讓圖網絡更穩健!谷歌提出SR-GNN,無懼數據標記偏差和領域轉移
圖神經網絡(GNN),是在機器學習中利用圖形結構數據的強大工具。圖是一種靈活的數據結構,可以對許多不同類型的關系進行建模,并已被用于不同的應用,如交通預測、謠言和假新聞檢測、疾病傳播建模等。
作為機器學習的標準之一,GNN假設訓練樣本是均勻隨機選擇的(即獨立和相同分布樣本)。這個假設對于標準的學術數據集來說是很容易符合的,這些數據集專門為研究分析而創建,每個數據節點都已經被標記。
但是在許多現實世界的場景中,數據是沒有標簽的,實際上,對數據的標記往往是一個繁重的過程,需要熟練的真人審核和把關,所以,要標記所有數據節點是一個非常困難的任務。
此外,訓練數據的偏見也是一個常見問題,因為選擇節點進行數據標記的行為通常不是上文所說的「均勻隨機選擇」。
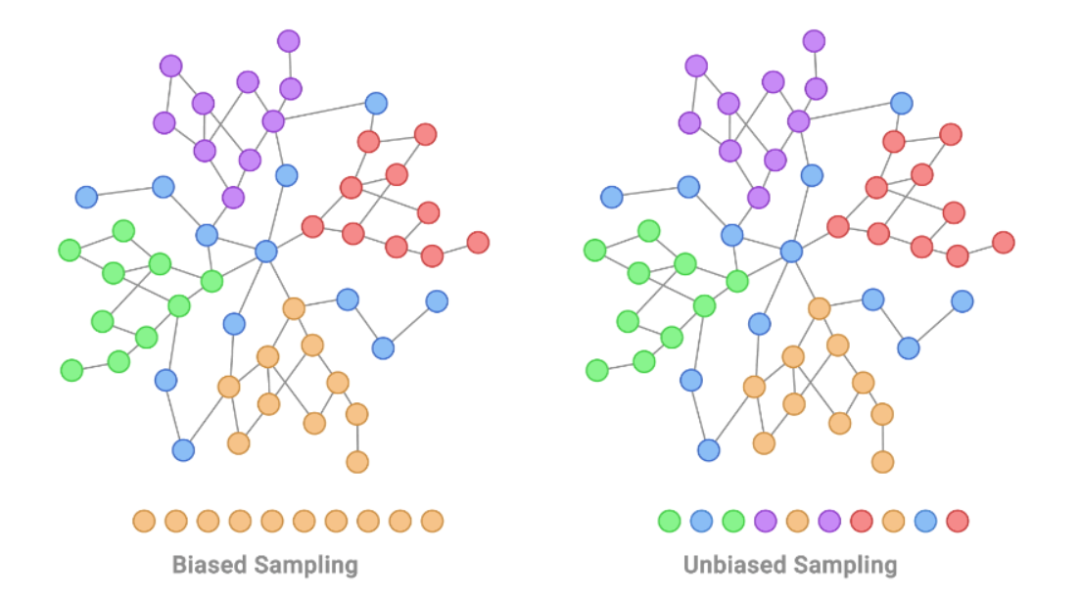
比如,有時會使用固定的啟發式方法來選擇一個數據子集(子集中的數據具備一些共同的特征)進行標注,還有的時候,人類分析員會利用復雜的領域知識,單獨選擇某些特定數據項進行標注。
為了量化訓練集中存在的偏差量,我們可以使用一些方法來衡量兩個不同的概率分布之間的轉變有多大,轉變的大小可以被認為是偏差量。
這種偏差量越大,機器學習模型從存在偏見的訓練集中歸納出特征的難度就越大。可能會有顯著損害模型泛化能力。在學術數據集中,一些領域轉移會導致模型性能下降15-20%(以F1分數為量度)。

論文鏈接:https://proceedings.neurips.cc/paper/2021/file/eb55e369affa90f77dd7dc9e2cd33b16-Paper.pdf
為了解決這個問題,谷歌在NeurIPS 2021上介紹了一種在有偏見的數據上使用GNN的解決方案。
這種方法被稱為Shift-Robust GNN(SR-GNN),從名字上不難看出,這個方法的目的就是要讓問題域發生變化和遷移時,模型依然保持高穩健性,降低性能下降。
研究人員在半監督學習的常見GNN基準數據集上,用有偏見的訓練數據集進行的各種實驗中,驗證了SR-GNN的有效性,實驗表明,SR-GNN在準確性上優于其他GNN基準,將有偏見的訓練數據的負面影響減少了30-40%。
數據分布偏移對GNN性能的影響
為了證明數據分布的偏移如何影響GNN的性能,首先為已知的學術數據集生成一些有偏見的訓練集。然后,為了理解這種影響,將泛化(測試準確率)與分布偏移的衡量標準(CMD)進行對比。
例如,以著名的PubMed引文數據集為例,它可以被認為是一個圖,圖的節點就是醫學研究論文,圖的「邊」就是這些論文之間的引用。如果為PubMed生成有偏見的訓練數據,這個圖看起來像下面這樣。
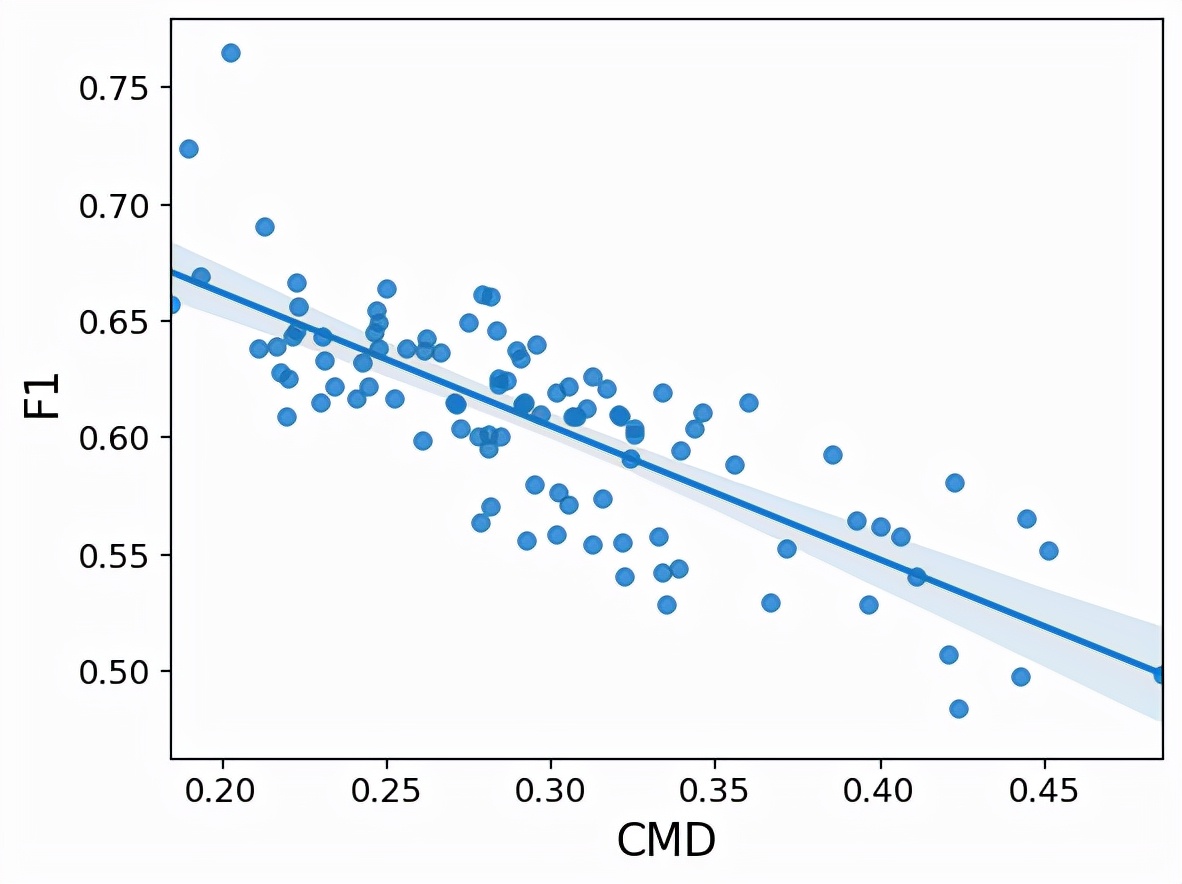
可以看到,數據集的分布偏移與分類準確率之間存在著強烈的負相關:隨著CMD的增加,性能(F1)顯著下降。也就是說,GNN可能難以泛化,因為訓練數據看起來不太像測試數據集。
為了解決這個問題,研究人員提出了一個對泛化高穩健性的正則化器,讓訓練數據和來自未標記數據的隨機均勻樣本之間的分布偏移實現最小化。
為了實現這一點,研究人員在模型訓練時對域偏移進行實時測量,并在此基礎上使用直接懲罰策略,迫使模型盡可能多地忽略訓練偏差,讓模型為訓練數據學習的特征編碼器對任何可能來自不同分布的未標記數據也能有效工作。
下圖所示為SR-GNN與傳統GNN模型的對比。二者輸入相同,層數相同。將GNN的第(k)層的最終嵌入Zk與來自未標記的數據點的嵌入進行比較,驗證該模型是否正確編碼。
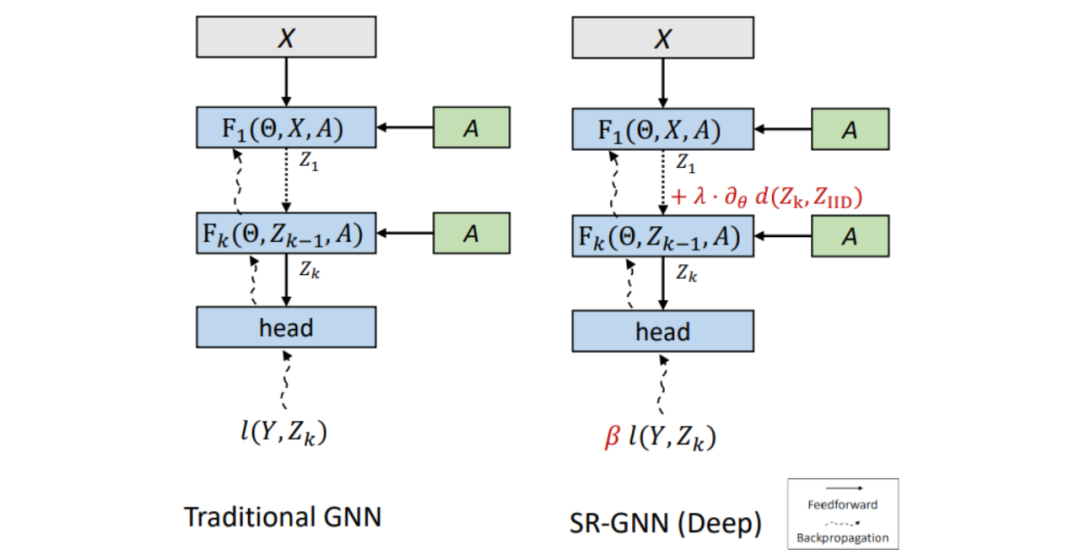
把這個正則化寫成模型損失公式中的一個附加項,該公式基于訓練數據的表征和真實數據的分布之間的距離制定。
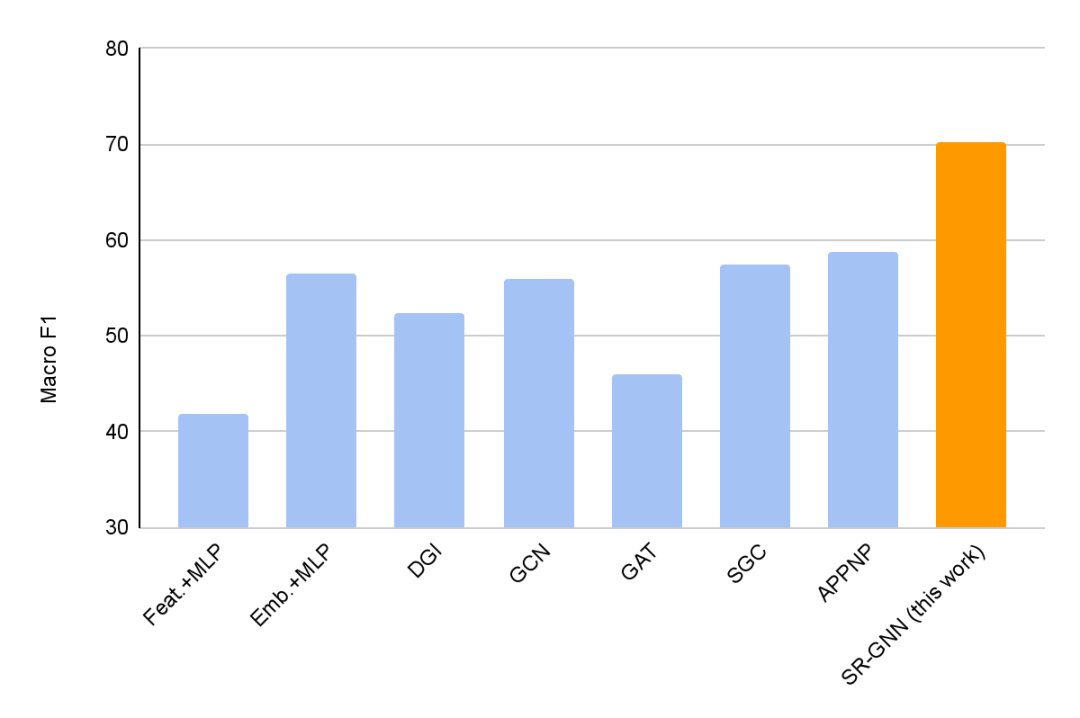
實驗證明,加入SR-GNN正則化后,在有偏見的訓練數據標簽的分類任務上,分類模型的性能實現了30-40%的提升。
另外,本文還研究了如何在有偏見的訓練數據存在的情況下,讓模型更加可靠。
盡管由于結構差異,相同的正則化機制不能直接應用在不同模型上,但可以通過根據訓練實例與近似的真實分布的距離重新加權來「糾正」訓練偏見。這能夠糾正有偏見的訓練數據的分布,無需通過模型來傳遞梯度。
這兩種正則化可以結合,形成一個廣義的損失正則化,結合了領域正則化和實例重權(細節,包括損失公式,可在論文中找到)。
結論
有偏見的訓練數據在現實世界的場景中很常見,這些偏見可能是由于各種原因造成的,包括對大量數據進行標注的困難、用于選擇標注節點的各種啟發式方法或不一致的技術、數據標記分布延時等等。
這個通用框架(SR-GNN)可以減少有偏見的訓練數據的影響,而且可以應用于各種類型的GNN,包括更深層的GNN,以及這些模型的線性化淺層GNN上。