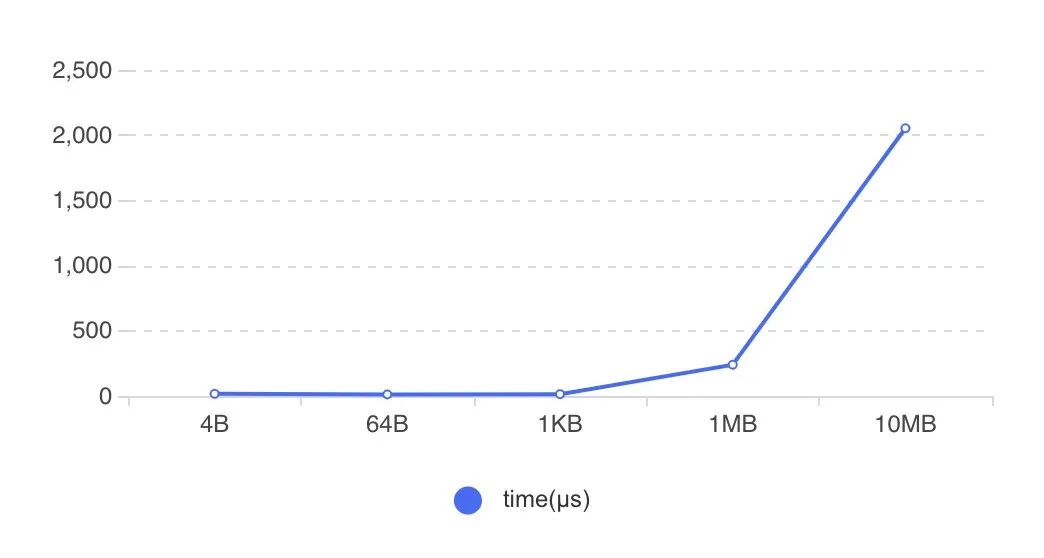
圖9 MR過程開銷社區(qū)版Tensorflow RDMA實現(xiàn),Tensor創(chuàng)建依舊沿用了統(tǒng)一的BFC Allocator,并將所有創(chuàng)建的Tensor都注冊到MR上。正如上面所提到的,MR的注冊綁定具有性能開銷,高頻、大空間的MR注冊會帶來顯著的性能下降。而訓練過程中的Tensor,只有那些涉及到跨節(jié)點通信的Tensor有必要進行MR,其余Tensor并不需要注冊到MR。因此,優(yōu)化的方法也就比較直接了,我們識別并管理那些通信Tensor,僅對這些跨節(jié)點通信的Tensor進行MR注冊就好了。
3.3.2 RDMA靜態(tài)分配器
RDMA靜態(tài)分配器是上一個MR注冊優(yōu)化的延伸。通過Memory Registration優(yōu)化,去除非傳輸Tensor的MR注冊,我們降低了MR注冊數(shù)量。但是在稀疏場景大規(guī)模的訓練下,并行訓練的Worker常有幾百上千個,這會帶來新的問題:
- PS架構中的PS和Worker互為Client-Server,這里以PS端為例,當Worker數(shù)目增加到上千個時,Worker數(shù)目的增多,造成PS端MR注冊頻次還是非常高,增加了內(nèi)存分配注冊的耗時。
- 由于稀疏場景不同Step之間同一個算子輸出Tensor的形狀可能發(fā)生變化,導致了創(chuàng)建的MR可復用性較差,帶來了較高的內(nèi)存碎片和重復注冊MR開銷。
針對上面的問題,我們引入了MR靜態(tài)分配器的策略。
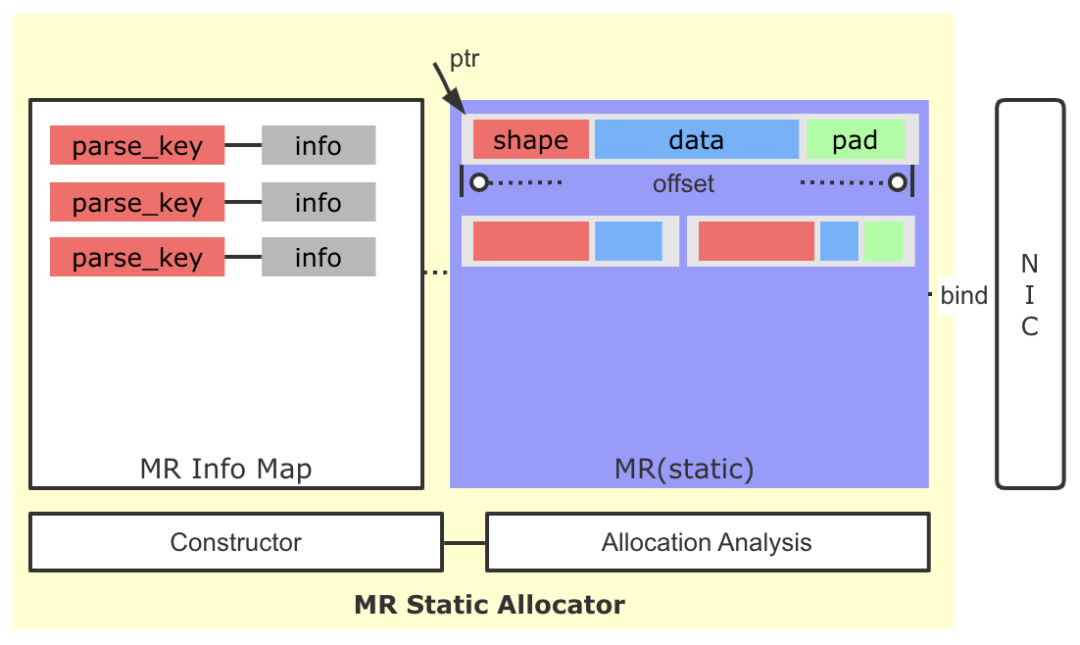
圖10 MR靜態(tài)分配器
這里核心的設計思路為:
- 雖然稀疏場景同一個算子輸出Tensor的Shape存在變化的可能,但是整體變化幅度可控,通過監(jiān)控與分析,是可以找到一個較為穩(wěn)定的內(nèi)存大小,滿足多Step間Tensor的存儲需求。
- 基于上面的信息,我們修改了原有逐Tensor(Request)的MR申請策略,通過一次性預申請一塊較大的空間并注冊到網(wǎng)卡端,后續(xù)通過自己維護的分配策略進行空間的分配,大大降低了MR申請的頻率,絕大多數(shù)情況下,訓練全過程中只需要一次MR注冊申請即可。
- 我們引入了一種簡單的交換協(xié)議,將傳輸Tensor的Shape,Data打包到一起,寫到Client端。Client端根據(jù)協(xié)議,解析出Tensor大小,并最終讀取Data,避免了原生實現(xiàn)中因Tensor的Shape變化而產(chǎn)生的多次協(xié)商過程。

圖11 MR靜態(tài)分配器構造流程具體到實現(xiàn)中,我們引入了Allocation Analysis模塊,在訓練開始的一段時間,我們會對分配的歷史數(shù)據(jù)進行分析,以得到一個實際預開辟MR大小以及各個Tensor的預留空間大小。然后我們會暫停訓練的進程,啟動Allocator的構造過程,包括MR的創(chuàng)建以及通信雙端的信息同步。利用相關信息構造MR Info Map,這個Map的Key是傳輸Tensor的唯一標記(ParsedKey,計算圖切圖時確定),Info結構體中包含了本地地址指針、offset大小、ibv_send_wr相關信息等。然后恢復訓練,后續(xù)Tensor的傳輸就可以使用靜態(tài)開辟好的MR進行收發(fā),也免去了因Shape變化而產(chǎn)生的多次協(xié)商過程。
3.3.3 Multi RequestBuffer與CQ負載均衡
TensorFlow社區(qū)版的RDMA通信過程,不僅僅包含上面Tensor數(shù)據(jù)的發(fā)送和接收過程,還包括傳輸相關的控制消息的發(fā)送和接收過程,控制消息的發(fā)送和接收過程同樣是使用了ibv_post_send和ibv_post_recv原語。原生的控制流實現(xiàn)存在一些瓶頸,在大規(guī)模訓練時會限制控制流的吞吐,進而影響數(shù)據(jù)收發(fā)的效率。具體體現(xiàn)在:
- 請求的發(fā)送通過同一片RequestBuffer內(nèi)存進行寫出,多個Client的請求均依賴這一片Buffer,也就導致到控制流信息實際是串行發(fā)送的,只有等到對端的Ack信息后,才可以下一個Request的寫出,限制了請求的發(fā)送吞吐。
- 在Client端需要輪詢RDMA Completion Queue來獲得請求的到達,以及相關狀態(tài)的變更。原生實現(xiàn)僅有一個Completion Queue,單線程進行輪詢處理,在大規(guī)模分布式訓練中,限制了應答的效率。
針對上面的問題,我們采用了Multi RequestBuffer與CQ負載均衡優(yōu)化,破除了在請求發(fā)送和請求應答環(huán)節(jié)可能存在的吞吐瓶頸。
3.3.4 Send-Driven & Rendezvous-Bypass
對于Tensorflow PS架構熟悉的同學會了解,一整張計算圖被切割為Worker端和PS端后,為了使兩張計算圖能夠彼此交換數(shù)據(jù),建立了基于Rendezvous(匯合點)機制的異步數(shù)據(jù)交換模式。如下圖12所示:
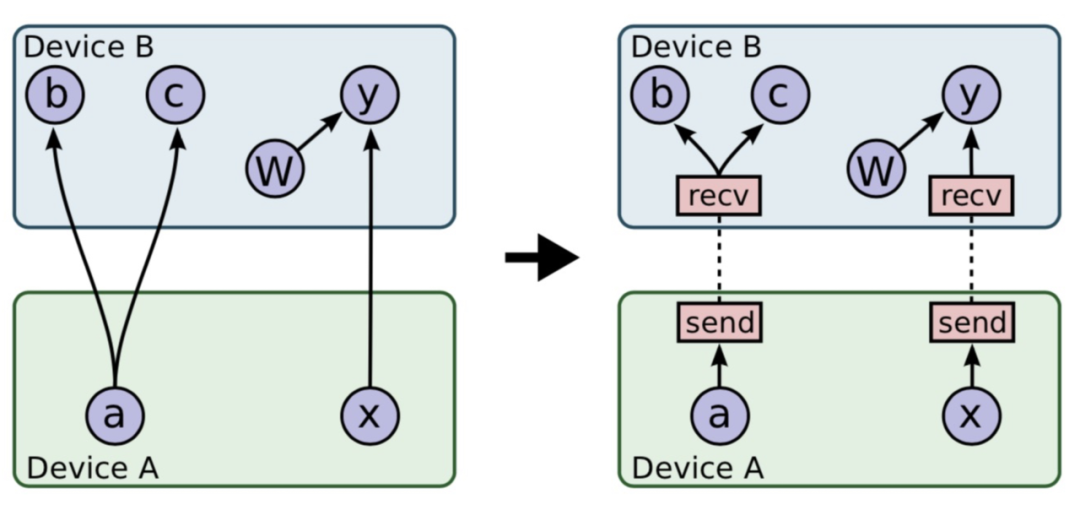
圖12 TensoFlow切圖之Send-Recv對添加基于上圖的切圖邏輯,Recv算子代表著這一側(cè)計算圖有Tensor的需求,而Tensor的生產(chǎn)者則位于與之配對的另一設備上的Send算子背后。在具體實現(xiàn)上,Tensorflow實現(xiàn)了Recv-Driven的數(shù)據(jù)交換模式,如上圖所示,位于DeviceA和DeviceB的兩張計算圖會異步并發(fā)的執(zhí)行,位于DeviceB的Recv執(zhí)行時會發(fā)起一條RPC請求發(fā)往DeviceA,DeviceA收到請求后,會將請求路由到Rendezvous中,如果在當中發(fā)現(xiàn)所需要的數(shù)據(jù)已經(jīng)生產(chǎn)好,并被Send算子注冊了進來,那么就地獲取數(shù)據(jù),返回給DeviceB;如果此時數(shù)據(jù)還沒有生產(chǎn)好,則將來自于DeviceB的Recv請求注冊在Rendezvous中,等待后續(xù)DeviceA生產(chǎn)好后,由Send算子發(fā)送過來,找到注冊的Recv,觸發(fā)回調(diào),返回數(shù)據(jù)給DeviceB。我們看到,匯合點機制優(yōu)雅地解決了生產(chǎn)者消費者節(jié)奏不同情況下數(shù)據(jù)交換的問題。不過Recv-Driven的模式也引入了兩個潛在的問題:
- 據(jù)我們的觀察,在實際業(yè)務模型中,在Rendezvous中Recv算子等待Send算子的比例和Send算子等待Recv算子的比例相當,也就是說對于Send等到Recv的數(shù)據(jù),在Send準備好的那一剎那就可以發(fā)給對端,但是由于機制實現(xiàn)問題,還是等待Recv算子過來,才將數(shù)據(jù)拉取回去,通信過程耗時較長。
- Rendezvous作為一個數(shù)據(jù)交換的熱點,它內(nèi)部的邏輯開銷并不低。
針對上面提到的問題,我們在RDMA上實現(xiàn)了另外一種數(shù)據(jù)交換的模式,叫做Send-Driven模式。與Recv-Driven模式相對,顧名思義就是有Send算子直接將數(shù)據(jù)寫到Recv端,Recv端接收數(shù)據(jù)并注冊到本地Rendezvous中,Recv算子直接從本地的Rendezvous中獲取數(shù)據(jù)。具體流程如下圖13所示:
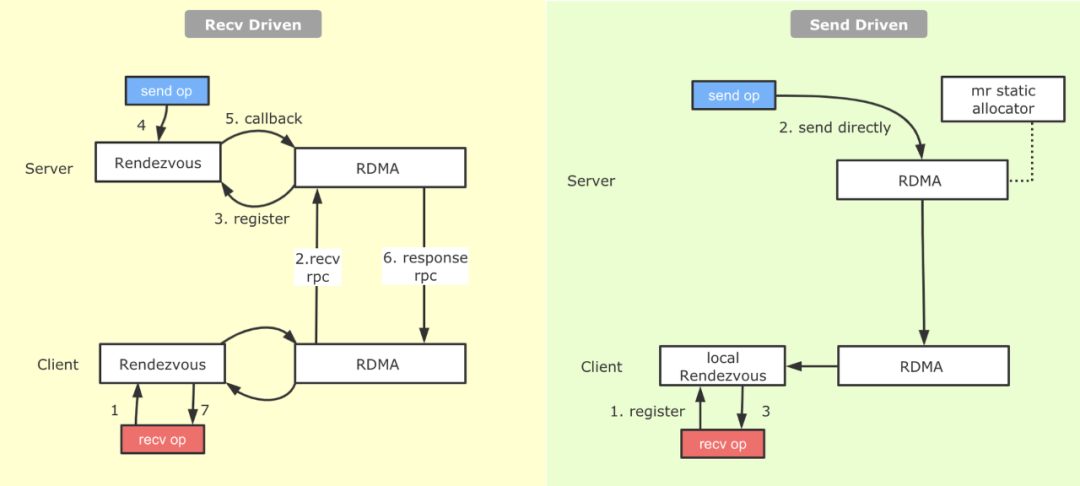
圖13 原生的Recv-Driven與補充的Send-Driven機制從圖中可以看到,相較于Recv-Driven模式,Send-Driven模式的通信流程得到了比較大的簡化,另外在數(shù)據(jù)ready后立即發(fā)送的特性,跳過了一側(cè)的Rendezvous,并且對于生產(chǎn)者先于消費者的情況,可以加快消費端數(shù)據(jù)獲取的速度。
3.4 延遲優(yōu)化
這部分優(yōu)化,也是分布式計算的經(jīng)典優(yōu)化方向。整個流程鏈路上那些可以精簡、合并、重疊需要不斷去挖掘。對于機器學習系統(tǒng)來說,相比其它的系統(tǒng),還可以用一些近似的算法來做這部分工作,從而獲得較大的性能提升。下面介紹我們在兩個這方面做的一些優(yōu)化實踐。
3.4.1 稀疏域參數(shù)聚合
在啟用HashTable存儲稀疏參數(shù)后,對應的,一些配套參數(shù)也需要替換為HashTable實現(xiàn),這樣整個計算圖中會出現(xiàn)多張HashTable以及大量的相關算子。在實踐中,我們發(fā)現(xiàn)需要盡量降低Lookup/Insert等算子的個數(shù),一方面降低PS的負載,一方面降低RPC QPS。因此,針對稀疏模型的常見用法,我們進行了相關的聚合工作。以Adam優(yōu)化器為例,需要創(chuàng)建兩個slot,以保存優(yōu)化中的動量信息,它的Shape與Embedding相同。在原生優(yōu)化器中,這兩個Variable是單獨創(chuàng)建的,并在反向梯度更新的時候會去讀寫。同理,使用HashTable方案時,我們需要同時創(chuàng)建兩張單獨的HashTable用來訓練m、v參數(shù)。那么在前向,反向中需要分別對Embedding、 m、v進行一次Lookup和一次Insert,總共需要三次Lookup和三次Insert。這里一個優(yōu)化點就是將Embedding、 m、v,以及低頻過濾的計數(shù)器(見下圖14的Counting HashTable)聚合到一起,作為HashTable的Value,這樣對稀疏參數(shù)的相關操作就可以聚合執(zhí)行,大大減少了稀疏參數(shù)操作頻次,降低了PS的壓力。
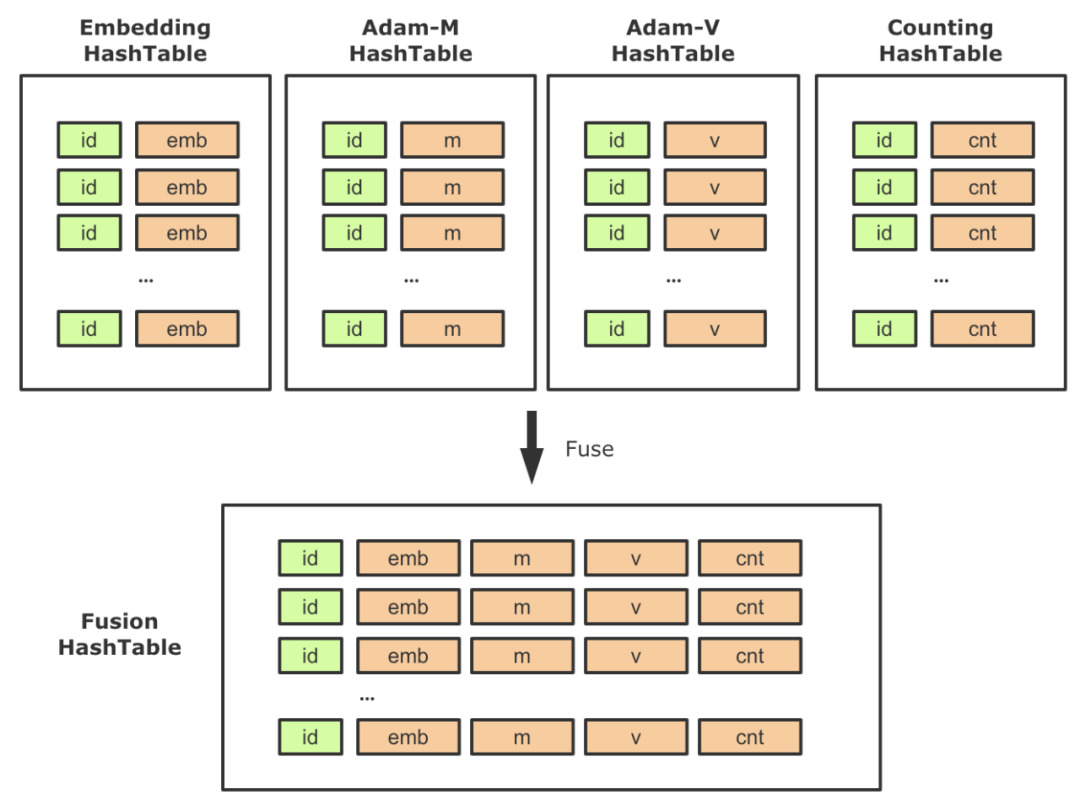
圖14 基于HashTable的參數(shù)融合策略該特性屬于一個普適型優(yōu)化,開啟聚合功能后,訓練速度有了顯著的提高,性能提升幅度隨著模型和Worker規(guī)模的變化,效果總是正向的。在美團內(nèi)部真實業(yè)務模型上,聚合之后性能相比非聚合方式能提升了45%左右。
3.4.2 Embedding流水線優(yōu)化
流水線,在工業(yè)生產(chǎn)中,指每一個生產(chǎn)單位只專注處理某個片段的工作,以提高工作效率及產(chǎn)量的一種生產(chǎn)方式。在計算機領域內(nèi),更為大家熟知的是,流水線代表一種多任務之間Overlap執(zhí)行的并行化技術。例如在典型的RISC處理器中,用戶的程序由大量指令構成,而一條指令的執(zhí)行又可以大致分為:取指、譯碼、執(zhí)行、訪存、寫回等環(huán)節(jié)。這些環(huán)節(jié)會利用到指令Cache、數(shù)據(jù)Cache、寄存器、ALU等多種不同的硬件單元,在每一個指令周期內(nèi),這5個環(huán)節(jié)的硬件單元會并行執(zhí)行,得以更加充分的利用硬件能力,以此提高整個處理器的指令吞吐性能。處理器的指令流水線是一套復雜而系統(tǒng)的底層技術,但其中的思想在分布式深度學習框架中也被大量的使用,例如:
- 如果將分布式訓練簡單的抽象為計算和通信兩個過程,絕大多數(shù)主流的深度學習框架都支持在執(zhí)行計算圖DAG時,通信和計算的Overlap。
- 如果將深度模型訓練簡單的分為前向和反向,在單步內(nèi),由于兩者的強依賴性,無法做到有效并行,字節(jié)BytePS[8]中引入的通信調(diào)度打破了step iteration間的屏障,上一輪的部分參數(shù)更新完畢后,即可提前開始下輪的前向計算,增強了整體視角下前反向的Overlap。
- 百度AIBox[9]為了解決CTR場景GPU訓練時,參數(shù)位于主存,但計算位于GPU的問題,巧妙調(diào)度不同硬件設備,搭建起了主要利用CPU/主存/網(wǎng)卡的參數(shù)預準備階段和主要利用GPU/NVLink的網(wǎng)絡計算階段,通過兩個階段的Overlap達到更高的訓練吞吐。
我們看到,在深度學習框架設計上,通過分析場景,可以從不同的視角發(fā)掘可并行的階段,來提高整體的訓練吞吐。對于大規(guī)模稀疏模型訓練時,核心模型流程是:先執(zhí)行稀疏參數(shù)的Embedding,然后執(zhí)行稠密部分子網(wǎng)絡。其中稀疏參數(shù)Embedding在遠端PS上執(zhí)行,主要耗費網(wǎng)絡資源,而稠密部分子網(wǎng)絡在本地Worker執(zhí)行,主要耗費計算資源。這兩部分占了整個流程的大部分時間,在美團某實際業(yè)務模型上分別耗時占比:40%+、50%+。那我們是否可以提前執(zhí)行稀疏參數(shù)的Embedding,來做到通信和計算的Overlap,隱藏掉這部分時間呢?從系統(tǒng)實現(xiàn)上肯定是可行的,但從算法上講,這樣做會引入?yún)?shù)Staleness的問題,可能會導致模型精度受到影響。但在實際的生產(chǎn)場景中,大規(guī)模異步訓練時本身就會帶來幾十到幾百個步的滯后性問題。經(jīng)過我們測試,提前獲取一兩步的稀疏參數(shù),模型精度并未受到影響。在具體實現(xiàn)上,我們把整個計算圖拆分為Embedding Graph(EG)和Main Graph(MG)兩張子圖,兩者異步獨立執(zhí)行,做到拆分流程的Overlap(整個拆分過程,可以做到對用戶透明)。EG主要覆蓋從樣本中抽取Embedding Key,查詢組裝Embedding向量,Embedding向量更新等環(huán)節(jié)。MG主要包含稠密部分子網(wǎng)絡計算、梯度計算、稠密參數(shù)部分更新等環(huán)節(jié)。
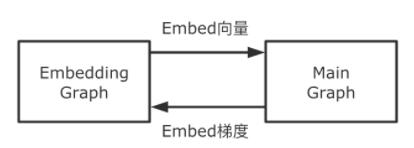

圖15 Embedding流水線模塊交互關系兩張子圖的交互關系為:EG向MG傳遞Embeding向量(從MG的視角看,是從一個稠密Variable讀取數(shù)值);MG向EG傳遞Embedding參數(shù)對應的梯度。上述兩個過程的表達都是TensorFlow的計算圖,我們利用兩個線程,兩個Session并發(fā)的執(zhí)行兩張計算圖,使得兩個階段Overlap起來,以此到達了更大的訓練吞吐。
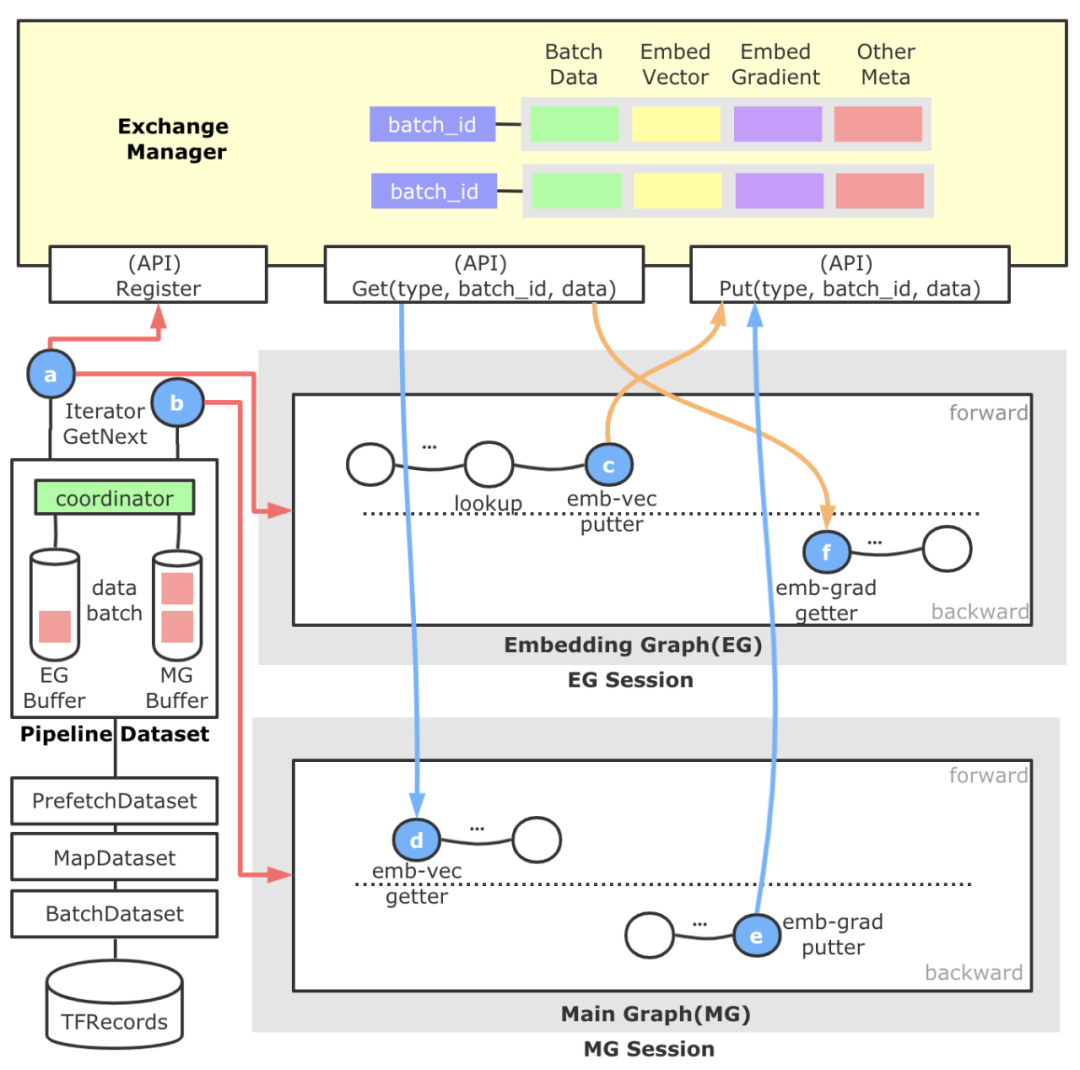
圖16 Embedding流水線架構流程圖上圖是Embedding流水線的架構流程圖。直觀來看分為左側(cè)的樣本分發(fā)模塊,頂部的跨Session數(shù)據(jù)交換模塊,以及自動圖切分得到的Embedding Graph和Main Graph,藍色的圓圈代表新增算子,橙色箭頭代表EG重點流程,藍色箭頭代表MG重點流程,紅色箭頭代表樣本數(shù)據(jù)重點流程。
- 以對用戶透明的形式引入了一層名為Pipeline Dataset的抽象層,這一層的產(chǎn)生是為了滿足EG/MG兩張計算圖以不同節(jié)奏運行的需求,支持自定義配置。另外,為了使得整個流水線中的數(shù)據(jù)做到彼此的配套,這里還會負責進行一個全局Batch ID的生成及注冊工作。Pipeline Dataset對外暴露兩種Iterator,一個供EG使用,一個供MG使用。Pipeline Dataset底部共享TensorFlow原生的各層Dataset。
- 頂部的ExchangeManager是一個靜態(tài)的,跨Session的數(shù)據(jù)交換媒介,對外暴露數(shù)據(jù)注冊和數(shù)據(jù)拉取的能力。抽象這個模塊的原因是,EG和MG原本歸屬于一張計算圖,因為流水線的原因拆解為拆為兩張圖,這樣我們需要建立一種跨Session的數(shù)據(jù)交換機制,并準確進行配套。它內(nèi)部以全局Batch ID做Key,后面管理了樣本數(shù)據(jù)、Embeding向量、Embedding梯度、Unique后的Index等數(shù)據(jù),并負責這些數(shù)據(jù)的生命周期管理。
- 中間的Embedding Graph由獨立的TF Session運行于一個獨立的線程中,通過a算子獲得樣本數(shù)據(jù)后,進行特征ID的抽取等動作,并進行基于HashTable方法的稀疏參數(shù)查詢,查詢結果通過c算子放置到ExchangeManager中。EG中還包含用于反向更新的f算子,它會從ExchangeManager中獲取Embedding梯度和與其配套的前向參數(shù),然后執(zhí)行梯度更新參數(shù)邏輯。
- 下面的Main Graph負責實際稠密子網(wǎng)絡的計算,我們繼承并實現(xiàn)一種可訓練的EmbeddingVariable,它的構建過程(d算子)會從ExchangeManager查找與自己配套的Embedding向量封裝成EmbeddingVariable,給稠密子網(wǎng)絡。此外,在EmbeddingVariable注冊的反向方法中,我們添加了e算子使得Embedding梯度得以添加到ExchangeManager中,供EG中的f算子消費。
通過上面的設計,我們就搭建起了一套可控的EG/MG并發(fā)流水線訓練模式。總體來看,Embedding流水線訓練模式的收益來源有:
- 經(jīng)過我們對多個業(yè)務模型的Profiling分析發(fā)現(xiàn),EG和MG在時間的比例上在3:7或4:6的左右,通過將這兩個階段并行起來,可以有效的隱藏Embedding階段,使得MG網(wǎng)絡計算部分幾乎總是可以立即開始,大大加速了整體模型的訓練吞吐。
- TensorFlow引擎中當使用多個優(yōu)化器(稀疏與非稀疏)的時候,會出現(xiàn)重復構建反向計算圖的問題,一定程度增加了額外計算,通過兩張子圖的拆分,恰好避免了這個問題。
- 在實施過程中的ExchangeManager不僅負責了Embedding參數(shù)和梯度的交換,還承擔了元數(shù)據(jù)復用管理的職責。例如Unique等算子的結果保存,進一步降低了重復計算。
另外,在API設計上,我們做到了對用戶透明,僅需一行代碼即可開啟Embedding流水線功能,對用戶隱藏了EG/MG的切割過程。目前,在美團某業(yè)務訓練中,Embedding流水線功能在CPU PS架構下可以帶來20%~60%的性能提升(而且Worker并發(fā)規(guī)模越大,性能越好)。
3.5 單實例PS并發(fā)優(yōu)化
經(jīng)過2.2章節(jié)的分析可知,我們不能通過持續(xù)擴PS來提升分布式任務的吞吐,單實例PS的并發(fā)優(yōu)化,也是非常重要的優(yōu)化方向。我們主要的優(yōu)化工作如下。
3.5.1 高性能的HashTable
PS架構下,大規(guī)模稀疏模型訓練對于HashTable的并發(fā)讀寫要求很高,因為每個PS都要承擔成百乃至上千個Worker的Embedding壓力,這里我們綜合速度和穩(wěn)定性考慮,選用了tbb::concurrent_hash_map[10]作為底層HashTable表實現(xiàn),并將其包裝成一個新的TBBConcurrentHashTable算子。經(jīng)過測試,在千億規(guī)模下TBBConcurrentHashTable比原生MutableDenseHashTable訓練速度上快了3倍。
3.5.2 HashTable BucketPool
對于大規(guī)模稀疏模型訓練來說,Embedding HashTable會面對大量的并發(fā)操作,通過Profiling我們發(fā)現(xiàn),頻繁動態(tài)的內(nèi)存申請會帶來了較大性能開銷(即使TensorFlow的Tensor有專門的內(nèi)存分配器)。我們基于內(nèi)存池化的思路優(yōu)化了HashTable的內(nèi)存管理。我們在HashTable初始化時,會先為Key和Value分別創(chuàng)造兩個BucketPool,每個池子都會先Malloc較大一塊內(nèi)存?zhèn)溆茫紤]到可能會有對HashTable進行中的Key和Value進行Remove的場景(如Online Learning訓練時),需要對從HashTable中刪除的Key和Value所使用的內(nèi)存進行回收,因此每個BucketPool還有一個ReuseQueue來負責維護回收的內(nèi)存。每次向內(nèi)部的哈希表數(shù)據(jù)結構中Insert Key和Value的時候,Key和Value內(nèi)存和釋放分配都進行池化管理。用這種方式降低了大規(guī)模稀疏訓練中遇到稀疏內(nèi)存分配開銷,整體端到端訓練性能提升了5%左右。
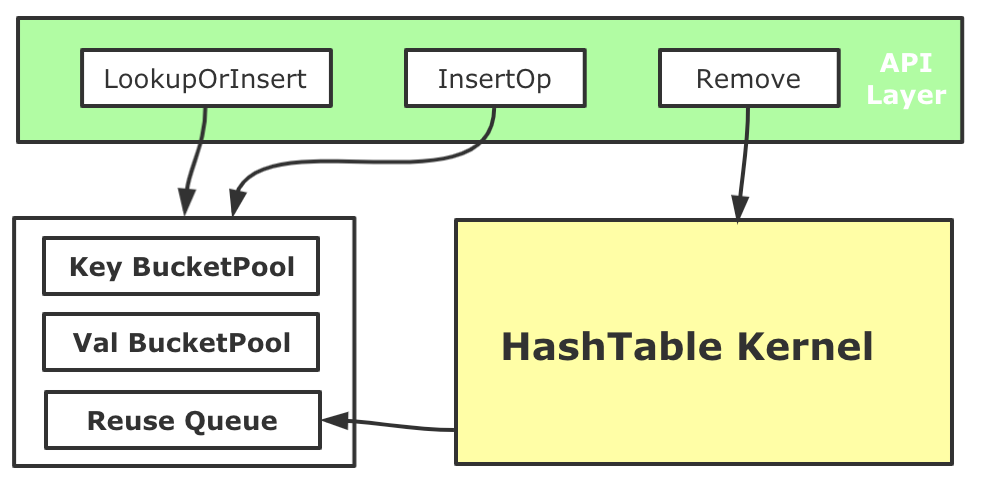
圖17 HashTable內(nèi)存優(yōu)化
3.6 單位算力吞吐優(yōu)化
經(jīng)過2.2章節(jié)的分析,Worker的計算壓力也非常大,如果不優(yōu)化Worker,同時要保持吞吐,需要橫向擴展更多的Worker,給PS帶來更大的壓力。而對于用戶來說,如果能在有限的計算資源下帶來性能提升,對業(yè)務價值更高。我們通過CAT統(tǒng)計出了一些高頻算子,并進行了專項優(yōu)化。這里選取Unique&DynamicPartition算子融合案例進行分享。在TensorFlow PS架構中,包括Embedding向量在內(nèi)的共享參數(shù)都存儲在PS上,并通過網(wǎng)絡與Worker交互,在進行Embedding查詢過程中,往往會涉及如下兩個環(huán)節(jié):
- 由于稀疏參數(shù)的性質(zhì),從樣本中抽取得到的待查詢Embedding ID,它的重復率往往高達70%~90%,如果不進行去重查詢,不論是對HashTable的查詢還是網(wǎng)絡的傳輸,都會帶來不小的壓力。因此,通常會在查詢前進行Unique操作。
- 在大規(guī)模稀疏場景中,為了存儲千億規(guī)模的參數(shù),會有多個PS機器共同承載。而Worker端會負責對查詢請求按照設定的路由規(guī)則進行切分,這里通常會在查詢前進行DynamicPartition動作。
通常這兩個過程會利用TensorFlow既有的算子進行搭建,但在實際使用中,我們發(fā)現(xiàn)它并不是很高效,主要問題在于:
- Unique算子原生實現(xiàn),它內(nèi)部使用的內(nèi)存分配策略較為低效。使用了兩倍輸入?yún)?shù)(Embedding ID)的大小進行內(nèi)存分配,但由于輸入?yún)?shù)較大,而且重復率高,導致HashTable創(chuàng)建過大且非常稀疏。幾乎每次插入都會產(chǎn)生一次minor_page_fault,導致HashTable性能下降。我們使用Intel Vtune驗證了這一點(參見圖18)。
- Unique和Dynamic Partition算子存在冗余數(shù)據(jù)遍歷,這些操作其實可以在一次數(shù)據(jù)遍歷中全部做完,節(jié)省掉算子切換、冗余數(shù)據(jù)遍歷的耗時。

圖18 Unique算子內(nèi)部出現(xiàn)DRAM Bound問題總結來說,HashTable開辟過大會導致大量的minor_page_fault,導致訪存的時間增加,HashTable過小又可能會導致擴容。我們采用了基于啟發(fā)式算法的內(nèi)存自適應Unique算子實現(xiàn),通過對訓練歷史重復率的統(tǒng)計,我們可以得到一個相對合理的HashTable大小,來提高訪存的性能;另外Unique算子內(nèi)HashTable的具體選擇上,經(jīng)過我們的多種測試,選擇了Robin HashTable替換了原生TF中的實現(xiàn)。進一步,我們對圍繞Embedding ID的Unique和Partition環(huán)節(jié)進行了算子合并,簡化了邏輯實現(xiàn)。經(jīng)過上述的優(yōu)化,Unique單算子可以取得51%的加速,在真實模型端到端上可以獲得10%左右的性能提升,算子總數(shù)量降低了4%。在整個關鍵算子優(yōu)化的過程中,Intel公司的林立凡、張向澤、高明進行大量的技術支持,我們也復用了他們的部分優(yōu)化工作,在此深表感謝!
4 大規(guī)模稀疏算法建模
大規(guī)模稀疏能力在業(yè)務落地的過程中,算法層面還需要從特征和模型結構上進行對應升級,才能拿到非常好的效果。其中外賣廣告從業(yè)務特點出發(fā),引入大規(guī)模稀疏特征完成外賣場景下特征體系的升級,提供了更高維的特征空間和參數(shù)空間,增強了模型的擬合能力。重新設計了面向高維稀疏場景的特征編碼方案,解決了特征編碼過程中的特征沖突問題,同時編碼過程去掉了部分冗余的特征哈希操作,一定程度上簡化了特征處理邏輯,并降低了特征計算的耗時。在系統(tǒng)層面,面對百億參數(shù)、百億樣本以上量級的大規(guī)模稀疏模型的訓練,會帶來訓練迭代效率的大大降低,單次實驗從一天以內(nèi),增長到一周左右。美團機器學習平臺訓練引擎團隊,除了上述TensorFlow框架層面的優(yōu)化、還針對業(yè)務模型進行了專項優(yōu)化,整體吞吐優(yōu)化了8到10倍(如果投入更多計算資源,可以進一步加速),大大提升業(yè)務的迭代效率,助力外賣廣告業(yè)務取得了較為明顯的提升。
5 總結與展望
TensorFlow在大規(guī)模推薦系統(tǒng)中被廣泛使用,但由于缺乏大規(guī)模稀疏的大規(guī)模分布式訓練能力,阻礙了業(yè)務的發(fā)展。美團基于TensorFlow原生架構,支持了大規(guī)模稀疏能力,并從多個角度進行了深度優(yōu)化,做到千億參數(shù)、千億樣本高效的分布式訓練,并在美團內(nèi)部進行了大規(guī)模的使用。對于這類關鍵能力的缺失,TensorFlow社區(qū)也引起了共鳴,社區(qū)官方在2020年創(chuàng)建了SIG Recommenders[11],通過社區(qū)共建的方式來解決此類問題,美團后續(xù)也會積極的參與到社區(qū)的貢獻當中去。美團推薦系統(tǒng)場景的模型訓練,目前主要運行在CPU上,但隨著業(yè)務的發(fā)展,有些模型變得越來越復雜,CPU上已經(jīng)很難有優(yōu)化空間(優(yōu)化后的Worker CPU使用率在90%以上)。而近幾年,GPU的計算能力突飛猛進,新一代的NVIDIA A100 GPU,算力達到了156TFLOPS(TF32 Tensor Cores)、80G顯存、卡間帶寬600GB/s。對于這類復雜模型的Workload,我們基于A100 GPU架構,設計了下一代的分布式訓練架構,經(jīng)過初步優(yōu)化,在美團某大流量業(yè)務推薦模型上也拿到了較好的效果,目前還在進一步優(yōu)化當中,后續(xù)我們會進行分享,敬請期待。
6 作者簡介
逸帆、家恒、崢少、鵬鵬、永宇、正陽、黃軍等,來自美團基礎研發(fā)平臺,機器學習平臺訓練引擎組,主要負責美團分布式機器學習訓練系統(tǒng)的性能優(yōu)化與能力建設。
海濤,來自美團外賣廣告策略團隊,主要負責美團外賣廣告業(yè)務的算法探索和策略落地工作。