













字節跳動開源大模型訓練框架veGiantModel ,性能最高提升6.9倍
近日,字節跳動應用機器學習團隊開源了一款名為 veGiantModel 的大模型訓練框架,該訓練框架主要應用于自然語言處理領域的大模型訓練,最高可將大模型訓練的性能提升6.9倍,大幅降低訓練系統的壓力。目前,字節跳動旗下的企業級技術服務平臺火山引擎已在其機器學習平臺上原生支持了 veGiantModel,該平臺正在公測中 。
自然語言處理是人工智能研究的一個重要領域,旨在幫助計算機理解、解釋和運用人類語言。近些年,自然語言處理在應用方面取得了較為顯著的突破,主要是歸功于 Bert、GPT、GPT-3 等預訓練語言模型的普及。可以說,預訓練語言模型已經成為人工智能領域的基礎設施。由于大模型的算法表現更加出眾,預訓練語言模型在近幾年呈現出迅速向大模型發展的趨勢。然而,模型體積的快速增長也對現有的訓練系統帶來了不小的挑戰,主要體現為顯存壓力、計算壓力和通信壓力。
針對現有訓練系統在大模型訓練場景下的上述挑戰, 字節跳動應用機器學習團隊提出了大模型訓練框架 veGiantModel。
veGiantModel的中文名稱叫做火山引擎大模型訓練框架,是基于開源深度學習框架 PyTorch 、并在 Megatron 和 DeepSpeed 兩大開源主流訓練框架的基礎之上構建的高性能大模型訓練框架。
veGiantModel 可同時支持數據并行、算子切分、流水線并行 3 種分布式并行策略,并支持自動化和定制化的并行策略;基于字節自研的高性能異步通訊庫 ByteCCL,veGiantModel 的訓練任務吞吐相比其他主流開源框架有 1.2 倍到 3.5倍的提升,并且提供了更友好、靈活的流水線支持,降低了模型開發迭代所需要的人力;另外,veGiantModel 可在 GPU 上高效地支持數十億至上千億參數量的大模型,對網絡帶寬要求也更低,在私有化部署時無 RDMA 強依賴。
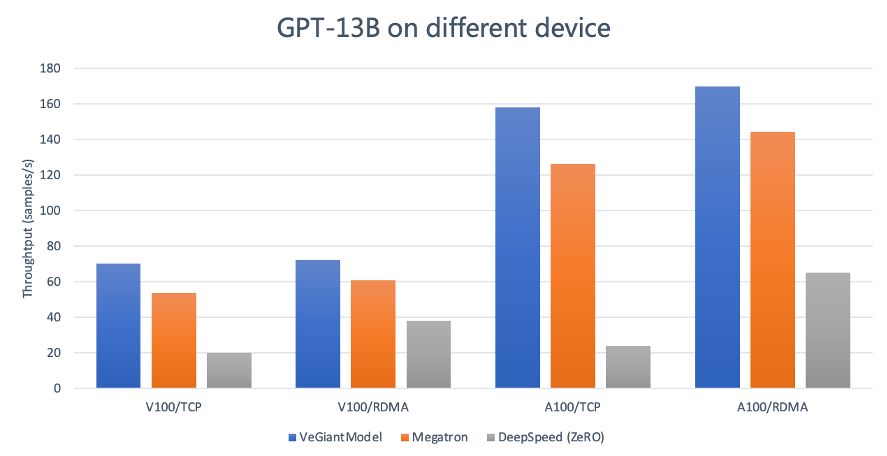
與 Megtraon 和 DeepSpeed 的對比測試顯示,veGiantModel 的性能表現最好、受網絡帶寬影響最小,在Tesla V100上較上述兩者有1.2 倍到3.5倍的提升,在 Ampere A100上最高可提升6.9倍。
veGiantModel開源 地址:
????https://github.com/volcengine/veGiantModel????
火山引擎機器學習平臺 公測地址:
??https://www.volcengine.com/product/ml-platform??



























