作者 | 家恒 國慶等
美團(tuán)機(jī)器學(xué)習(xí)平臺基于內(nèi)部深度定制的TensorFlow研發(fā)了Booster GPU訓(xùn)練架構(gòu)。該架構(gòu)在整體設(shè)計上充分考慮了算法、架構(gòu)、新硬件的特性,從數(shù)據(jù)、計算、通信等多個角度進(jìn)行了深度的優(yōu)化,最終其性價比達(dá)到CPU任務(wù)的2~4倍。本文主要講述Booster架構(gòu)的設(shè)計實(shí)現(xiàn)、性能優(yōu)化及業(yè)務(wù)落地工作,希望能對從事相關(guān)開發(fā)的同學(xué)有所幫助或者啟發(fā)。
1 背景
在推薦系統(tǒng)訓(xùn)練場景中,美團(tuán)內(nèi)部深度定制的TenorFlow(簡稱TF)版本[1],通過CPU算力支撐了美團(tuán)內(nèi)部大量的業(yè)務(wù)。但隨著業(yè)務(wù)的發(fā)展,模型單次訓(xùn)練的樣本量越來越多,結(jié)構(gòu)也變得越來越復(fù)雜。以美團(tuán)外賣推薦的精排模型為例,單次訓(xùn)練的樣本量已達(dá)百億甚至千億,一次實(shí)驗要耗費(fèi)上千核,且優(yōu)化后的訓(xùn)練任務(wù)CPU使用率已達(dá)90%以上。為了支持業(yè)務(wù)的高速發(fā)展,模型迭代實(shí)驗的頻次和并發(fā)度都在不斷增加,進(jìn)一步增加了算力使用需求。在預(yù)算有限的前提下,如何以較高的性價比來實(shí)現(xiàn)高速的模型訓(xùn)練,從而保障高效率的模型研發(fā)迭代,是我們迫切需要解決的問題。
近幾年,GPU服務(wù)器的硬件能力突飛猛進(jìn),新一代的NVIDIA A100 80GB SXM GPU服務(wù)器(8卡)[2],在存儲方面可以做到:顯存640GB、內(nèi)存1~2TB、SSD10+TB,在通信方面可以做到:卡間雙向通信600GB/s、多機(jī)通信800~1000Gbps/s,在算力方面可以做到:GPU 1248TFLOPS(TF32 Tensor Cores),CPU 96~128物理核。如果訓(xùn)練架構(gòu)能充分發(fā)揮新硬件的優(yōu)勢,模型訓(xùn)練的成本將會大大降低。但TensorFlow社區(qū)在推薦系統(tǒng)訓(xùn)練場景中,并沒有高效和成熟的解決方案。我們也嘗試使用優(yōu)化后的TensorFlow CPU Parameter Server[3](簡稱PS)+GPU Worker的模式進(jìn)行訓(xùn)練,但只對復(fù)雜模型有一定的收益。NVIDIA開源的HugeCTR[4]雖然在經(jīng)典的深度學(xué)習(xí)模型上性能表現(xiàn)優(yōu)異,但要在美團(tuán)的生產(chǎn)環(huán)境直接使用起來,還需要做較多的工作。
美團(tuán)基礎(chǔ)研發(fā)機(jī)器學(xué)習(xí)平臺訓(xùn)練引擎團(tuán)隊,聯(lián)合到家搜推技術(shù)部算法效能團(tuán)隊、NVIDIA DevTech團(tuán)隊,成立了聯(lián)合項目組。在美團(tuán)內(nèi)部深度定制的TenorFlow以及NVIDIA HugeCTR的基礎(chǔ)上,研發(fā)了推薦系統(tǒng)場景的高性能GPU訓(xùn)練架構(gòu)Booster。目前在美團(tuán)外賣推薦場景中進(jìn)行了部署,多代模型全面對齊算法的離線效果,對比之前,優(yōu)化后的CPU任務(wù),性價比提升了2~4倍。由于Booster對原生TensorFlow接口有較好的兼容性,原TensorFlow CPU任務(wù)只需要一行代碼就可完成遷移。這樣讓Booster可以快速在美團(tuán)多條業(yè)務(wù)線上進(jìn)行初步驗證,相比之前的CPU任務(wù),平均性價比都提升到2倍以上。本文將重點(diǎn)介紹Booster架構(gòu)的設(shè)計與優(yōu)化,以及在美團(tuán)外賣推薦場景落地的全過程,希望能對大家有所幫助或啟發(fā)。
2 GPU訓(xùn)練優(yōu)化挑戰(zhàn)
GPU訓(xùn)練在美團(tuán)內(nèi)已經(jīng)廣泛應(yīng)用到CV、NLP、ASR等場景的深度學(xué)習(xí)模型,但在推薦系統(tǒng)場景中,卻遲遲沒有得到大規(guī)模的應(yīng)用,這跟場景的模型特點(diǎn)、GPU服務(wù)器的硬件特點(diǎn)都有較強(qiáng)的關(guān)系。
推薦系統(tǒng)深度學(xué)習(xí)模型特點(diǎn)
- 讀取樣本量大:訓(xùn)練樣本在幾十TB~幾百TB,而CV等場景通常在幾百GB以內(nèi)。
- 模型參數(shù)量大:同時有大規(guī)模稀疏參數(shù)和稠密參數(shù),需要幾百GB甚至上TB存儲,而CV等場景模型主要是稠密參數(shù),通常在幾十GB以內(nèi)。
- 模型計算復(fù)雜度相對低一些:推薦系統(tǒng)模型在GPU上單步執(zhí)行只需要10~100ms,而CV模型在GPU上單步執(zhí)行是100~500ms,NLP模型在GPU上單步執(zhí)行是500ms~1s。
GPU服務(wù)器特點(diǎn)
- GPU卡算力很強(qiáng),但顯存仍有限:如果要充分發(fā)揮GPU算力,需要把GPU計算用到的各種數(shù)據(jù)提前放置到顯存中。而從2016年~2020年,NVIDIA Tesla GPU卡[5]計算能力提升了10倍以上,但顯存大小只提升了3倍左右。
- 其它維度資源并不是很充足:相比GPU算力的提升速度,單機(jī)的CPU、網(wǎng)絡(luò)帶寬的增長速度較慢,如果遇到這兩類資源負(fù)載較重的模型,將無法充分發(fā)揮GPU的能力,GPU服務(wù)器相比CPU服務(wù)器的性價比不會太高。
總結(jié)來說,CV、NLP等場景的模型訓(xùn)練屬于計算密集型任務(wù),而且大多模型單張卡的顯存都可以裝下,這和GPU服務(wù)器的優(yōu)勢非常好地進(jìn)行了匹配。但在推薦系統(tǒng)場景中,由于模型相對沒有那么復(fù)雜,遠(yuǎn)端讀取的樣本量大,特征處理耗費(fèi)CPU多,給單機(jī)CPU和網(wǎng)絡(luò)帶來較大的壓力。同時面對模型參數(shù)量大的情況,單機(jī)的GPU顯存是無法放下的。這些GPU服務(wù)器的劣勢,恰恰都被推薦系統(tǒng)場景命中。
好在NVIDIA A100 GPU服務(wù)器,在硬件上的升級彌補(bǔ)了顯存、CPU、帶寬這些短板,但如果系統(tǒng)實(shí)現(xiàn)和優(yōu)化不當(dāng),依然不會有太高的性價比收益。在落地Booster架構(gòu)的過程中,我們主要面臨如下挑戰(zhàn):
- 數(shù)據(jù)流系統(tǒng):如何利用好多網(wǎng)卡、多路CPU,實(shí)現(xiàn)高性能的數(shù)據(jù)流水線,讓數(shù)據(jù)的供給可以跟上GPU的消費(fèi)速度。
- 混合參數(shù)計算:對于大規(guī)模稀疏參數(shù),GPU顯存直接裝不下的情況,如何充分利用GPU高算力、GPU卡間的高帶寬,實(shí)現(xiàn)一套大規(guī)模稀疏參數(shù)的計算,同時還需要兼顧稠密參數(shù)的計算。
3 系統(tǒng)設(shè)計與實(shí)現(xiàn)
面對上面的挑戰(zhàn),如果純從系統(tǒng)的的角度去設(shè)計,難度較大。Booster采用了“算法+系統(tǒng)”Co-design的設(shè)計思路,讓這代系統(tǒng)的設(shè)計大大得到簡化。在系統(tǒng)實(shí)施路徑上,考慮到業(yè)務(wù)預(yù)期交付時間、實(shí)施風(fēng)險,我們并沒有一步到位落地Booster的多機(jī)多卡版本,而是第一版先落地了GPU單機(jī)多卡版本,本文重點(diǎn)介紹的也是單機(jī)多卡的工作。另外,依托于NVIDIA A100 GPU服務(wù)器強(qiáng)大的計算能力,單機(jī)的算力可以滿足美團(tuán)絕大多數(shù)業(yè)務(wù)的單次實(shí)驗需求。
3.1 參數(shù)規(guī)模的合理化
大規(guī)模稀疏離散特征的使用,導(dǎo)致深度預(yù)估模型的Embedding參數(shù)量急劇膨脹,數(shù)TB大小的模型一度流行于業(yè)界推搜的各大頭部業(yè)務(wù)場景。但是業(yè)界很快意識到,在硬件成本有限的情況下,過于龐大的模型給生產(chǎn)部署運(yùn)維和實(shí)驗迭代創(chuàng)新增添了沉重的負(fù)擔(dān)。學(xué)術(shù)研究表明[10-13],模型效果強(qiáng)依賴于模型的信息容量,并非參數(shù)量。實(shí)踐證明,前者可以通過模型結(jié)構(gòu)的優(yōu)化來進(jìn)行提升,而后者在保證效果的前提下,尚存有很大的優(yōu)化空間。Facebook在2020年提出了Compositional Embedding[14],實(shí)現(xiàn)推薦模型參數(shù)規(guī)模數(shù)個量級的壓縮。阿里巴巴也發(fā)表了相關(guān)工作[15],將核心業(yè)務(wù)場景的預(yù)估模型由數(shù)TB壓縮至幾十GB甚至更小。總的來看,業(yè)界的做法主要有以下幾種思路:
- 去交叉特征:交叉特征由單特征間做笛卡爾積產(chǎn)生,這會生成巨大的特征ID取值空間和對應(yīng)Embedding參數(shù)表。深度預(yù)估模型發(fā)展至今,已經(jīng)有大量的方法通過模型結(jié)構(gòu)來建模單特征間的交互,避免了交叉特征造成的Embedding規(guī)模膨脹,如FM系列[16]、AutoInt[17]、CAN[18]等。
- 精簡特征:特別是基于NAS的思路,以較低的訓(xùn)練成本實(shí)現(xiàn)深度神經(jīng)網(wǎng)絡(luò)自適應(yīng)特征選擇,如Dropout Rank[19]和FSCD[20]等工作。
- 壓縮Embedding向量數(shù):對特征取值進(jìn)行復(fù)合ID編碼和Embedding映射,以遠(yuǎn)小于特征取值空間的Embedding向量數(shù),來實(shí)現(xiàn)豐富的特征Embedding表達(dá),如Compositional Embedding[14]、Binary Code Hash Embedding[21]等工作。
- 壓縮Embedding向量維度:一個特征Embedding向量的維度決定了其表征信息的上限,但是并非所有的特征取值都有那么大的信息量,需要Embedding表達(dá)。因此,可以每一個特征值自適應(yīng)的學(xué)習(xí)精簡Embedding維度,從而壓縮參數(shù)總量,如AutoDim[22]和AMTL[23]等工作。
- 量化壓縮:使用半精度甚至int8等更激進(jìn)的方式,對模型參數(shù)做量化壓縮,如DPQ[24]和MGQE[25]。
美團(tuán)外賣推薦的模型一度達(dá)到100G以上,通過應(yīng)用以上方案,我們在模型預(yù)估精度損失可控的前提下,將模型控制在10GB以下。基于這個算法基礎(chǔ)假設(shè),我們將第一階段的設(shè)計目標(biāo)定義到支持100G以下的參數(shù)規(guī)模。這可以比較好的適配A100的顯存,存放在單機(jī)多卡上,GPU卡間雙向帶寬600GB/s,可以充分發(fā)揮GPU的處理能力,同時也可以滿足美團(tuán)大多數(shù)模型的需求。
3.2 系統(tǒng)架構(gòu)
基于GPU系統(tǒng)的架構(gòu)設(shè)計,要充分考慮硬件的特性才能充分發(fā)揮性能的優(yōu)勢。我們NVIDIA A100服務(wù)器的硬件拓?fù)浜蚇VIDIA DGX A100[6]比較類似,每臺服務(wù)器包含:2顆CPU,8張GPU,8張網(wǎng)卡。Booster架構(gòu)的架構(gòu)圖如下所示:
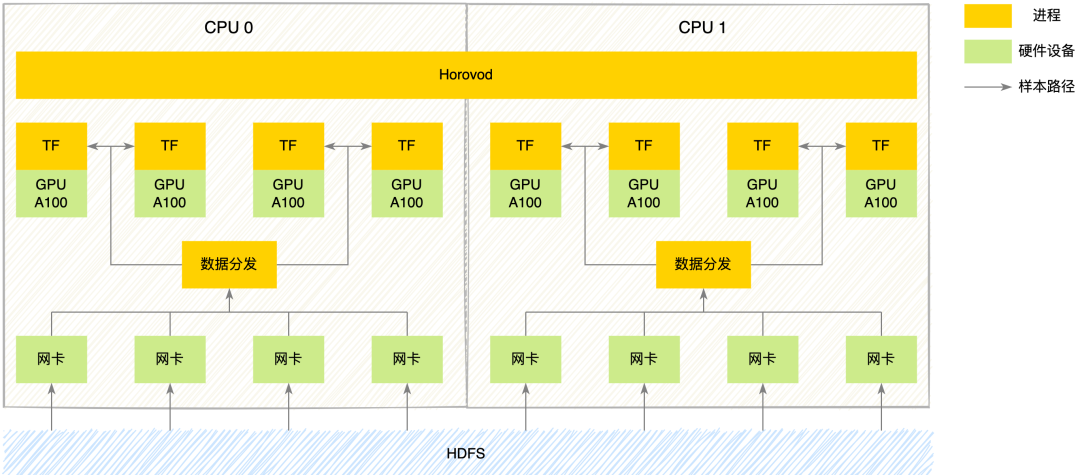
圖1 系統(tǒng)架構(gòu)
整個系統(tǒng)主要包括三個核心模塊:數(shù)據(jù)模塊,計算模塊,通信模塊:
- 數(shù)據(jù)模塊:美團(tuán)自研了一套支持多數(shù)據(jù)源、多框架的數(shù)據(jù)分發(fā)系統(tǒng),在GPU系統(tǒng)上,我們改造數(shù)據(jù)模塊支持了多網(wǎng)卡數(shù)據(jù)下載,以及考慮到NUMA Awareness的特性,在每顆CPU上都部署了一個數(shù)據(jù)分發(fā)服務(wù)。
- 計算模塊:每張GPU卡啟動一個TensorFlow訓(xùn)練進(jìn)程執(zhí)行訓(xùn)練。
- 通信模塊:我們使用了Horovod[7]來做分布式訓(xùn)練的卡間通信,我們在每個節(jié)點(diǎn)上啟動一個Horovod進(jìn)程來執(zhí)行對應(yīng)的通信任務(wù)。
上述的設(shè)計,符合TensorFlow和Horovod原生的設(shè)計范式。幾個核心模塊可以相互解耦,獨(dú)立迭代,而且如果合并開源社區(qū)的最新特性,也不會對系統(tǒng)造成架構(gòu)性的沖擊。
我們再來看一下整個系統(tǒng)的簡要執(zhí)行流程,每張GPU卡上啟動的TensorFlow進(jìn)程內(nèi)部的執(zhí)行邏輯如下圖:
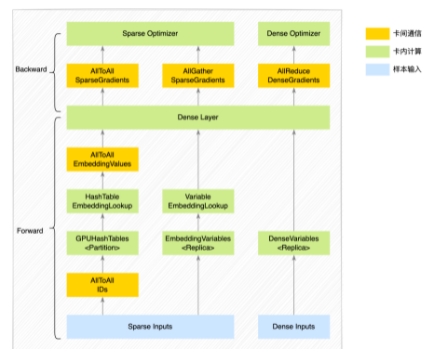
 圖2 進(jìn)程內(nèi)部執(zhí)行邏輯
圖2 進(jìn)程內(nèi)部執(zhí)行邏輯
整個訓(xùn)練流程涉及參數(shù)存儲、優(yōu)化器、卡間通信等幾個關(guān)鍵模塊。對于樣本的輸入特征,我們分為稀疏特征(ID類特征)和稠密特征。在實(shí)際業(yè)務(wù)場景中,稀疏特征通常IDs總量較多,對應(yīng)的稀疏參數(shù)使用HashTable數(shù)據(jù)結(jié)構(gòu)存儲更合適,而且由于參數(shù)量較大,GPU單卡顯存放不下,我們會通過ID Modulo的方式Partition到多張GPU卡的顯存中存放。對于IDs總量較少的稀疏特征,業(yè)務(wù)通常使用多維矩陣數(shù)據(jù)結(jié)構(gòu)表達(dá)(在TensorFlow里面的數(shù)據(jù)結(jié)構(gòu)是Variable),由于參數(shù)量不大,GPU單卡顯存可以放下,我們使用Replica的方式,每張GPU卡的顯存都放置一份參數(shù)。對于稠密參數(shù),通常使用Variable數(shù)據(jù)結(jié)構(gòu),以Replica的方式放置到GPU顯存中。下邊將詳細(xì)介紹Booster架構(gòu)的內(nèi)部實(shí)現(xiàn)。
3.3 關(guān)鍵實(shí)現(xiàn)
3.3.1 參數(shù)存儲
早在CPU場景的PS架構(gòu)下,我們就實(shí)現(xiàn)了大規(guī)模稀疏參數(shù)的整套邏輯,現(xiàn)在要把這套邏輯搬到GPU上,首先要實(shí)現(xiàn)的就是GPU版本的HashTable。我們調(diào)研了業(yè)界多種GPU HashTable的實(shí)現(xiàn),如cuDF、cuDPP、cuCollections、WarpCore等,最終選擇了基于cuCollections實(shí)現(xiàn)TensorFlow版本的GPUHashTable。究其原因,主要是因為實(shí)際業(yè)務(wù)場景中,大規(guī)模稀疏特征的總量通常是未知的,并且隨時可能出現(xiàn)特征交叉,從而致使稀疏特征的總量變化很大,這就導(dǎo)致“動態(tài)擴(kuò)容”能力將成為我們GPU HashTable的必備功能,能夠做到動態(tài)擴(kuò)容的只有cuCollections的實(shí)現(xiàn)。我們在cuCollections的GPU HashTable基礎(chǔ)上實(shí)現(xiàn)了特殊接口(find_or_insert),對大規(guī)模讀寫性能進(jìn)行了優(yōu)化,然后封裝到了TensorFlow中,并在其上實(shí)現(xiàn)了低頻過濾的功能,能力上對齊CPU版本的稀疏參數(shù)存儲模塊。
3.3.2 優(yōu)化器
目前,稀疏參數(shù)的優(yōu)化器與稠密參數(shù)的優(yōu)化器并不兼容,我們在GPU HashTable的基礎(chǔ)上,實(shí)現(xiàn)了多種稀疏優(yōu)化器,并且都做了優(yōu)化器動量Fusion等功能,主要實(shí)現(xiàn)了Adam、Adagrad、FTRL、Momentum等優(yōu)化器。對實(shí)際業(yè)務(wù)場景來說,這些優(yōu)化器已經(jīng)能夠覆蓋到絕大多數(shù)業(yè)務(wù)的使用。稠密部分參數(shù)可以直接使用TensorFlow原生支持的稀疏/稠密優(yōu)化器。
3.3.2 卡間通信
實(shí)際訓(xùn)練期間,對于不同類型的特征,我們的處理流程也有所不同:
- 稀疏特征(ID類特征,規(guī)模較大,使用HashTable存儲):由于每張卡的輸入樣本數(shù)據(jù)不同,因此輸入的稀疏特征對應(yīng)的特征向量,可能存放在其他GPU卡上。具體流程上,訓(xùn)練的前向我們通過卡間AllToAll通信,將每張卡的ID特征以Modulo的方式Partition到其他卡中,每張卡再去卡內(nèi)的GPUHashTable查詢稀疏特征向量,然后再通過卡間AllToAll通信,將第一次AllToAll從其他卡上拿到的ID特征以及對應(yīng)的特征向量原路返回,通過兩次卡間AllToAll通信,每張卡樣本輸入的ID特征都拿到對應(yīng)的特征向量。訓(xùn)練的反向則會再次通過卡間AllToAll通信,將稀疏參數(shù)的梯度以Modulo的方式Partition到其他卡中,每張卡拿到自己的稀疏梯度后再執(zhí)行稀疏優(yōu)化器,完成大規(guī)模稀疏特征的優(yōu)化。詳細(xì)流程如下圖所示:
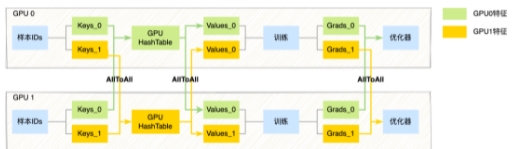
 圖3 稀疏特征處理流程
圖3 稀疏特征處理流程
- 稀疏特征(規(guī)模較小,使用Variable存儲):相比使用HashTable的區(qū)別,由于每張GPU卡都有全量的參數(shù),直接在卡內(nèi)查找模型參數(shù)即可。在反向聚合梯度的時候,會通過卡間AllGather獲取所有卡上的梯度求平均,然后交給優(yōu)化器執(zhí)行參數(shù)優(yōu)化。
- 稠密特征:稠密參數(shù)也是每張卡都有全量的參數(shù),卡內(nèi)可以直接獲取參數(shù)執(zhí)行訓(xùn)練,最后通過卡間AllReduce聚合多卡的稠密梯度,執(zhí)行稠密優(yōu)化器。
在整個的執(zhí)行過程中,稀疏參數(shù)和稠密參數(shù)全部放置在GPU顯存中,模型計算也全部在GPU上處理,GPU卡間通信帶寬也足夠快,能夠充分發(fā)揮了GPU的強(qiáng)大算力。這里小結(jié)一下,Booster訓(xùn)練架構(gòu),與CPU場景PS架構(gòu)的核心區(qū)別在于:
- 訓(xùn)練模式:PS架構(gòu)是異步訓(xùn)練模式,Booster架構(gòu)是同步訓(xùn)練模式。
- 參數(shù)分布:PS架構(gòu)下模型參數(shù)都存放在PS內(nèi)存中,Booster架構(gòu)下稀疏參數(shù)(HashTable)是Partition方式分布在單機(jī)八卡中,稠密參數(shù)(Variable)是Replica方式存放在每張卡中,因此Booster架構(gòu)下的Worker角色兼顧了PS架構(gòu)下PS/Worker角色的功能。
- 通信方式:PS架構(gòu)下PS/Worker間通信走的是TCP(Grpc/Seastar),Booster架構(gòu)下Worker間通信走的是NVSwitch(NCCL),任意兩卡間雙向帶寬600GB/s,這也是Booster架構(gòu)的訓(xùn)練速度取得較大提升的原因之一。
由于每張卡的輸入數(shù)據(jù)不同,并且模型參數(shù)既有在卡間Partition存儲的,也有在卡間Replica存儲的,因此Booster架構(gòu)同時存在模型并行、數(shù)據(jù)并行。此外,由于NVIDIA A100要求CUDA版本>=11.0,而TensorFlow 1.x版本只有NV1.15.4才支持CUDA11.0。美團(tuán)絕大多數(shù)業(yè)務(wù)場景都還在使用TensorFlow 1.x,因此我們所有改造都是在NV1.15.4版本基礎(chǔ)上開發(fā)的。
以上就是Booster整體系統(tǒng)架構(gòu)及內(nèi)部執(zhí)行流程的介紹。下文主要介紹在初步實(shí)現(xiàn)的Booster架構(gòu)的基礎(chǔ)上,我們所做的一些性能優(yōu)化工作。
4 系統(tǒng)性能優(yōu)化
基于上述的設(shè)計實(shí)現(xiàn)完第一版系統(tǒng)后,我們發(fā)現(xiàn)端到端性能并不是很符合預(yù)期,GPU的SM利用率(SM Activity指標(biāo))只有10%~20%,相比CPU并沒有太大的優(yōu)勢。為了分析架構(gòu)的性能瓶頸,我們使用NVIDIA Nsight Systems(以下簡稱nsys)、Perf、uPerf等工具,通過模塊化壓測、模擬分析等多種分析手段,最終定位到數(shù)據(jù)層、計算層、通信層等幾方面的性能瓶頸,并分別做了相應(yīng)的性能優(yōu)化。以下我們將以美團(tuán)外賣某推薦模型為例,分別從GPU架構(gòu)的數(shù)據(jù)層、計算層、通信層,逐個介紹我們所做的性能優(yōu)化工作。
4.1 數(shù)據(jù)層
如前文所述,推薦系統(tǒng)的深度學(xué)習(xí)模型,樣本量大,模型相對不復(fù)雜,數(shù)據(jù)I/O本身就是瓶頸點(diǎn)。如果幾十臺CPU服務(wù)器上的數(shù)據(jù)I/O操作,都要在單臺GPU服務(wù)器上完成,那么數(shù)據(jù)I/O的壓力會變得更大。我們先看一下在當(dāng)前系統(tǒng)下的樣本數(shù)據(jù)流程,如下圖所示:
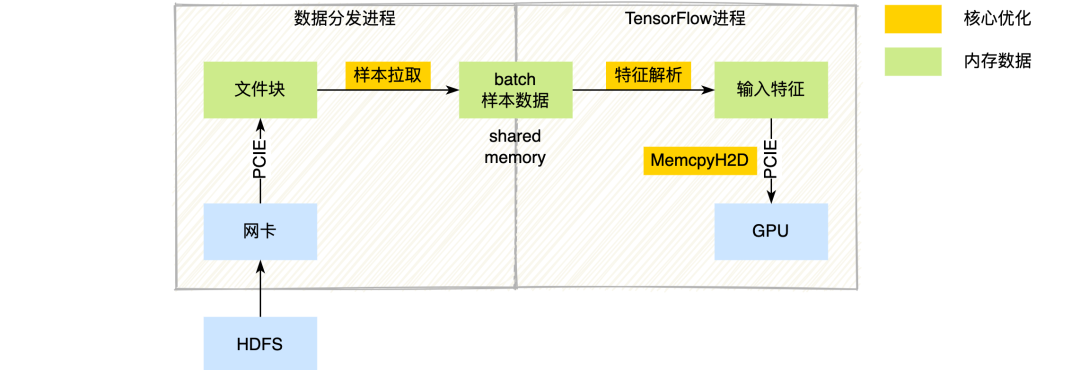 圖4 樣本數(shù)據(jù)流程及核心優(yōu)化
圖4 樣本數(shù)據(jù)流程及核心優(yōu)化
點(diǎn)核心流程:數(shù)據(jù)分發(fā)進(jìn)程通過網(wǎng)絡(luò)讀取HDFS樣本數(shù)據(jù)(TFRecord格式)到內(nèi)存中,然后通過共享內(nèi)存(Shared Memory)的方式把樣本數(shù)據(jù)傳輸給TensorFlow訓(xùn)練進(jìn)程。TensrFlow訓(xùn)練進(jìn)程收到樣本數(shù)據(jù)后,走原生的TensrFlow特征解析邏輯,拿到特征數(shù)據(jù)后通過GPU MemcpyH2D到GPU顯存中。我們通過模塊化壓測分析發(fā)現(xiàn),數(shù)據(jù)分發(fā)層的樣本拉取、TensrFlow層的特征解析以及特征數(shù)據(jù)MemcpyH2D到GPU等幾個流程,都存在較大的性能問題(圖中黃色流程所示),以下詳細(xì)介紹我們在這幾塊所做的性能優(yōu)化工作。
4.1.1 樣本拉取優(yōu)化
樣本拉取、組裝Batch是由數(shù)據(jù)分發(fā)進(jìn)程完成的,我們在這里所做的主要優(yōu)化工作是,首先將數(shù)據(jù)分發(fā)進(jìn)程通過numactl獨(dú)立到NUMA內(nèi)部執(zhí)行,避免了NUMA間的數(shù)據(jù)傳輸;其次,數(shù)據(jù)下載從單網(wǎng)卡擴(kuò)充到了多網(wǎng)卡,增大數(shù)據(jù)下載帶寬;最后,數(shù)據(jù)分發(fā)進(jìn)程與TensrFlow進(jìn)程之間的傳輸通道,從單個Shared Memory擴(kuò)展到每張GPU卡有獨(dú)立的Shared Memory,避免了單Shared Memory所帶來的內(nèi)存帶寬問題,并在TensrFlow內(nèi)部實(shí)現(xiàn)了特征解析時對輸入數(shù)據(jù)零拷貝的能力。
4.1.2 特征解析優(yōu)化
目前,美團(tuán)內(nèi)部絕大多數(shù)業(yè)務(wù)的樣本數(shù)據(jù)都還是TFRecord格式,TFRecord實(shí)際上是ProtoBuf(簡稱PB)格式。PB反序列化非常耗費(fèi)CPU,其中ReadVarint64Fallback方法CPU占用較為突出,實(shí)際profiling結(jié)果如下圖:
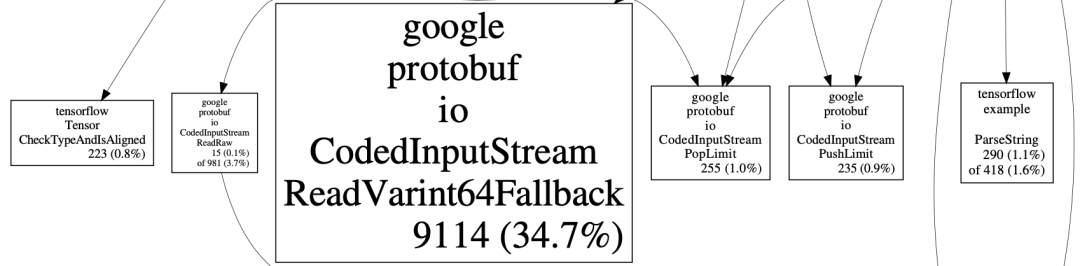
圖5 樣本解析profiling結(jié)果
究其原因,CTR場景的訓(xùn)練樣本通常包含了大量的int64類型的特征,int64在PB中是以Varint64類型數(shù)據(jù)存儲的,ReadVarint64Fallback方法就是用來解析int64類型的特征。普通的int64數(shù)據(jù)類型需要占用8個字節(jié),而Varint64針對不同的數(shù)據(jù)范圍,使用了變長的存儲長度。PB在解析Varint類型數(shù)據(jù)時,首先要確定當(dāng)前數(shù)據(jù)的長度,Varint用7bit存儲數(shù)據(jù),高位1bit存儲標(biāo)記位,該標(biāo)記位表示下一個字節(jié)是否有效,如果當(dāng)前字節(jié)最高位為0,則說明當(dāng)前Varint數(shù)據(jù)在該字節(jié)處結(jié)束。我們實(shí)際業(yè)務(wù)場景的ID特征大多是經(jīng)過Hash后的值,用Varint64類型表達(dá)會比較長,這也就導(dǎo)致在特征解析過程中要多次判斷數(shù)據(jù)是否結(jié)束,以及多次位移和拼接來生成最終數(shù)據(jù),這使得CPU在解析過程中存在大量的分支預(yù)測和臨時變量,非常影響性能。以下是4字節(jié)Varint的解析流程圖:
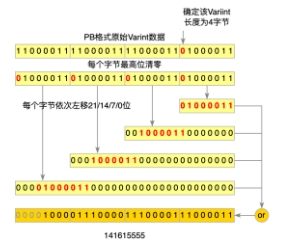
 圖6 ProtoBuf Varint解析流程圖
圖6 ProtoBuf Varint解析流程圖
這個處理流程,非常適合用SIMD指令集批處理優(yōu)化。以4字節(jié)的Varint類型為例,我們的優(yōu)化流程主要包括兩步:
- SIMD尋找最高位:通過SIMD指令將Varint類型數(shù)據(jù)的每個字節(jié)與0xF0做與運(yùn)算,找到第一個結(jié)果等于0的字節(jié),這個字節(jié)就是當(dāng)前Varint數(shù)據(jù)的結(jié)束位置。
- SIMD處理Varint:按理來說,通過SIMD指令將Varint數(shù)據(jù)高位清零后的每個字節(jié)依次右移3/2/1/0字節(jié),就可得到最終的int類型數(shù)據(jù),但SIMD沒有這樣的指令。因此,我們通過SIMD指令分別處理每個字節(jié)的高4bit、低4bit,完成了這個功能。我們將Varint數(shù)據(jù)的高低4bit分別處理成int_h4與int_l4,再做或運(yùn)算,就得到了最終的int類型數(shù)據(jù)。具體優(yōu)化流程如下圖所示(4字節(jié)數(shù)據(jù)):
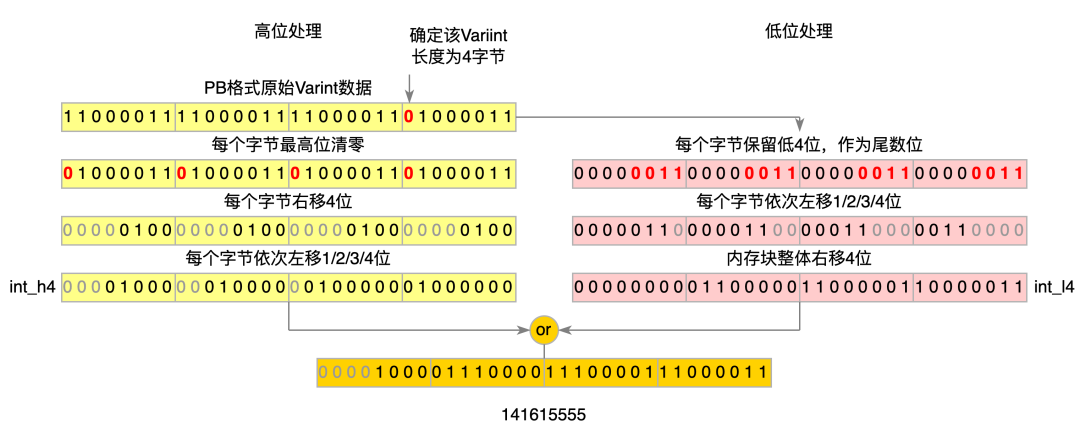
圖7 ProtoBuf Varint解析優(yōu)化后流程圖
對于Varint64類型數(shù)據(jù)的處理,我們直接分成了兩個Varint類型數(shù)據(jù)來處理。通過這兩步的SIMD指令集優(yōu)化,樣本解析速度得到大大提升,在GPU端到端訓(xùn)練速度提升的同時,CPU使用率下降了15%。這里我們主要使用了SSE指令集優(yōu)化,期間也嘗試了AVX等更大長度的指令集,但效果不是很明顯,最終并沒有使用。此外,SIMD指令集在老的機(jī)器上會導(dǎo)致CPU嚴(yán)重降頻,因此官方社區(qū)并沒有引入這個優(yōu)化,而我們GPU機(jī)器的CPU都比較新,完全可以使用SIMD指令集進(jìn)行優(yōu)化。
4.1.3 MemcpyH2D流水線
解析完樣本得到特征數(shù)據(jù)后,需要將特征數(shù)據(jù)拉到GPU中才能執(zhí)行模型計算,這里需要通過CUDA的MemcpyH2D操作。我們通過nsys分析這塊的性能,發(fā)現(xiàn)GPU在執(zhí)行期間有較多的停頓時間,GPU需要等待特征數(shù)據(jù)Memcpy到GPU上之后才能執(zhí)行模型訓(xùn)練,如下圖所示:
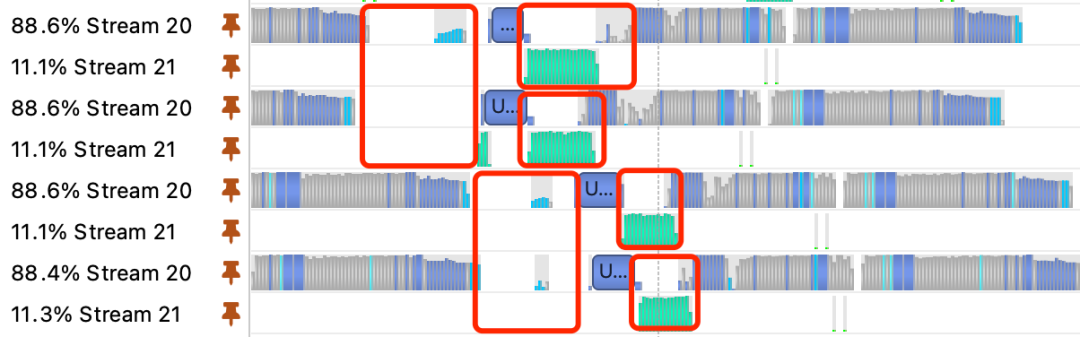
圖8 nsys profiling結(jié)果
對于GPU系統(tǒng)的數(shù)據(jù)流,需要提前傳輸?shù)诫xGPU處理器最近的顯存中,才能發(fā)揮GPU的計算能力。我們基于TensorFlow的prefetch功能,實(shí)現(xiàn)了GPU版本的PipelineDataset,在計算之前先把數(shù)據(jù)拷貝到了GPU顯存中。需要注意的是CPU內(nèi)存拷貝到GPU顯存這個過程,CPU內(nèi)存需要使用Pinned Memory,而非原生的Paged Memory,可以加速M(fèi)emcpyH2D流程。
4.1.4 硬件調(diào)優(yōu)
在數(shù)據(jù)層的性能優(yōu)化期間,美團(tuán)內(nèi)部基礎(chǔ)研發(fā)平臺的服務(wù)器組、網(wǎng)絡(luò)組、操作系統(tǒng)組也幫助我們做了相關(guān)的調(diào)優(yōu):
- 在網(wǎng)絡(luò)傳輸方面,為了減少網(wǎng)絡(luò)協(xié)議棧處理開銷,提高數(shù)據(jù)拷貝的效率,我們通過優(yōu)化網(wǎng)卡配置,開啟LRO(Large-Receive-Offload)、TC Flower的硬件卸載、Tx-Nocache-Copy等特性,最終網(wǎng)絡(luò)帶寬提升了17%。
- 在CPU性能優(yōu)化方面,經(jīng)過性能profiling分析,發(fā)現(xiàn)內(nèi)存延遲和帶寬是瓶頸。于是我們嘗試了3種NPS配置,綜合業(yè)務(wù)場景和NUMA特性,選擇了NPS2。此外,結(jié)合其他BIOS配置(例如APBDIS,P-state等),可以將內(nèi)存延遲降低8%,內(nèi)存帶寬提升6%。
通過上述優(yōu)化,網(wǎng)絡(luò)極限帶寬提升了80%,在業(yè)務(wù)需求帶寬下GPU的H2D帶寬提升了86%。最終在數(shù)據(jù)解析層面也拿到了10%+的性能收益。經(jīng)過數(shù)據(jù)層樣本拉取、特征解析、MemcpyH2D和硬件的優(yōu)化,Booster架構(gòu)端到端訓(xùn)練速度提升了40%,訓(xùn)練性價比達(dá)到了CPU的1.4倍,數(shù)據(jù)層也不再成為當(dāng)前架構(gòu)的性能瓶頸。
4.2 計算層
4.2.1 Embedding流水線
早在CPU場景做TensorFlow訓(xùn)練性能優(yōu)化時,我們就已經(jīng)實(shí)現(xiàn)了Embedding Pipeline[1]的功能:我們把整個計算圖拆分為Embedding Graph(EG)和Main Graph(MG)兩張子圖,兩者異步獨(dú)立執(zhí)行,做到執(zhí)行上的Overlap(整個拆分過程,可以做到對用戶透明)。EG主要覆蓋從樣本中抽取Embedding Key,查詢組裝Embedding向量,Embedding向量更新等環(huán)節(jié);MG主要包含稠密部分子網(wǎng)絡(luò)計算、梯度計算、稠密參數(shù)部分更新等環(huán)節(jié)。
圖9 Embedding流水線模塊交互關(guān)系
兩張子圖的交互關(guān)系為:EG向MG傳遞Embedding向量(從MG的視角看,是從一個稠密Variable讀取數(shù)值),MG向EG傳遞Embedding參數(shù)對應(yīng)的梯度。上述兩個過程的表達(dá)都是TensorFlow的計算圖,我們利用兩個Python線程,兩個TensorFlow Session并發(fā)的執(zhí)行兩張計算圖,使得兩個階段Overlap起來,以此達(dá)到了更大的訓(xùn)練吞吐。我們把這個流程在GPU架構(gòu)下也實(shí)現(xiàn)了一遍,并在其中加入了卡間同步流程,大規(guī)模稀疏特征的AllToAll通信及其反向梯度的AllToAll通信都在EG中執(zhí)行,普通稀疏特征的反向梯度的卡間AllGather同步、稠密參數(shù)的反向梯度的卡間AllReduce同步都在MG中執(zhí)行。需要注意的是,在GPU場景中,EG、MG是在同一個GPU Stream上執(zhí)行CUDA Kernel的,我們嘗試過EG、MG分別在獨(dú)立的GPU Stream上執(zhí)行,性能會變差,深層原因與CUDA底層實(shí)現(xiàn)有關(guān),這個問題本身還在等待解決。
4.2.2 算子優(yōu)化及XLA
相比CPU層面的優(yōu)化,GPU上的優(yōu)化更加復(fù)雜。首先對于TensorFlow的算子,還有一些沒有GPU的實(shí)現(xiàn),當(dāng)模型中使用了這些CPU算子,會跟上下游的GPU算子出現(xiàn)內(nèi)存和顯存之間的數(shù)據(jù)來回拷貝,影響整體性能,我們在GPU上實(shí)現(xiàn)了使用較為頻繁、影響較大的算子。另外,對于TensorFlow這代框架,算子粒度是非常細(xì)的,可以方便用戶靈活搭建各種復(fù)雜的模型,但這對GPU處理器來說卻是一個災(zāi)難,大量的Kernel Launch以及訪存開銷導(dǎo)致不能充分利用GPU算力。對于GPU上的優(yōu)化,通常有兩個方向,手工優(yōu)化和編譯優(yōu)化。在手工優(yōu)化方面,我們重新實(shí)現(xiàn)了一些常用的算子和層(Unique、DynamicPartition、Gather等)。以Unique算子為例,原生TensorFlow的Unique算子要求輸出元素的順序與輸入元素的順序一致,而在實(shí)際場景中,我們并不需要這個限制,我們修改了Unique算子的GPU實(shí)現(xiàn),減少了因輸出有序?qū)е碌念~外執(zhí)行的GPU Kernel。在編譯優(yōu)化方面,目前我們主要使用TensorFlow社區(qū)提供的XLA[9]來做一些自動優(yōu)化。原生TensorFlow 1.15中的XLA正常開啟可獲得10~20%端到端的性能提升。但XLA對算子動態(tài)shape不能很好地進(jìn)行支持,而推薦系統(tǒng)場景的模型中這種情況卻非常常見,這就導(dǎo)致XLA加速性能不符合預(yù)期,甚至是負(fù)優(yōu)化,因此我們做了如下的緩解工作:
- 局部優(yōu)化:對于我們手動引入的動態(tài)shape算子(如Unique),我們進(jìn)行了子圖標(biāo)記,不執(zhí)行XLA編譯,XLA只優(yōu)化可以穩(wěn)定加速的子圖。
- OOM兜底:XLA會根據(jù)算子的type、input type、shape等信息,緩存編譯中間結(jié)果,避免重復(fù)編譯。然而由于稀疏場景以及GPU架構(gòu)實(shí)現(xiàn)的特殊性,天然存在Unique、DynamicPartition等Output shape是動態(tài)的算子,這就導(dǎo)致這些算子以及連接在這些算子之后的算子,在執(zhí)行XLA編譯時無法命中XLA緩存而重新編譯,新的緩存越來越多,而舊的緩存不會被釋放,最終導(dǎo)致CPU內(nèi)存OOM。我們在XLA內(nèi)部實(shí)現(xiàn)了LRUCache,主動淘汰掉舊的XLA緩存,避免OOM的問題。
- Const Memcpy消除:XLA在使用TF_HLO重寫TensorFlow算子時,對一些編譯期已固定的數(shù)據(jù)會打上Const標(biāo)記,然而這些Const算子的Output只能定義在Host端,為了將Host端的Output送給Device端需要再加一次MemcpyH2D,這就占用了TensorFlow原有的H2D Stream,影響樣本數(shù)據(jù)提前拷貝到GPU端。由于XLA的Const Output在編譯期已經(jīng)固化,因此沒有必要每一步都做一次MemcpyH2D,我們將Device端的Output緩存下來,后續(xù)使用該Output時,直接從緩存中讀取,避免多余的MemcpyH2D。
對于XLA的優(yōu)化,確切的來說應(yīng)該是問題修復(fù),目前能夠做到的是GPU場景下可以正常開啟XLA,并獲得10~20%的訓(xùn)練速度提升。值得一提的是,對于動態(tài)shape的算子編譯問題,美團(tuán)內(nèi)部基礎(chǔ)研發(fā)機(jī)器學(xué)習(xí)平臺/深度學(xué)習(xí)編譯器團(tuán)隊已經(jīng)有了徹底的解決方案,后續(xù)我們會聯(lián)合解決這個問題。經(jīng)過計算層的Embedding流水線、XLA相關(guān)優(yōu)化,Booster架構(gòu)端到端訓(xùn)練速度提升了60%,GPU單機(jī)八卡訓(xùn)練性價比達(dá)到同等資源下CPU的2.2倍。
4.3 通信層
在單機(jī)多卡訓(xùn)練過程中,我們通過Nsight Systems分析發(fā)現(xiàn),卡間通信耗時占比非常高,而且在此期間GPU使用率也非常低,如下圖所示: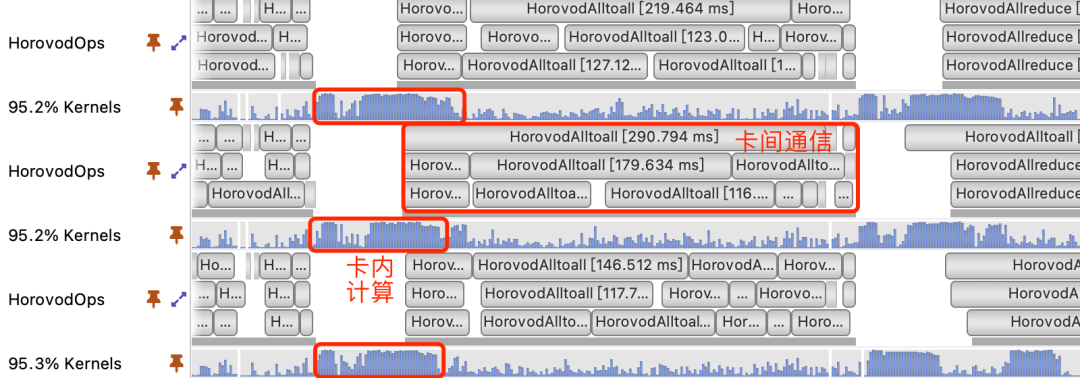
圖10 nsys profiling結(jié)果
從圖中可以看出,訓(xùn)練期間卡間通信耗時比較長,同時在通信期間GPU使用率也非常低,卡間通信是影響訓(xùn)練性能提升的關(guān)鍵瓶頸點(diǎn)。我們對通信過程進(jìn)行拆解打點(diǎn)后發(fā)現(xiàn),卡間通信(AllToAll、AllReduce、AllGather等)協(xié)商的時間遠(yuǎn)遠(yuǎn)高于數(shù)據(jù)傳輸?shù)臅r間:
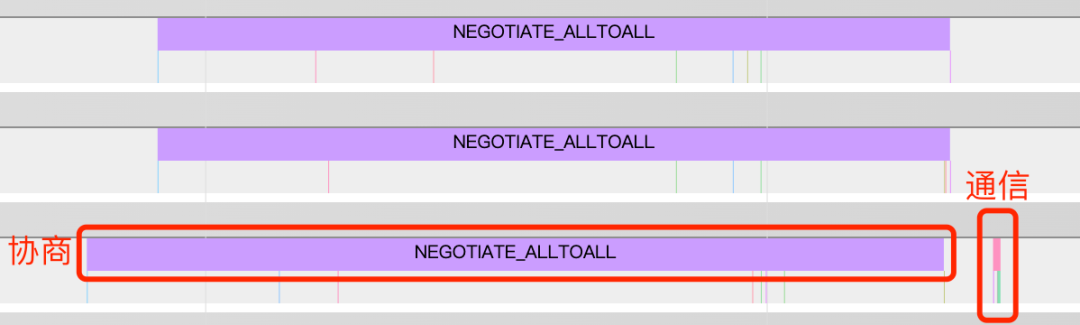
圖11 Horovod timeline結(jié)果
分析具體原因,以負(fù)責(zé)大規(guī)模稀疏參數(shù)通信的AllToAll為例,我們通過Nsight Systems工具,觀察到通信協(xié)商時間長主要是由于某張卡上的算子執(zhí)行時間比較晚導(dǎo)致的。由于TensorFlow算子調(diào)度并不是嚴(yán)格有序,同一個特征的embedding_lookup算子,在不同卡上真正執(zhí)行的時間點(diǎn)也不盡相同,某張卡上第一個執(zhí)行embedding_lookup算子在另一張卡上可能是最后一個執(zhí)行,因此我們懷疑不同卡上算子調(diào)度的不一致性,導(dǎo)致了各張卡發(fā)起通信的時刻不同,并最終導(dǎo)致了通信協(xié)商時間過長。我們通過幾組模擬實(shí)驗也論證了確實(shí)是由算子調(diào)度導(dǎo)致的。對于這個問題,最直接的想法是改造TensorFlow計算圖的核心調(diào)度算法,但這個問題在學(xué)術(shù)界也一直是一個復(fù)雜的問題。我們換了一種思路,通過融合關(guān)鍵的算子,來緩解這個問題,通過統(tǒng)計,我們選擇了HashTable和Variable相關(guān)的算子。
4.3.1 HashTable相關(guān)算子融合
我們設(shè)計和實(shí)現(xiàn)了一個圖優(yōu)化過程,這個過程會自動地將圖中可以合并的HashTable及對應(yīng)的embedding_lookup過程進(jìn)行合并,合并策略上主要將embedding_size相同的HashTable合并到一塊。同時為了避免HashTable合并之后原始特征之間發(fā)生ID沖突,我們引入了自動統(tǒng)一特征編碼的功能,對不同的原始特征分別加上不同的偏移量,歸入不同的特征域,實(shí)現(xiàn)了訓(xùn)練時的統(tǒng)一特征編碼。我們在某實(shí)際業(yè)務(wù)模型上進(jìn)行測試,該圖優(yōu)化將38張HashTable合并成為了2張HashTable,將38次embedding_lookup合并成了2次,這將EmbeddingGraph中的embedding_lookup相關(guān)算子數(shù)量減少了90%,卡間同步通信次數(shù)減少了90%。此外,算子合并之后,embedding_lookup中的GPU算子也發(fā)生了合并,減少了Kernel Launch次數(shù),使得EmbeddingGraph的執(zhí)行速度變得更快。
4.3.2 Variable相關(guān)算子融合
類似于HashTable Fusion的優(yōu)化思路,我們觀察到業(yè)務(wù)模型中通常包含數(shù)十至數(shù)百個TensorFlow原生的Variable,這些Variable在訓(xùn)練期間梯度需要做卡間同步,同樣的,Variable數(shù)量太多導(dǎo)致卡間同步的協(xié)商時間變長。我們通過Concat/Split算子,將所有的Trainable Variables自動合并到一起,使得整個MG的反向只產(chǎn)生幾個梯度Tensor,大大減少了卡間同步的次數(shù)。同時,做完Variable Fusion之后,優(yōu)化器中實(shí)際執(zhí)行的算子數(shù)量也大大減少,加快了計算圖本身的執(zhí)行速度。需要注意的是,TensorFlow的Variable分為兩種,一種是每個Step全部參數(shù)值都參與訓(xùn)練的Dense Variable,如MLP的Weight;另一種是專門用于embedding_lookup的Variable,每個Step只有部分值參與訓(xùn)練,我們稱之為Sparse Variable。對于前者,做Variable合并不會影響到算法效果。而對于后者,它反向梯度是IndexedSlices對象,卡間同步默認(rèn)走的是AllGather通信,如果業(yè)務(wù)模型中對于Sparse Variables的優(yōu)化采用的是Lazy優(yōu)化器,即每個Step只優(yōu)化更新Variable中的某些行,此時對Sparse Variables做合并,會導(dǎo)致其反向梯度從IndexedSlices對象轉(zhuǎn)為Tensor對象,卡間同步變成AllReduce過程,就可能會影響到算法效果。對于這種情況,我們提供了一個開關(guān),由業(yè)務(wù)去控制是否合并Sparse Variables。經(jīng)過我們的實(shí)測,在某推薦模型上合并Sparse Variables會提高5~10%的訓(xùn)練性能,而對實(shí)際業(yè)務(wù)效果的影響在一個千分點(diǎn)以內(nèi)。這兩種算子融合的優(yōu)化,不僅優(yōu)化了卡間通信性能,對卡內(nèi)計算性能也有一定的提升。經(jīng)過這兩種算子融合的優(yōu)化,GPU架構(gòu)端到端訓(xùn)練速度提升了85%,同時不影響業(yè)務(wù)算法的效果。
4.4 性能指標(biāo)
完成了數(shù)據(jù)層、計算層、通信層的性能優(yōu)化后,對比我們的TensorFlow[3] CPU場景,GPU架構(gòu)取得了2~4倍的性價比收益(不同業(yè)務(wù)模型收益不同)。我們基于美團(tuán)外賣某推薦模型,使用單臺GPU節(jié)點(diǎn)(A100單機(jī)八卡)和同成本的CPU Cluster,分別對比了原生TensorFlow 1.15和我們優(yōu)化后的TensorFlow 1.15的訓(xùn)練性能,具體數(shù)據(jù)如下:
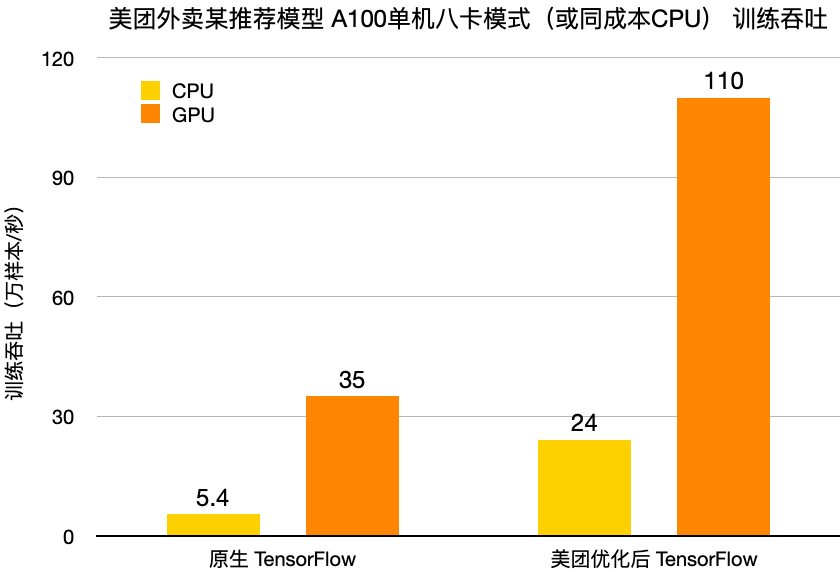
圖12 CPU/GPU訓(xùn)練吞吐對比
可以看到,我們優(yōu)化后的TensorFlow GPU架構(gòu)訓(xùn)練吞吐,是原生TensorFlow GPU的3倍以上,是優(yōu)化后TensorFlow CPU場景的4倍以上。注:原生TensorFlow使用了tf.Variable作為Embedding的參數(shù)存儲。
5 業(yè)務(wù)落地
Booster架構(gòu)要在業(yè)務(wù)生產(chǎn)中落地,不只是要有一個良好的系統(tǒng)性能,還需要同時關(guān)注訓(xùn)練生態(tài)系統(tǒng)的完備性以及訓(xùn)練產(chǎn)出模型的效果。
5.1 完備性
一次完整的模型訓(xùn)練實(shí)驗,除了要跑訓(xùn)練(Train)任務(wù)外,往往還需要跑模型的效果評估(Evaluate)或模型的預(yù)估(Predict)任務(wù)。我們基于TensorFlow Estimator范式對訓(xùn)練架構(gòu)進(jìn)行封裝,實(shí)現(xiàn)用戶側(cè)一套代碼統(tǒng)一支持GPU和CPU場景下的Train、Evaluate和Predict任務(wù),通過開關(guān)進(jìn)行靈活切換,用戶只需要關(guān)注模型代碼本身的開發(fā)。我們將架構(gòu)改動全都封裝到了引擎內(nèi)部,用戶只需要一行代碼就能從CPU場景遷移到GPU架構(gòu):
tf.enable_gpu_booster()
實(shí)際業(yè)務(wù)場景,用戶通常會使用train_and_evaluate模式,在跑訓(xùn)練任務(wù)的過程中同時評估模型效果。上了Booster架構(gòu)后,由于訓(xùn)練跑的太快,導(dǎo)致Evaluate速度跟不上訓(xùn)練正常產(chǎn)出Checkpoint的速度。我們在GPU訓(xùn)練架構(gòu)的基礎(chǔ)上,支持了Evaluate on GPU的能力,業(yè)務(wù)可以申請一顆A100 GPU專門用來做Evaluate,單顆GPU做Evaluate的速度是CPU場景下單個Evaluate進(jìn)程的40倍。同時,我們也支持了Predict on GPU的能力,單機(jī)八卡Predict的速度是同等成本下CPU的3倍。此外,我們在任務(wù)資源配置上也提供了比較完善的選項。在單機(jī)八卡(A100單臺機(jī)器至多配置8張卡)的基礎(chǔ)上,我們支持了單機(jī)單卡、雙卡、四卡任務(wù),并打通了單機(jī)單卡/雙卡/四卡/八卡/CPU PS架構(gòu)的Checkpoint,使得用戶能夠在這幾種訓(xùn)練模式間自由切換、斷點(diǎn)續(xù)訓(xùn),方便用戶選擇合理的資源類型、資源量跑實(shí)驗,同時業(yè)務(wù)也能夠從已有模型的Checkpoint來WarmStart訓(xùn)練新的模型。
5.2 訓(xùn)練效果
相較PS/Worker異步模式的CPU訓(xùn)練,單機(jī)多卡訓(xùn)練時卡間是全同步的,因而避免了異步訓(xùn)練梯度更新延遲對訓(xùn)練效果的影響。然而,由于同步模式下每一步迭代的實(shí)際Batch Size是每張卡樣本數(shù)的總和,并且為了充分利用A100卡的算力,我們會將每張卡的Batch Size(單步迭代的樣本數(shù))盡量調(diào)大。這使得實(shí)際訓(xùn)練的Batch Size(1萬~10萬)比PS/Worker異步模式(1千~1萬)大很多。我們需要面臨大Batch下訓(xùn)練超參調(diào)優(yōu)的問題[26,27]:在保證Epoch不變的前提下,擴(kuò)大Batch Size會導(dǎo)致參數(shù)有效更新次數(shù)減少,可能導(dǎo)致模型訓(xùn)練的效果變差。我們采用Linear Scaling Rule[28]的原則指導(dǎo)調(diào)整學(xué)習(xí)率。如果訓(xùn)練Batch Size較PS/Worker模式的Batch Size增大N倍,將學(xué)習(xí)率也放大N倍即可。這種方式簡單便于操作,實(shí)踐效果還不錯。當(dāng)然需要注意的是,如果原有訓(xùn)練方式的學(xué)習(xí)率已經(jīng)很激進(jìn)時,大Batch Size訓(xùn)練學(xué)習(xí)率的調(diào)整幅度則需要適當(dāng)減小,或者使用學(xué)習(xí)率Warmup等更復(fù)雜的訓(xùn)練策略[29]。我們會在后續(xù)工作中對超參優(yōu)化模式做更深入的探索。
6 總結(jié)與展望
在美團(tuán)推薦系統(tǒng)訓(xùn)練場景,隨著模型越來越復(fù)雜,CPU上優(yōu)化的邊際效應(yīng)越來越低。美團(tuán)基于內(nèi)部深度定制的TensorFlow、NVIDIA HugeCTR,研發(fā)了Booster GPU訓(xùn)練架構(gòu)。整體設(shè)計充分考慮算法、架構(gòu)、新硬件的特性,并從數(shù)據(jù)、計算、通信等多個角度深度優(yōu)化,對比之前CPU的任務(wù),性價比提升到2~4倍。從功能和完備性上支持TensorFlow的各類訓(xùn)練接口(Train/Evaluate/Rredict等),支持CPU和GPU模型相互導(dǎo)入。易用性上TensorFlow CPU任務(wù)只需要一行代碼就可完成GPU架構(gòu)遷移。目前在美團(tuán)外賣推薦場景實(shí)現(xiàn)了大規(guī)模的投產(chǎn)應(yīng)用,后續(xù)我們將會全面推廣到到家搜索推薦技術(shù)部以及美團(tuán)全業(yè)務(wù)線。當(dāng)然,Booster基于NVIDIA A100單機(jī)多卡還有不少優(yōu)化空間,如數(shù)據(jù)層面的樣本壓縮、序列化、特征解析,計算層面的多圖算子調(diào)度、動態(tài)shape算子的編譯優(yōu)化,通信層面的量化通信等等。同時為了更廣泛的支持美團(tuán)內(nèi)的業(yè)務(wù)模型,Booster的下一個版本也會支持更大的模型,以及多機(jī)多卡的GPU訓(xùn)練。
7 作者簡介
家恒、國慶、崢少、曉光、鵬鵬、永宇、俊文、正陽、瑞東、翔宇、秀峰、王慶、封宇、事峰、黃軍等,來自美團(tuán)基礎(chǔ)研發(fā)平臺-機(jī)器學(xué)習(xí)平臺訓(xùn)練引擎&到家研發(fā)平臺-搜索推薦技術(shù)部Booster聯(lián)合項目組。