谷歌下一代AI架構、Jeff Dean宣傳大半年的Pathways終于有論文了
在談及當前的 AI 系統所面臨的問題時,低效是經常被提及的一個。
谷歌人工智能主管 Jeff Dean 曾在一篇博文中寫道,「今天的人工智能系統總是從頭開始學習新問題 —— 數學模型的參數從隨機數開始。就像每次學習一項新技能(例如跳繩),你總會忘記之前所學的一切,包括如何平衡、如何跳躍、如何協調手的運動等,然后從無到有重新學習。這或多或少是我們今天訓練大多數機器學習模型的方式:我們不是擴展現有模型來學習新任務,而是從無到有訓練新模型來做一件事(或者我們有時將通用模型專門用于特定任務)。結果是我們最終為數千個單獨的任務開發了數千個模型。以這種方式學習每項新任務不僅需要更長的時間,而且還需要更多的數據。」
為了改變這種局面,Jeff Dean 等人去年提出了一種名叫「Pathways」的通用 AI 架構。他介紹說,Pathways 旨在用一個架構同時處理多項任務,并且擁有快速學習新任務、更好地理解世界的能力。

該架構的特點可以概括為:
- 能夠訓練一個模型來做成千上萬件事情;
- 當前模型只注重一種感官,Pathways 可做到多種;
- 當前模型密集且效率低下,Pathways 會把模型變得稀疏而高效。
在發布想法大半年之后,Jeff Dean 終于公布了 Pathways 的論文,其中包含很多技術細節。

論文鏈接 https://arxiv.org/pdf/2203.12533.pdf
論文寫道,PATHWAYS 使用了異步算子的一個分片數據流圖(sharded dataflow graph),這些算子消耗并產生 futures,并在數千個加速器上高效地對異構并行計算進行 gang-schedule,同時在它們專用的 interconnect 上協調數據傳輸。PATHWAYS 使用了一種新的異步分布式數據流設計,它允許控制平面并行執行,盡管數據平面中存在依賴關系。這種設計允許 PATHWAYS 采用單控制器模型,從而更容易表達復雜的新并行模式。
實驗結果表明,當在 2048 個 TPU 上運行 SPMD(single program multiple data)計算時,PATHWAYS 的性能(加速器利用率接近 100%)可以媲美 SOTA 系統,同時吞吐量可媲美跨越 16 個 stage 或者被分割成兩個通過數據中心網絡連接的加速器島的 Transformer 模型的 SPMD 案例。
以下是論文細節:
研究背景
在過去的十年里,深度學習在圖像理解、自然語言處理等多個領域取得了顯著的進展,這是 ML 模型、加速器硬件以及將兩者聯系在一起的軟件系統協同進化的結果。這種協同進化帶來的隱患是:深度學習系統可能過度專注于當前的工作負載,無法預測未來的需求。
PATHWAYS 是一個為分布式 ML 構建的新系統,劍指未來 ML 工作負載將需要的特定能力。當前,這些工作負載缺乏 SOTA 系統的支持。
例如,當今 SOTA ML 工作負載大多使用單程序多數據(SPMD)模型,該模型受到了 MPI 的啟發,其中所有加速器都在同步運行相同的計算,加速器之間的通信由 AllReduce 等集體來描述。
但近年來,研究人員開始在 ML 計算中被 SPMD 掣肘。大型語言模型已經使用流水線并行而不是純粹的數據并行來擴展;混合專家(MoE)等模型已經開始探索計算稀疏性,其最自然的表達方式是使用細粒度控制流和跨加速器的異構計算;系統設計者們已經開始采用巧妙的技術來在 MPI 風格的系統上執行流水線(pipelined)、同構 MoE 模型,但是,MPI 編程模型對于用戶和底層系統來說都太受限制了。
另一方面,隨著一代又一代新加速器的出現,ML 中的異構環境變得越來越普遍。提供對(通過高帶寬 interconnect 連接的)同構加速器的大「島」的獨占訪問是昂貴的,并且通常會造成浪費,因為單個用戶程序必須努力保持所有加速器持續忙碌。這種限制進一步推動研究人員走向「多程序多數據」(MPMD)計算。MPMD 通過將整個計算的子部分映射到一組更容易獲得的小加速器島上來實現更大的靈活性。為了提高利用率,一些 ML 硬件資源管理研究人員以細粒度的方式在工作負載之間復用硬件,實現工作負載彈性,并提高容錯能力。
最后,研究人員開始標準化一套基礎模型(foundation model),這些模型是在大數據上大規模訓練的,可以適應多種下游任務。通過在許多任務之間復用資源,并在它們之間有效地共享狀態,這種模型的訓練和推理提供了提高集群利用率的機會。例如,幾個研究人員可能同時微調用于不同任務的一個基礎模型,使用相同的加速器來保持固定的基礎模型層。在共享的子模型上進行的訓練或推理可以受益于一些技術,這些技術允許來自不同任務的示例被組合在一個 vectorized batch 中,以獲得更高的加速器利用率。
本文提出的 PATHWAYS 在功能和性能上可以媲美 SOTA ML 系統,同時提供了支持未來 ML 工作負載所需的能力。它使用了一個 client-server 架構,該架構使得 PATHWAYS 的運行時能夠代表許多 client 在系統管理計算島上執行程序。
PATHWAYS 是第一個旨在透明、高效地執行跨多個 TPU pods 的程序的系統。通過采用新的數據流執行模型,它可以擴展到數千個加速器。PATHWAYS 的編程模型使得表達非 SPMD 計算變得很容易,并支持集中的資源管理和虛擬化,以提高加速器的利用率。
PATHWAYS 系統架構
PATHWAYS 構建在先前的系統的基礎上,包括用于表征和執行 TPU 計算的 XLA (TensorFlow, 2019)、用于表征和執行分布式 CPU 計算的 TensorFlow 圖和執行器 (Abadi et al., 2016),以及包括 JAX (Bradbury et al., 2016) 在內的 Python 編程框架 (Bradbury et al., 2018) 和 TensorFlow API。利用這些構建塊,PATHWAYS 在兼顧協調性的同時,僅用最少的代碼更改就能運行現有的 ML 模型。
資源管理器
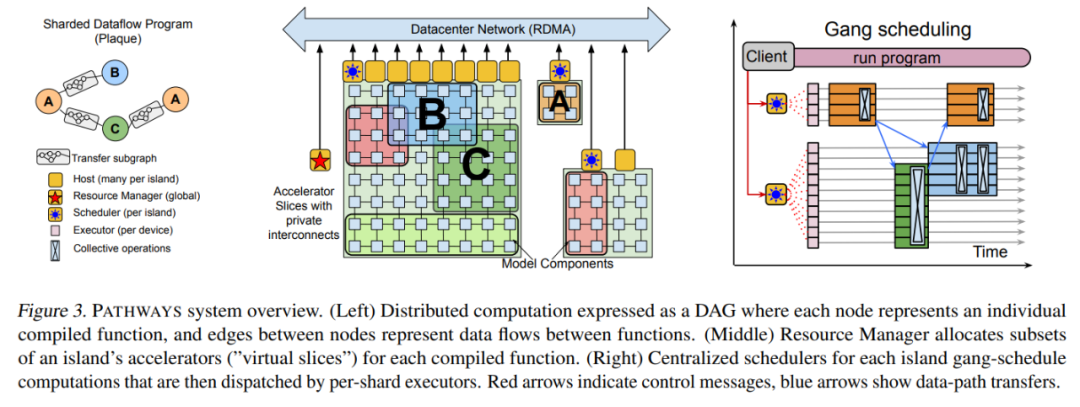
PATHWAYS 的后端由一組加速器組成,這些加速器組合成緊密耦合的 island,這些 island 又通過 DCN 相互連接,如上圖 3 所示。PATHWAYS 有一個「資源管理器」,負責集中管理所有 island 上的設備。client 可能會要求 island 的「虛擬 slice」具有適合其通信模式的特定 2D 或 3D 網格形狀。每個虛擬 slice 都包含「虛擬設備」,允許 client 表達計算在網格上的布局方式。資源管理器為滿足所需互連拓撲、內存容量等的虛擬設備動態分配物理設備。
最初的資源管理器使用一個簡單的啟發式方法來實現,嘗試通過在所有可用設備上傳播計算來靜態平衡負載,并在虛擬設備和物理設備之間保持一對一的映射。如果未來的工作負載需要,則可以采用更加復雜的分配算法,例如考慮所有 client 計算的資源需求和系統的當前狀態,以近似計算物理設備的最佳分配。
PATHWAYS 允許動態添加和移除后端計算資源,由資源管理器跟蹤可用設備。由單控制器設計啟用的虛擬設備和物理設備之間的間接層將允許未來支持透明的掛起 / 恢復和遷移等功能,其中 client 的虛擬設備可以臨時回收資源或重新分配而無需用戶程序的協助。
client
當用戶想要運行一個被跟蹤的程序時,可以調用 PATHWAYS client 庫,它首先將虛擬設備分配給之前沒有運行過的任何計算,并用資源管理器注冊計算,觸發 server 在后臺編譯計算。
然后,client 為程序構建與設備位置無關的 PATHWAYS 中間表征 (IR),表示為自定義 MLIR (Lattner et al., 2021) dialect。IR 通過一系列標準編譯器 pass 逐漸降低級別,最終輸出包含物理設備位置的低級表征。這種低級程序考慮了物理設備之間的網絡連接,并包含將輸出從源計算分片傳輸到其目標分片(shard)位置的操作,包括需要數據交換時的分散和收集操作。在虛擬設備位置不變的通常情況下重復運行低級程序是有效的,如果資源管理器改變了虛擬設備和物理設備之間的映射關系,可以 re-low 程序。
較舊的單控制器系統中的 client 可能很快成為性能瓶頸,因為它負責協調數千個單獨的計算,還要協調分布在數千個加速器中的計算分片相應的數據緩沖區。PATHWAYS client 使用分片緩沖區抽象來表征可能分布在多個設備上的邏輯緩沖區。這種抽象通過以邏輯緩沖區而不是單個分片的粒度分攤 bookkeeping 任務(包括參考計數(reference counting))的成本來幫助 client 擴展。
協調實現
PATHWAYS 依賴 PLAQUE 完成所有使用 DCN 的跨主機協調。PLAQUE 是一種現有的(閉源)生產分片數據流系統,谷歌將它用于許多面向客戶的服務,這些服務需要高扇出或高扇入通信,并且可擴展性和延遲都很重要。低級 PATHWAYS IR 直接被轉換為 PLAQUE 程序,并表征為數據流圖。PATHWAYS 對其協調 substrate 有嚴格的要求,而 PLAQUE 滿足所有要求。
首先,用于描述 PATHWAYS IR 的表征必須包含每個分片計算的單個節點,以確保能夠緊湊表征跨多個分片的計算,即帶有 N 個計算分片的 2 個計算 A 和 B 的鏈式執行,無論 N 是多少,每個計算分片在數據流表征中都有 4 個節點:Arg → Compute (A) → Compute (B) → Result。在 PLAQUE 運行時實現中,每個節點都會生成帶有目標分片標記的輸出數據元組,因此在執行數據并行執行時,N 個數據元組將在每對相鄰的 IR 節點之間流動。
協調運行時還必須支持沿分片邊緣的稀疏數據交換,其中消息可以在動態選擇的分片子集之間發送,使用標準的進度跟蹤機制(Akidau et al., 2013; Murray et al., 2013)來檢測何時已收到分片的所有消息。高效的稀疏通信能夠避免 DCN 成為加速器上依賴于數據的控制流瓶頸,這是 PATHWAYS 啟用的關鍵功能之一。
如下圖 4 所示,協調 substrate 用于發送傳輸調度消息和數據 handle 的關鍵路徑中的 DCN 消息,因此它必須以低延遲發送關鍵消息,并在需要高吞吐量時將消息批量發送到同一個 host。
使用可擴展的通用數據流引擎來處理 DCN 通信也很方便,因為這意味著 PATHWAYS 還可以將其用于后臺管理任務,例如分發配置信息、監控程序、清理程序、在出現故障時提示錯誤等。
谷歌認為,使用 Ray (Moritz et al., 2018) 等其他分布式框架而不是 PLAQUE 來重新實現完整的 PATHWAYS 設計以實現低級協調框架是可行的。在這種實現中,PATHWAYS 執行器和調度器將被長期運行的 Ray Actor 所取代,這些 Ray Actor 將在底層 Ray 集群調度之上實現 PATHWAYS 調度,并且執行器可以使用 PyTorch 進行 GPU 計算和集合。
Gang-scheduled 動態調度
如前所述,在一組共享加速器上支持 SPMD 計算的一個要求是支持高效的 gang-scheduling。
PATHWAYS 運行時包括每個 island 的集中式調度器,它對 island 上所有計算進行一致性排序。當 PATHWAYS 將一個程序加入隊列以執行時,PLAQUE 數據流程序負責以下操作:
- 在每個加速器上將本地編譯函數執行加入隊列,并將緩沖 future 作為輸入;
- 將網絡發送(network sends)加入到遠程加速器的隊列,以獲得函數執行輸出的緩沖 future;
- 與調度器通信,以確定在 island 上運行的所有程序中函數執行的一致順序。
調度器必須實施以毫秒為單位分配加速器的策略。不過,當前的實現只是按照 FIFO 順序將工作加入隊列,但更復雜的調度器可能會根據估計的執行時間重新排序計算。
并行異步調度
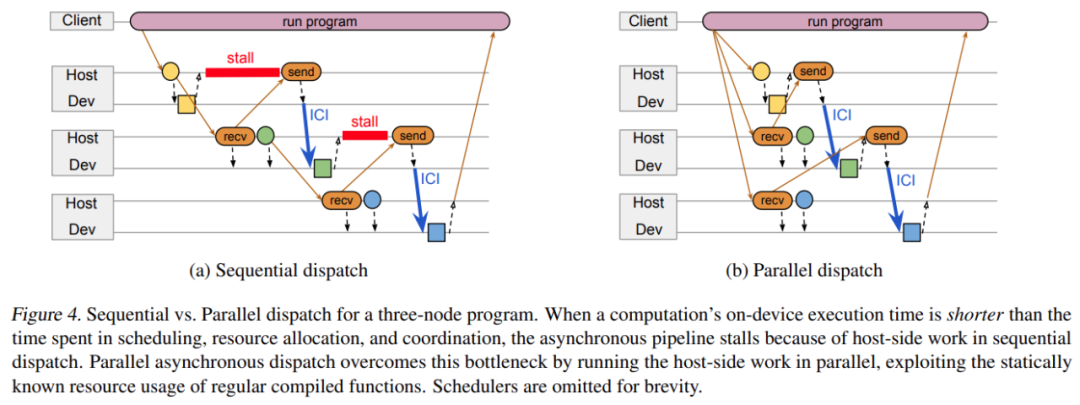
當在加速器上運行計算時,系統可以利用異步 API 將計算與協調重疊。如下圖 4a 中的三節點圖所示,正方形分別對應三個節點 A、B 和 C,它們在連接到主機 A、B 和 C 的加速器上運行。所有節點計算都是常規編譯函數。主機 A 將節點 A 加入隊列,接收 A 輸出的 future 并將它傳輸給主機 B。主機 B 分類節點 B 的輸入,將該輸入緩沖地址傳輸給節點 A,并執行大部分準備工作以啟動節點 B 的功能。當節點 A 完成時,它的輸出直接通過加速器互聯發送至節點 B 的輸入緩沖,然后主機 B 啟動節點 B。一個節點完成和另一個節點啟動之間的延遲時間要比數據傳輸時間更長。
當 predecessor 節點的計算時間超過主機之間調度、資源分類和協同所用時間時,上述設計運行良好。但如果計算時間太短,異步 pipeline 就會停止,主機端的工作成為執行整個計算序列過程中的關鍵瓶頸。考慮到編譯的函數都是常規的,后續節點的輸入形狀實際上可以在 predecessor 計算加入隊列之前進行計算。
因此,谷歌引入了一種全新的并行異步調度設計方案,具體如下圖 4 b 所示。該方案利用常規編譯函數的靜態已知資源來并行運行計算節點的主機端工作,而不是在 predecessor 已經加入隊列之后對節點工作進行序列化處理。考慮到常規函數下只能并行地調度工作,PATHWAYS 將并行調度作為一種優化手段,并在節點資源需求在 predecessor 計算完成時才知道的情況下回退到傳統模型。
當計算的子圖可以進行靜態調度時,該程序會向調度器發送描述整個子圖的單條消息,該調度器能夠對子圖中所有活動分片的執行進行背靠背排序。設計單條消息旨在最小化網絡流量,但不需要調度器將所有子圖的分片作為一個批次來加入隊列:計算仍可能與其他并發執行程序提交的計算交錯。
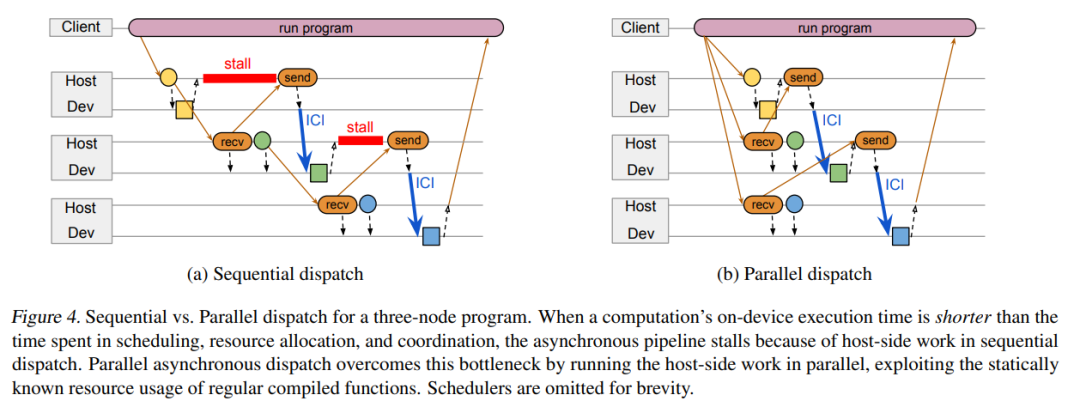
三節點程序的順序調度(a)與并行調度(b)比較。
實驗結果
谷歌展示了 PATHWAYS 在訓練真實機器學習模型(它們可以被表示為 SPMD 程序)中的性能。首先與使用編碼器 - 解碼器架構運行 Transformer 模型的 JAX 多控制器進行比較。
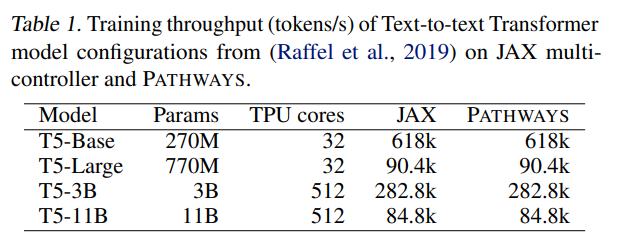
下表 1 展示了在不同數量的加速器上訓練時,不同大小的文本到文本 Transformer 模型的訓練吞吐量(tokens / 秒)。正如所預期的一樣,由于模型代碼相同,在 JAX 和 PATHWAYS 上訓練的模型在步數相同的情況下實現了相同的困惑度。
接著,谷歌比較了當僅用解碼器架構訓練 Transformer 語言模型時,PATHWAYS 在不同配置上的性能。如表 2 所示,PATHWAYS 的訓練吞吐量與每個 pipeline 階段的 TPU 核心數量成比例增加,這與其他系統保持一致。

上述結果與下圖 5 一致, 表明 PATHWAYS 的吞吐量與主機數量呈線性縮放關系。增加 pipeline 階段的數量會提高最小開銷,當階段數量從 4 增加到 16 時,吞吐量從 133.7k tokens / 秒減少到 131.4k tokens / 秒。谷歌將 pipelined 模型的性能與使用 SPMD 的等效模型進行了比較,并觀察到至少在這種情況下,pipeline 的性能與 SPMD 相當,這是因為 SPMD 計算內部聚合通信產生的開銷比 pipeline 泡沫(bubble)開銷更高。
?
 ?
?