













性能最高提升 6.9 倍,字節跳動開源大模型訓練框架 veGiantModel
背景
近些年,NLP 應用方面有所突破,Bert、GPT、GPT-3 等超大模型橫掃各種 NLP 測試后,人們發現參數量越大的模型,在算法方面表現越好,于是紛紛開始迅速向大模型方向發展,模型體積爆炸式增長。而大模型訓練給現有的訓練系統帶來的主要挑戰為顯存壓力,計算壓力和通信壓力。
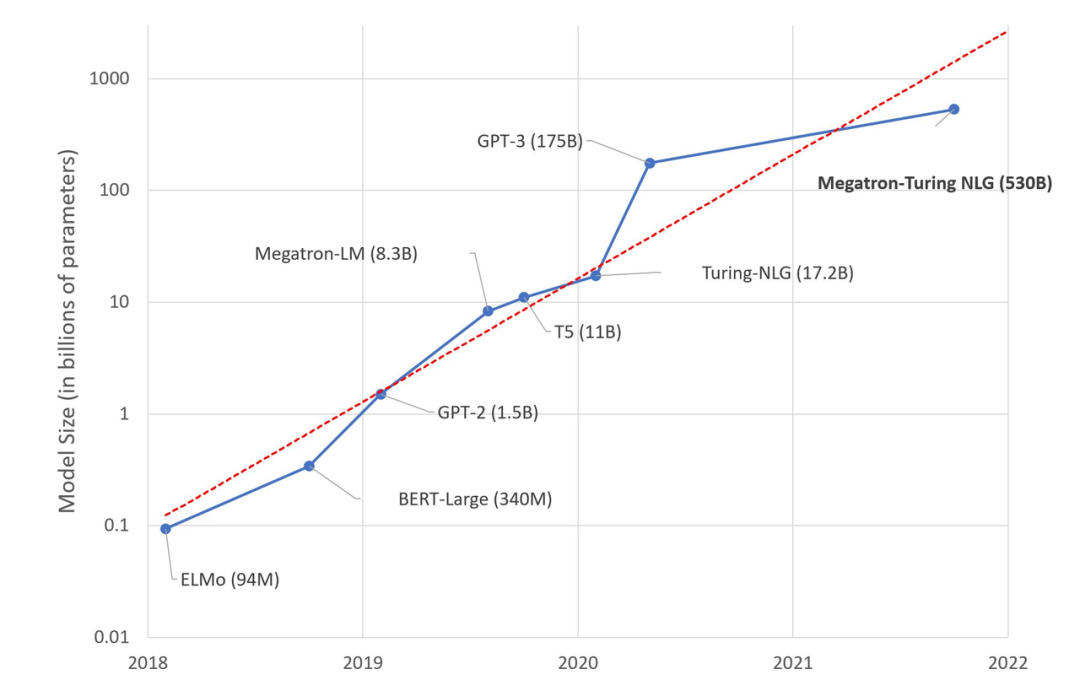
The size of language model is growing at an exponential rate (來源:https://huggingface.co/blog/large-language-models)
火山引擎大模型訓練框架 veGiantModel
針對這個需求,字節跳動 AML 團隊內部開發了火山引擎大模型訓練框架 veGiantModel。基于 PyTorch 框架,veGiantModel 是以 Megatron 和 DeepSpeed 為基礎的高性能大模型訓練框架。其特點包括:
- 同時支持數據并行、算子切分、流水線并行 3 種分布式并行策略,同時支持自動化和定制化的并行策略;
- 基于 ByteCCL 高性能異步通訊庫,訓練任務吞吐相比其他開源框架有 1.2x-3.5x 的提升;
- 提供了更友好、靈活的流水線支持,降低了模型開發迭代所需要的人力;
- 可在 GPU上高效地支持數十億至上千億參數量的大模型;
- 對帶寬要求低,在私有化部署無 RDMA 強依賴。
其中,ByteCCL 為字節跳動自研的 BytePS 的升級版,針對 A100/V100 等各種機型拓撲做了分層規約優化,并支持了 allgather、alltoall 等更全面的通訊原語。
veGiantModel 性能表現
硬件配置
為了展示 VeGiantModel 的性能,veGiantModel 團隊使用了自建機房的物理機,分別在 A100 和 V100 機型上做了測試,實驗配置分別如下:
- V100 測試:每個機器 8 張 Tesla V100 32G 型號 GPU,網絡帶寬 100G
- A100 測試:每個機器 8 張 Ampere A100 40G 型號 GPU,網絡帶寬 800G
模型和對照組選擇
veGiantModel 選擇了 GPT-13B 模型進行評估,seq length 是 256, global batch size 是 1536。GPT 為目前市面上最為流行的 transformer based 語言模型。性能對照組選擇了開源社區最流行的 Megatron 和 DeepSpeed。
測試結果
- V100/TCP :100Gb/s TCP 網絡帶寬,4 機,每機 8 張 Tesla V100 32G GPU
- V100/RDMA:100Gb/s RDMA 網絡帶寬,4 機,每機 8 張 Tesla V100 32G GPU
- A100/TCP:800Gb/s TCP 網絡帶寬,4 機,每機 8 張 Tesla A100 40G GPU
- A100/RDMA:800Gb/s RDMA 網絡帶寬,4 機,每機 8 張 Tesla A100 40G GPU
- 模型:GPT-13B
- Megatron:v2.4,tensor-model-parallel-size 設置為 4, pipeline-model-parallel-size 設置為 4
- DeepSpeed:v0.4.2,使用 DeepSpeedExamples 開源社區中默認的 zero3 的配置
- 運行環境
- 統計值:Throughtput (samples/s)
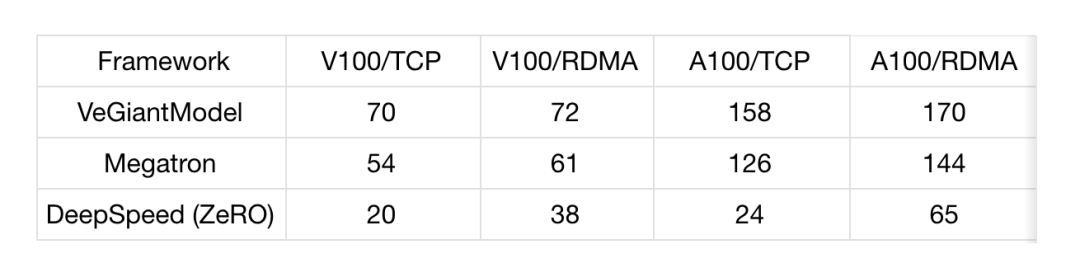
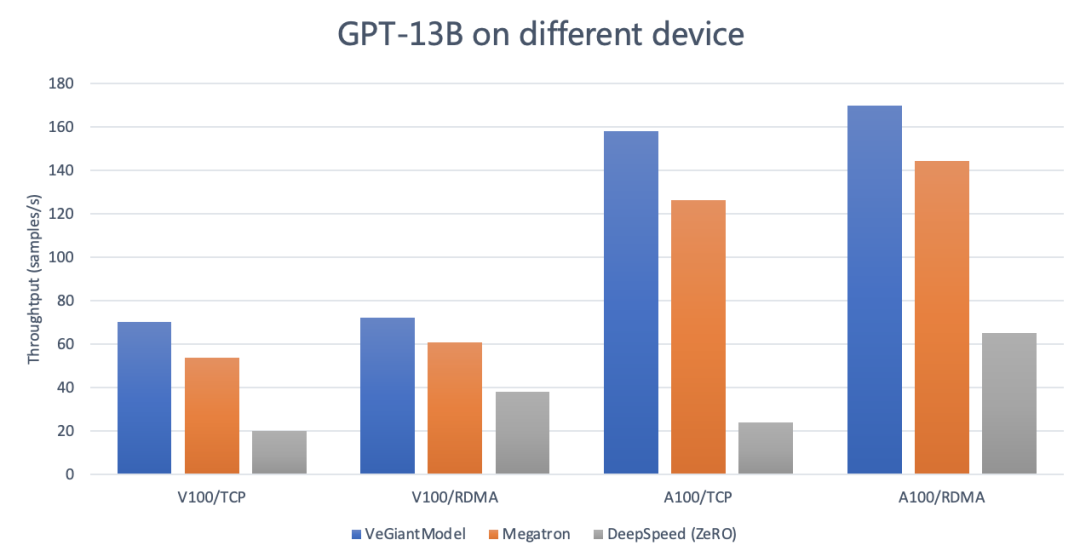
從上述數據可以看出:
- veGiantModel 性能更優:無論是在高帶寬還是低帶寬的場下,veGiantModel 在 V100 和 A100 上均勝出 Megatron 和 DeepSpeed,最高可達 6.9 倍提升。
- veGiantModel 對網絡帶寬要求低:veGiantModel 在帶寬變化對吞吐的影響相對最小 (<10%),而 DeepSpeed(ZeRO) 是對帶寬要求最高的,最高可達將近 5 倍的差距。
原因解析
veGiantModel 為什么比 Megatron 和 DeepSpeed 更快?原因如下:
- ByteCCL (BytePS) 高性能異步通訊庫。
- 支持定制化的并行策略,可以將性能優化推到極致。
- 在支持數據并行、算子切分、流水線并行 3 種分布式并行策略時,veGiantModel 會綜合考慮到跨機的帶寬,自動調整 toplogy 的 placement。
傳送門
veGiantModel 現已在 GitHub 上開源,地址如下:
https://github.com/volcengine/veGiantModel
GitHub 上詳細介紹了如何使用 veGiantModel 以及如何使用 veGiantModel 快速跑起一個 GPT 的預訓練。火山引擎機器學習平臺原生支持了 veGiantModel,目前平臺正在公測中,歡迎大家試用:https://www.volcengine.com/product/ml-platform



























