訓練CV模型新思路來了:用NLP大火的Prompt替代微調,性能全面提升
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
Prompt tuning,作為NLP領域中的一個“新寵”,甚至曾被學者譽為NLP預訓練新范式。
那么,它能否借鑒到CV領域并產生同樣的成績呢?
現在,來自康奈爾大學和Meta AI等機構,通過Prompt來調整基于Transformer的視覺模型,結果發現:
完全可以!
比起全面微調,Prompt性能提升顯著。無論模型的規模和訓練數據怎么變,24種情況中有20種都完全勝出。

與此同時,它還能大幅降低每項任務所需的存儲成本。
只使用不到1%的模型參數
大家一貫使用的全面微調(full fine-tuning),需要為每個下游任務存儲和部署單獨的主干參數副本,成本太高,尤其是現在基于Transformer的模型越來越大,已經超過CNN架構。
所謂Prompt,最初指的是在輸入文本中預編語言指令,以便預培訓的語言模型后續可以直接理解各種下游任務。
它曾讓GPT-3即使在少樣本或零樣本的情況下表現出很強的泛化能力。
最近一些成果則表明,Prompt與完全微調的性能相當,參數存儲量還減少了1000倍。
NLP中的高超性能讓不少人開始在CV領域中探索Prompt的魔力,不過都只局限于跨模態任務中文本編碼器的輸入。
在本文中,作者將他們所提出的Visual Prompt Tuning方法,簡稱為VPT。這是首次有人將Prompt應用到視覺模型主干(backbone),并做出成果。
具體來說,比起全面微調,VPT受最新大型NLP模型調整方法的啟發,只在輸入空間中引入少量可特定某任務訓練的參數(不到模型參數的1%),同時在訓練下游任務期間凍結(freeze)預訓練模型的主干。
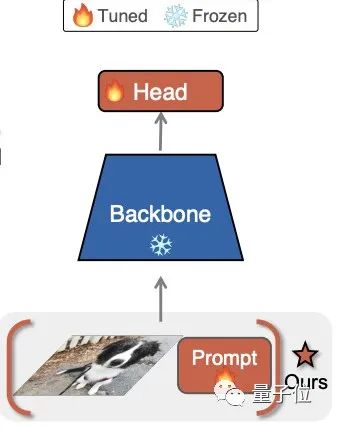
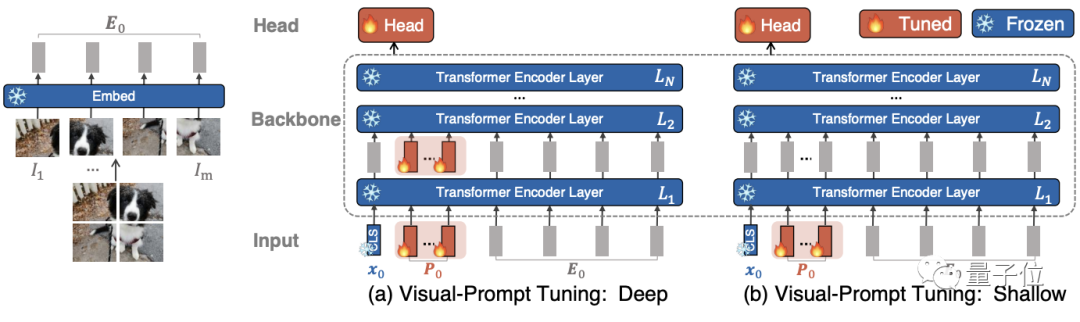
在實操中,這些附加參數只用預先加入到每個Transformer層的輸入序列中,并在微調期間與線性head一起學習。
他們一共探索出兩種變體:
VPT-Deep變體為Transformer編碼器每層的輸入預先設置一組可學習的參數;
VPT-Shallow變體則僅將提示參數插入第一層的輸入。
兩者在下游任務的訓練過程中,只有特定于任務的提示和線性頭的參數會更新,而整個Transformer編碼器被凍結。
接下來,是騾子是馬?拉出來溜溜~
20/24的優勝率
實驗涉及兩種在ImageNet-21k上預訓練好的主干,一個來自Vision Transformer,一個來自Swin Transformer。
進行對比的微調方法有三大種,7小種,包括:
(1)完全微調:更新所有主干和分類頭(classification head)參數
(2)以分類頭為重點的微調,包括Linear、Partial-k和Mlp-k三種;
(3)以及在微調過程中更新一個主干子集參數或向主干添加新的可訓練參數的方法,分為Sidetune、Bias和Adapter三種。

實驗的數據集有兩組,一共涉及24個跨不同領域的下游識別任務,包括:
(1)由5個基準細粒度視覺分類任務組成的FGVC;
(2)由19個不同視覺分類集合組成的VTAB-1k,細分為使用標準相機拍攝的自然圖像任務(Natural)、用專用設備(如衛星圖像)捕獲的圖像任務(Specialized)以及需要幾何理解的任務(Structured),比如物體計數。
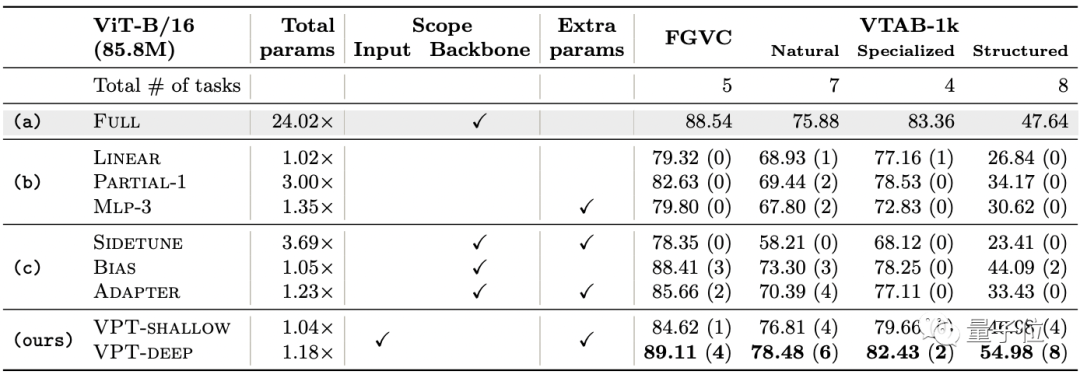
測得每項任務上的平均準確度后,得出的主要結果如下:
VPT-Deep在24個任務中有20個的表現都優于全面微調,同時使用的總模型參數顯著減少(1.18× vs. 24.02×);
要知道,在NLP領域中Prompt再厲害,性能也不會超過全面微調。這說明Prompt很適用于視覺Transformer模型。
和其他微調方法相比(b、c組),VPT-Deep的性能則全部勝出。
此外,選擇不同主干參數規模和模型規模的ViT(ViT-B、ViT-L和ViT-H)進行測試還發現,VPT方法不會受影響,依然基本保持性能領先。
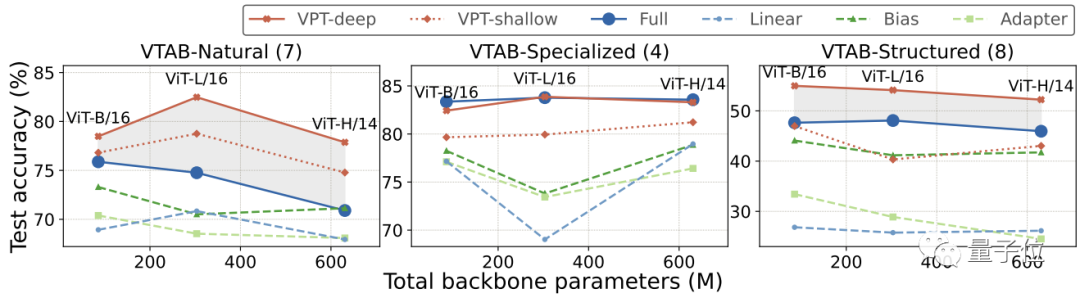
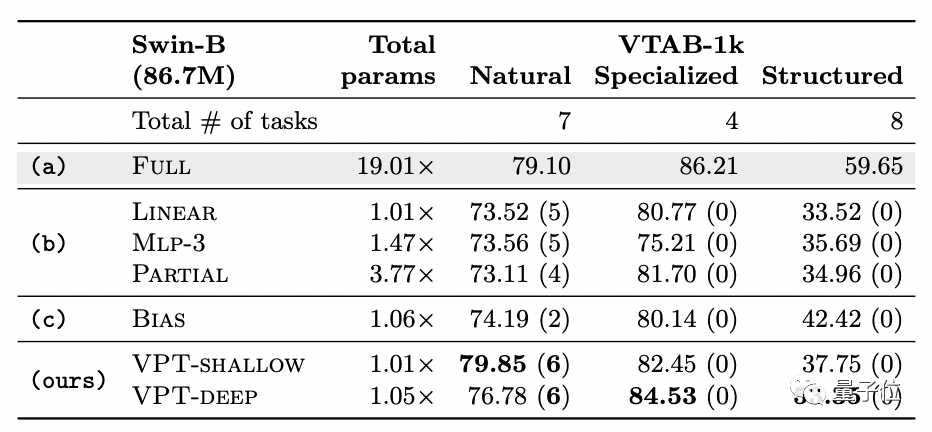
而在Swin Transformer中,全面微調法的平均準確度雖然更高,但也付出了巨大的參數代價。
其他微調方法則全部不敵VPT。
作者介紹
一作賈夢霖,康奈爾大學信息科學(Information Science)博士生,主要研究方向為視覺和文本信息的細粒度識別,截至目前共發表過4篇頂會。

共同一作為唐路明,也是康奈爾大學的一位計算機博士在讀學生,本科畢業于清華大學數學與物理專業。
他的主要研究方向為機器學習和計算機視覺的交叉領域。

論文地址:
??https://arxiv.org/abs/2203.12119??