字節跳動開源 CowClip :推薦模型單卡訓練最高加速72倍
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
不夠快!還不夠快?
在 NLP 和 CV 任務上,為了加速神經網絡的訓練,借助 32K 的批量大小(batch size)和 8 塊 GPU,只需 14 分鐘就完成 ImageNet 的訓練,76 分鐘完成 Bert 的訓練。研究人員對訓練速度的渴望從來沒有停止過。
那,只用 1 塊 GPU 夠不夠?在推薦系統上,不僅可以,還能將批量大小繼續提升!
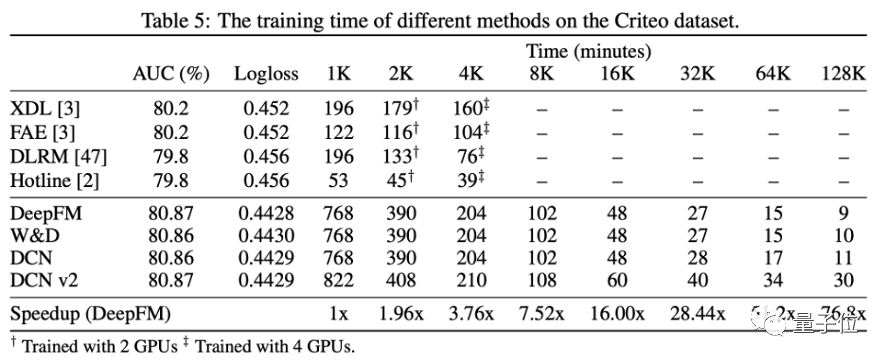
最近,字節跳動AML(應用機器學習團隊)和新加坡國立大學的研究人員提出了一個新的優化方法 CowClip,在公開點擊率預測數據集 Criteo 上最高支持 128K 批量大小,在單張 GPU 上訓練 DeepFM,可以將 12 小時的訓練時間壓縮到 10 分鐘,性能不降反升!

論文地址:https://arxiv.org/abs/2204.06240開源地址:https://github.com/bytedance/LargeBatchCTR
為了支持如此大批量大小的訓練,保持模型的訓練精度,文中提出了一套全新的優化訓練方法:通過參數轉換公式確定大批量大小下的參數,對 embedding 層進行自適應梯度裁剪。
用了 CowClip 優化方法的不同推薦模型(文中測試了 DeepFM 等四個模型),在兩個公開數據集上進行了理論和實驗驗證,證實了該方法的合理性和有效性。
作者表示,使用該優化方法,任何人都可以很容易的分分鐘訓練一個中小規模的推薦模型。
CowClip 加速的理論基礎
用戶交互會成為推薦系統新的訓練數據,模型在一次次的重新訓練中都學到最新的知識。目前的推薦系統面對著數以億計的用戶和數以千億計的訓練數據,一次完整的訓練要花費大量的時間和計算成本。
為了加速推薦系統的訓練,目前推薦系統會利用 GPU 進行加速訓練。然而,隨著 GPU 計算能力和顯存的不斷增加,過去推薦系統的訓練過程沒有完全利用好目前 GPU 的性能。舉例而言,在 Criteo 數據集上,當批量大小(batch size)從 1K 提升到 8K 后,用一塊 V100 進行訓練每次迭代所需的時間只有少量增加。這說明在目前的高性能 GPU 上,以往使用的小批量大小不足以充分利用 GPU 的并行能力。
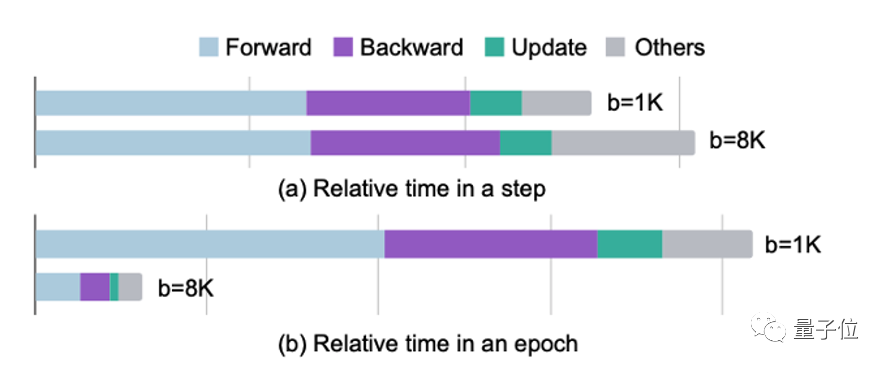
使用更大的批量大小可以更充分的挖掘 GPU 的性能,讓 GPU 真正物有所值。只要大批量大小下訓練的模型精度沒有損失,我們就可以不斷提高模型的批量大小,直到塞滿 GPU 的顯存。
然而防止模型精度損失并不是一件易事。一方面,更大的批量大小可能會使網絡訓練不穩定,并減弱網絡的泛化能力;另一方面,如果沒有規則指導在更大的批量大小上進行超參選擇,那調參會浪費大量的資源。
文中提出的 CowClip 便希望解決上述問題,通過在嵌入層(Embedding layer)逐列進行的動態梯度裁剪,和一組簡單有效的設置不同批量大小下超參數值的方法,讓擴大 128 倍的批量大小成為可能。
CowClip 方法
為了讓大批量大小下網絡的訓練更加穩定,研究者提出了自適應逐列梯度裁剪策略(Adaptive Column-wise Gradient Norm Clipping, CowClip)以穩定網絡的優化過程。梯度裁剪是一種優化更新過程的方法,它將范數值大于一定閾值的梯度裁剪到范數內。給定一個固定的閾值 clip_t,梯度裁剪過程如下:
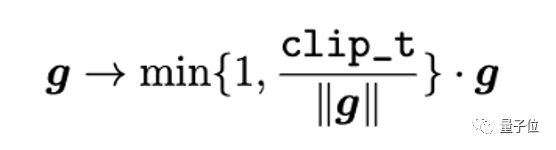
然而直接運用該方法到嵌入層的梯度上效果并不佳。該原因不僅在于難以確定一個有效的閾值,更在于訓練過程中,每個特征取值(ID 特征)對應的編碼向量(對應嵌入層中嵌入矩陣的一列)在訓練過程中的梯度值大小各不相同(如圖 4 所示),在全局應用梯度裁剪忽視了不同梯度值之間的差異。
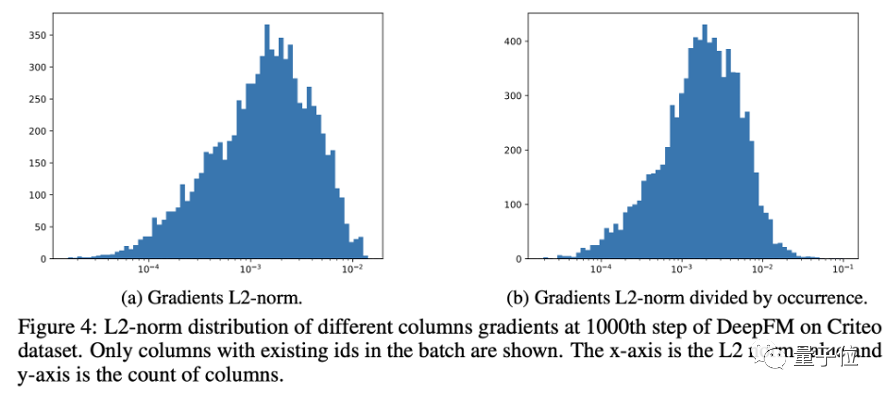
因此,研究者提出對每個特征取值對應的編碼向量單獨應用裁剪閾值,并自適應地設置該閾值。考慮到如果梯度大小超過參數大小本身時訓練過程會很不穩定,研究者提出用特征取值對應的編碼向量自身的范數值確定閾值。為了防止裁剪閾值過小,參數 ζ 保證了裁剪值不會低于一定的值。
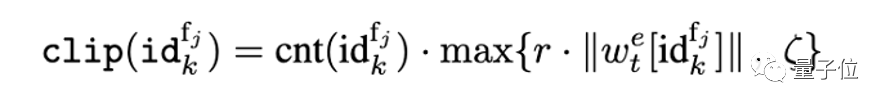
上式中,還需要考慮到由于特征 ID 的總頻次不同,在每個批次中出現的次數也不同。為了平衡出現的不同頻次,最后獲得的裁剪值還需乘以批次中對應頻次出現的次數。
基于以上分析,研究者提出的 CowClip 算法如下:

大批量大小下的參數轉換
在 CV 和 NLP 任務中,已經有一套擴大批量大小時調整學習率和 L2 正則項參數的方法。常用的方法包括線性調整(Linear Scaling),即在擴大 s 倍批量大小時,擴大 s 倍的學習率;以及平方根調整(Sqrt Scaling),即在擴大 s 倍批量大小時,學習率和正則項參數均以根號下 s 的大小擴大。
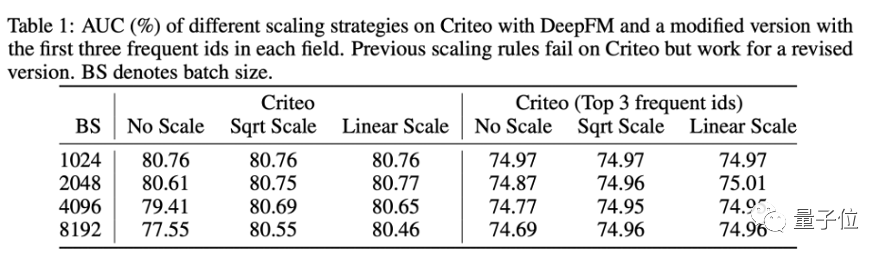
研究者首先探索了應用這些調整方法是否能有效的在大批量大小下保持性能。表一左側的實驗表明,當批量大小擴大時,這些方法的性能都出現了一定程度的下降。
文中指出,以往方法的失敗的原因在于,輸入的特征 ID 具有不同的頻率,而這是 CV 和 NLP 模型輸入不具有的特點。舉例而言,熱榜上的視頻播放量高,出現在數據集中的次數也就多,則視頻 ID 特征中該視頻 ID 的出現頻次就遠高于一些冷門視頻。
為了驗證上述想法,研究者改造了一個只包含高頻特征的數據集。果不其然,以往的參數調整方法此時可以取得好的結果(表一右側)。該實驗說明了頻次分布不一致確實阻礙了之前的參數調整方法,
論文中對該現象還進行了進一步的理論分析。簡單而言,如果重新考慮線性調整方法,其背后思想在于當批量大小增大后,更新迭代的步數減小,所以要擴大學習率。但對于出現次數非常少的特征,擴大批量大小時不會減小其更新迭代的次數。
由于點擊率預測數據集中絕大部分數據是此類低頻的特征 ID,結合 CowClip 方法,對模型的嵌入層可以不做學習率調整,并同時線性增大 L2 參數。
通過最后的實驗結果可以看到,利用 CowClip 訓練的模型比其它方法不僅精度更高,訓練速度也大幅度提升。