首次利用半監督注入知識,達摩院推出新型預訓練對話模型,取得顯著提升
?隨著深度學習的迅猛發展,學術界每年都會有許多高質量標注數據集被公開,如文本分類、情感分析等等,同時工業界也會積累沉淀面向任務的各類標注數據,怎樣將儲存在標注數據中的特定任務知識注入到預訓練模型中,從而帶來該類任務的普遍效果提升,就成為一個重要的研究方向。
本文從將預訓練模型的兩大經典范式簡介開始,圍繞預訓練語言模型學到哪些知識、如何向預訓練模型注入知識展開,然后重點介紹預訓練對話模型及達摩院對話智能團隊在半監督預訓練對話模型方面的進展,最后對未來研究方向作出展望。
1. 預訓練語言模型的兩大范式
1.1. 有監督預訓練
神經網絡模型的預訓練一直是深度學習中備受關注的問題。最早的研究可追溯到 Hinton 教授在 2006 年提出的一種基于受限玻爾茲曼機優化的貪心算法 [2],該方法利用無標數據針對深度信度網絡(Deep Belief Nets, DBN)進行一層層地初始化,從而能夠保證較深的網絡在下游任務上也能快速收斂。隨著大數據的興起和算力的提升,人們逐漸發現直接在具有高度相關性的大型有標數據集上進行有監督預訓練,然后再某個特定下游任務進行遷移學習能夠帶來更強的表現,比較常見的工作是利用 VGG,ResNet 等超深模型在 ImageNet 上進行預訓練,將有關圖像分類的專家標注的大量經驗知識注入到模型的參數中,從而在目標追蹤、圖片分割等其他相關任務上進行更好地適應學習。
1.2. 自監督預訓練
近一兩年里,隨著預訓練語言模型的興起,利用自監督的方式在無標數據上針對鑒別式模型構造有監督損失函數進行超大規模的自監督預訓練成為了新的主流,例如在自然語言處理領域中,BERT 使用基于上下文的詞 token 預測可以訓練出很好的自然語言表征,在大量 NLP 任務上都得到了效果驗證 [3];而在計算機視覺領域中,近期以 ViT [4] 為基礎的一系列工作,也利用了類似 BERT 的 transformer 結構進行圖片 patch 重建的預訓練,從而習得良好的圖片表征,并在 imagenet-1K 等圖片分類數據集上取得顯著提升。
清華研究者們在綜述 [5] 中從遷移學習的角度來統一審視了目前已有的兩大預訓練范式,如下圖 1 所示,無論是有監督預訓練還是自監督預訓練,歸根結底都是直接從數據中學出更加合理的分布式表示,從而能夠更好地遷移適配到具體的下游任務。
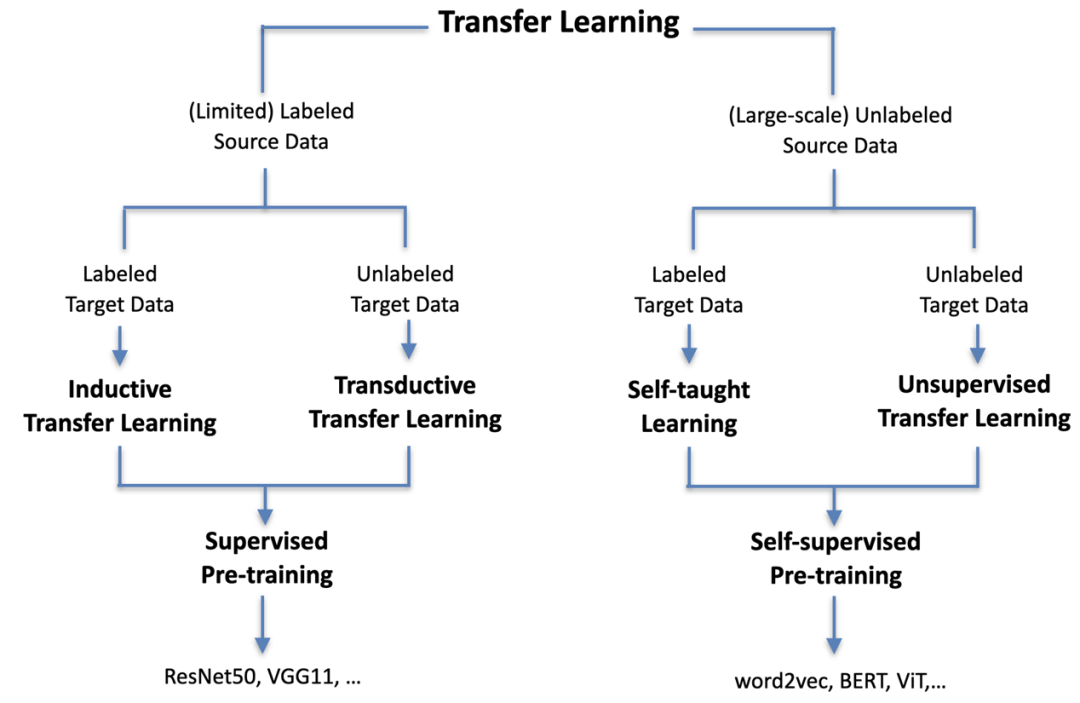
圖 1:神經網絡預訓練兩大范式(改自綜述 [5])
總結來看,兩種范式各有自己的優劣點:有監督預訓練因為存在有標數據進行指導,所學出的特征對某些相關下游任務更加適配,但是卻嚴重依賴人工標注;自監督預訓練可不再受到人工標注的局限,利用海量無標數據進行學習,但所設計的損失函數一般都需要簡單通用,例如 LM loss, MLM loss 和 contrastive loss 等,這就使得大模型學習到的更多是普適的語義表示。
2. 預訓練語言模型學會了什么?
2.1. 模型的知識探測
依目前發展來看,以 BERT 為代表的自監督預訓練已經成為了研究主流。論文 [6] 曾對 BERT 模型 “庖丁解牛”,通過知識探測的手段,深入地探究了每一層的注意力權重的關系(如圖 2 所示),發現不同層的不同注意力頭(attention head)都對不同的語言特征敏感,例如有的注意力頭對于定冠詞修飾的名詞敏感,有的注意力頭對于被動語態關注度更高,有的則在一定程度上實現了長距離指代消解。
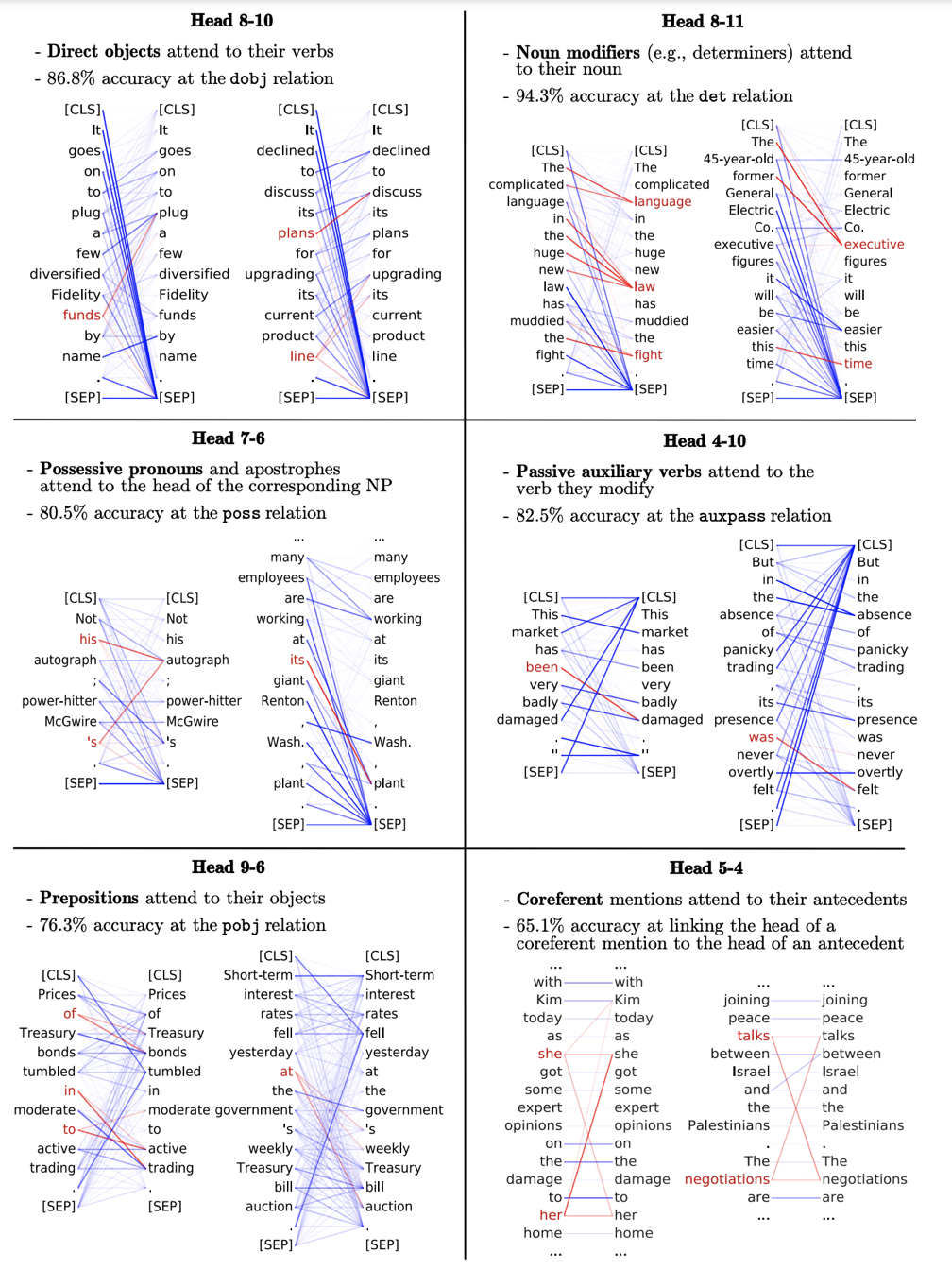
圖 2:解析 BERT 不同注意力頭的權重圖 (引自 [6])
預訓練的本質是將訓練數據中蘊含的信息以模型可理解的方式隱含地存儲到參數中 [5],不少研究工作已經表明 [7][8][9],預訓練模型如 BERT 能夠學習到較好的語言學知識(句法、語法),甚至一定程度上的世界知識和常識知識。但是預訓練模型在如何更好地學習利用人類經驗知識上依舊存在不少問題,需要更多的研究與探索,例如如何對其進行更好的建模,如何更有效地進行預訓練,如何評價知識融入的程度等等。
2.2. 人類經驗知識
這里,我們將人類經驗知識粗略分為三類:
- 第一類是事實型知識,例如人工構建的知識表格、知識圖譜和結構化文檔(包含篇章結構、圖文信息)。目前已經有一些預訓練的工作針對這類知識進行更好地利用,例如達摩院不久前開源的最大中文預訓練表格模型(詳見《達摩院開源中文社區首個表格預訓練模型,取得多個基準 SOTA》一文);清華的 KEPLER [12] 和北大的 K-BERT [11] 是通過將三元組融合到神經網絡輸入并引入新的損失函數或結構來實現圖譜知識的有效融入;微軟的 LayoutLM 系列模型 [13] 和 Adobe 的 UDoc [14] 則研究了如何針對結構化文檔進行預訓練。
- 第二類是數理邏輯知識,包括數理公式、公理定理、符號計算等,這一類知識不作為本文討論內容。
- 第三類是標注知識,即標注數據中蘊含的知識。這類知識十分普遍,屬于任務相關的,例如文本分類、情感分析等。人類在標注過程中需要根據該特定的任務進行歸納總結,在預先定義的高層語義分類空間中對無標數據進行推斷并賦值相應的標簽。因此,利用標注知識來增強預訓練模型理應會對相關下游任務帶來明顯效果提升。
3. 如何注入人類標注知識?
盡管現在各類預訓練模型包打天下,但是如何向模型中注入標注知識依舊是一個尚未充分探索的方向。早期工作中,谷歌的 T5 [16] 就已經嘗試了將有標和無標數據統一成語言生成任務進行學習,但是實驗卻表明簡單地混合有標無標數據訓練反而會帶來負面影響。
經過大量的實驗探索,我們發現如果還是基于原先的兩大預訓練范式,是難以很好地進行預訓練的。首先,單利用自監督預訓練或者有監督預訓練是無法同時利用好有標和無標的預訓練數據,因為僅僅自監督損失函數是無法學習出標注知識中的高層語義的,有監督損失函數亦不能學出無標語料中的通用底層語義;其次,在大規模預訓練中,由于所使用的預訓練數據往往存在著少量有標數據和海量無標數據之間的數量鴻溝,如果簡單混合兩種預訓練,會使得標注知識的信息要么淹沒在無標數據中,要么就會出現嚴重的過擬合,因此我們需要全新的預訓練范式來解決該問題。
這里,我們提出半監督預訓練。如圖 3 所示,半監督預訓練從遷移學習的角度來看,可以認為是一個前兩種范式的自然延伸,通過構造半監督學習的損失函數來充分綜合利用有限的標注知識和大量的無標數據。在半監督學習理論里 [17],模型既需要在無標數據上進行自我推斷,根據結果進一步約束優化,也需要利用有標數據進行一定程度的有監督,指導自監督預訓練的過程,同時避免模型參數陷入平凡解。
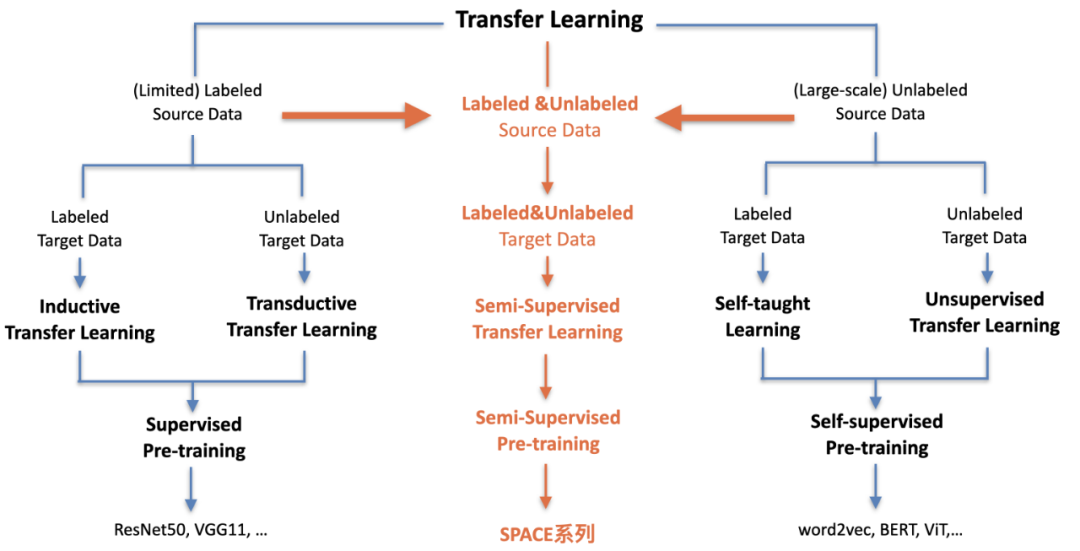
圖 3:半監督預訓練新范式
我們團隊專注在對話智能(Conversational AI)方向,所以我們率先將半監督預訓練的思路應用在了對話領域,提出了半監督預訓練對話模型,在 MultiWoz 等國際經典對話數據集上取得了顯著提升,論文已經被 AAAI2022 錄用 [1]。接下來我們先簡單介紹一下什么是預訓練對話模型,然后重點介紹半監督預訓練對話模型。
4. 預訓練對話模型
預訓練語言模型(Pre-trained Language Model, PLM)需要回答的什么樣的句子更像自然語言,而預訓練對話模型(Pre-trained Conversation Model, PCM)需要回答的是給定對話歷史什么樣的回復更合理。因此,預訓練對話模型相比預訓練語言模型任務更加特定化,需綜合考慮對話輪次、對話角色、對話策略、任務目標等預訓練語言模型不太關注的特征,圖 4 給出了一個對話特有屬性的總結。

圖 4:對話特有的屬性總結
目前預訓練對話模型的建模,基本按照對話理解和對話生成兩大任務類進行建模,利用類似于 BERT 或者 GPT-2 的 loss 在對話語料上進行預訓練。例如,針對話理解,常見模型有 PolyAI 的 ConvRT [20],Salesforce 的 TOD-BERT [21] 和亞馬遜的 ConvBERT [31],針對對話生成,常見模型有微軟的 DialoGPT [18],谷歌的 Meena [19] 和 Facebook 的 Blender [30]。但是,這些模型都沒有融入標注知識。
5. 半監督預訓練建模方案
我們的目標評測基準是劍橋 MultiWOZ2.0,亞馬遜 MultiWOZ2.1 等經典對話數據集,該任務需要通過構建對話模型來進行用戶意圖識別、對話策略選擇和回復生成。針對下游任務模型,我們直接沿用已有的端到端對話模型 UBAR [24],將其通用的 GPT-2 模型底座換成我們的 SPACE 模型底座,再進行相同設置下的評測。
5.1. 對話策略知識
對話策略是對話過程中的一個重要模塊,一般用對話動作標簽(dialog act, DA)來進行刻畫,即給定雙方的對話歷史,對話策略需要選擇出正確的對話動作用于指導對話生成(圖 5)。當前各種常見預訓練對話模型,如 Meena,DialoGPT 等往往都直接將對話動作的選擇過程隱含建模到模型參數里,存在著不可解釋和不可控等問題。由于策略是一種高層語義,難以僅僅利用自監督的方式就能很好地學習出來。因此,接下來我們將從對話策略建模出發,提出利用半監督的方式實現更好的預訓練,將標注數據中的對話策略知識融入到預訓練對話模型中來。
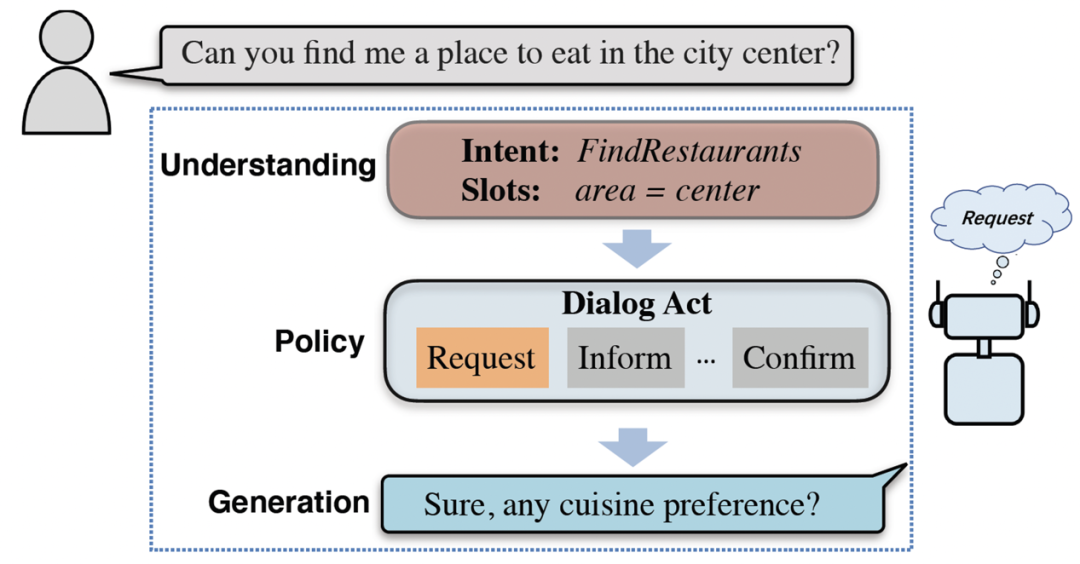
圖 5:一輪完整對話過程
經過總結分析,我們從 ISO 國際對話動作標準 [25] 中歸納出了 20 個對于任務型對話最高頻的對話動作集合(見圖 6),并整理合并了現有的多個對話數據集,經過人工對齊刪改后我們給出了目前最大的英文任務對話動作標注數據集 UniDA(一共 97 萬輪次),同時我們也從各種公開論壇,開源 benchmark 等渠道收集處理得到了高質量的英文無標對話語料 UnDial (一共 3.5 千萬輪次)。具體細節可參考論文 [1]。
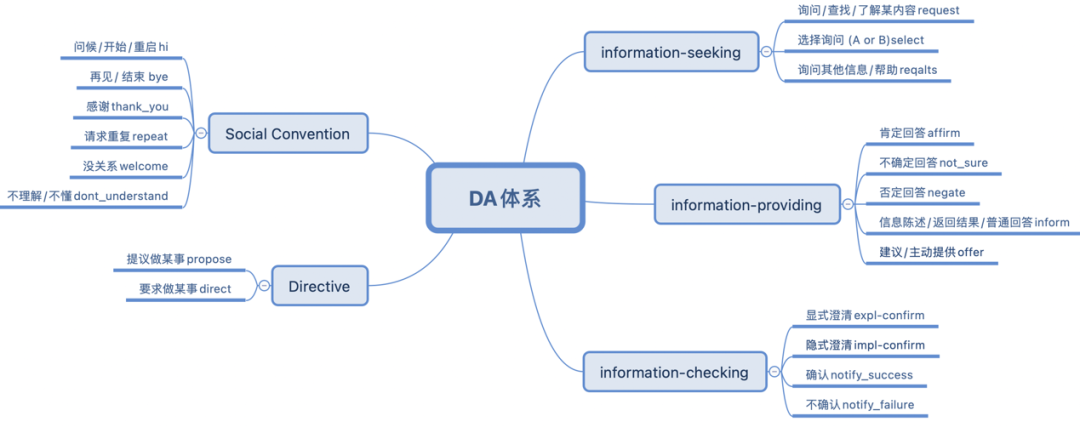
圖 6:英文對話 UniDA 體系
5.2. 策略知識注入
在本文中,我們提出利用半監督預訓練的方式來解決對話策略的建模難題,將對話動作預測任務改造成半監督學習任務,并設計出 SPACE 系列的第一款預訓練模型 SPACE 1.0 (亦即我們 AAAI 論文 [1] 中 GALAXY 模型)。
具體來看,SPACE1.0 采用了 encoder+decoder 架構,預訓練的目標既包含了傳統的建模對話理解和對話生成的自監督 loss,也包含了建模對話策略的半監督 loss,完整框架見圖 7。
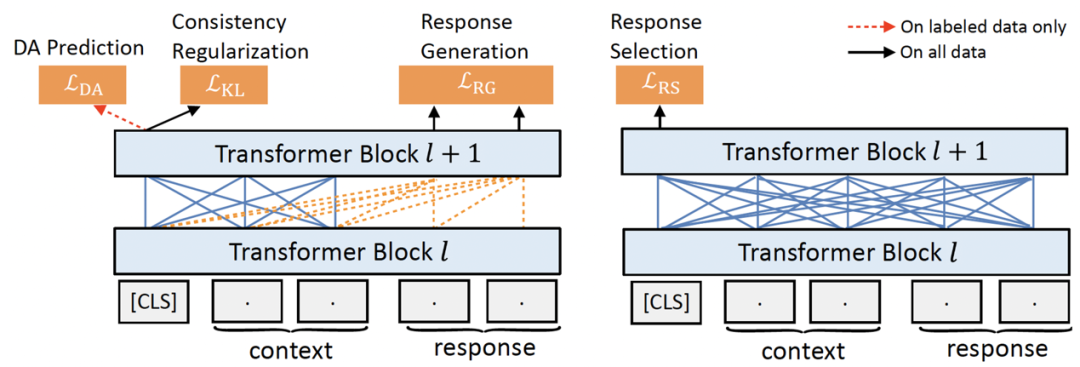
圖 7:半監督對話預訓練框架
首先,對于對話理解,我們采用了回復選擇(response selection)作為預訓練目標(如圖 7 右側所示),即給定對話上下文(context)和候選回復(response)在 [CLS] 處進行二分類判決是否是正確的回復。在諸多 PCM 工作中 [20][21] 中都已經證明了回復選擇的訓練對于對話理解至關重要,因此我們保留該目標。
對于對話生成,我們則使用了常見的回復生成(response generation)目標,即給定對話上下文生成正確回復語句(如圖 7 左側所示)。
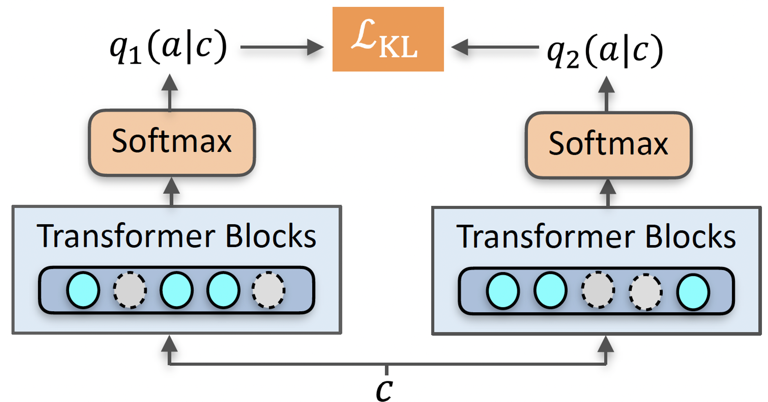
圖 8:基于 R-drop 的一致性正則損失
對于對話策略,我們采用了半監督學習中十分高效的一致性正則 (consistency regularization) 方法來建模對話動作。理論可以證明,在滿足低密度假設下(即分類邊界處于低密度分布),通過對同一個樣本進行擾動后分類結果仍然具備一定程度上的一致性(即分布接近或預測結果接近),那么最終基于一致性正則的半監督學習可以保證找到正確的分類面 [23]。針對對話策略的具體損失函數組成如下:
- 針對無標對話數據,我們采用了 R-drop [22] 的思路,如圖 7 所示,給定同樣的對話輸入 c,經過兩次帶有 dropout 的 forward 得到了兩次經過隨機擾動后在對話動作空間上預測的不同分布,然后通過雙向 KL 正則損失函數來約束兩個分布;
- 針對有標對話數據,我們則直接利用基礎的有監督交叉熵 loss 來優化對話動作預測。
最終對于模型的預訓練,我們將整個模型的理解、策略、生成目標加在一起進行優化。更多具體細節可參考論文 [1]。
6. 半監督預訓練效果顯著
我們在斯坦福的 In-Car [28],劍橋的 MultiWOZ2.0 [26] 和亞馬遜的 MultiWOZ2.1 [27] 這三個國際對話數據集上進行效果驗證。In-Car 數據集提出時間最早,是車載語音對話數據,一共有約 3k 個完整對話,難度較為簡單;MultiWOZ2.0 是目前最大最難使用最廣泛的任務型對話數據集,包含 1w 個完整對話,橫跨 7 個場景,如訂餐館、訂酒店等。MultiWOZ2.1 是在 MultiWOZ2.0 基礎上進行人工標注校正后數據集。
如圖 9 所示,經過半監督預訓練融入策略知識后,可以看到我們的 SPACE1.0 模型在這些對話榜單上均大幅超過了之前的 SOTA 模型,端到端混合分數在 In-Car,MultiWOZ2.0 和 MultiWOZ2.1 分別提升 2.5,5.3 和 5.5 個點:
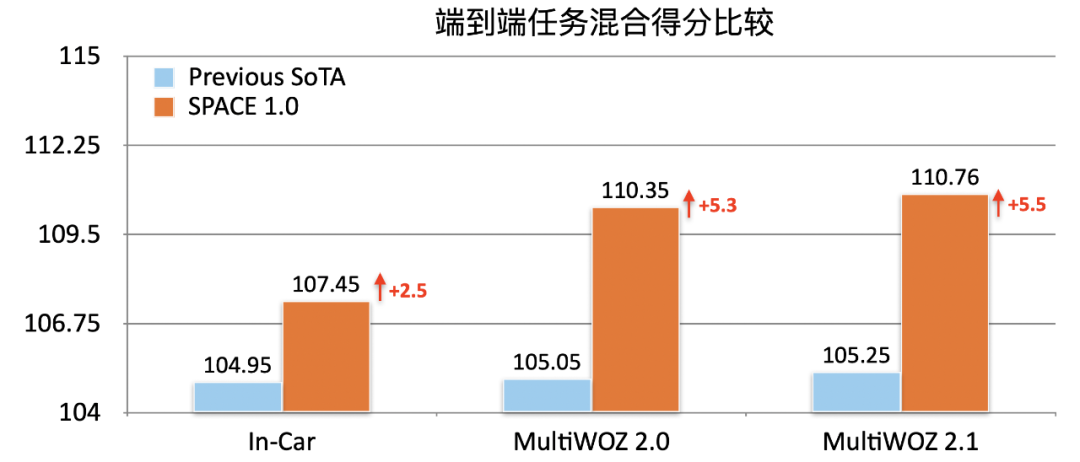
圖 9:各數據集端到端得分總體結果比較
以上的結果充分證明了半監督預訓練的效果。同時我們也做了低訓練資源下實驗,發現在利用不同訓練數據比例下,我們的模型都保持著顯著的效果提升。如圖 10 所示,SPACE1.0 模型在僅利用 5% 訓練數據量下就能夠和利用全量 100% 訓練數據的基于 GPT-2 的對話模型 SimpleTOD 可比,僅利用 10% 訓練數據量就直接超過了利用全量訓練數據量的基于 T5 的對話模型 MinTL。
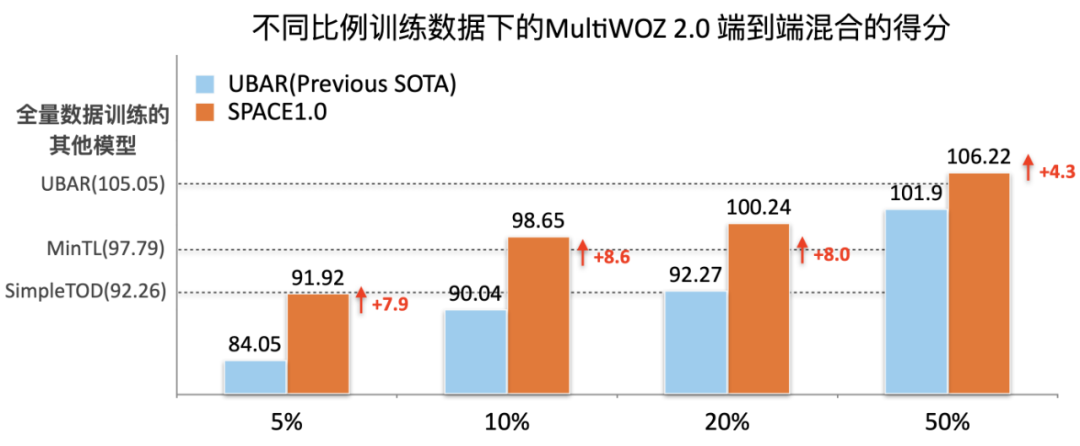
圖 10:低資源訓練下端到端得分結果比較
我們也進行了案例分析,從圖 11 中可以發現,相比之前的 SOTA 模型,SPACE1.0 模型能夠預測出更加正確的對話動作,因此,合理的對話策略能夠提升整體的端到端任務完成效果。
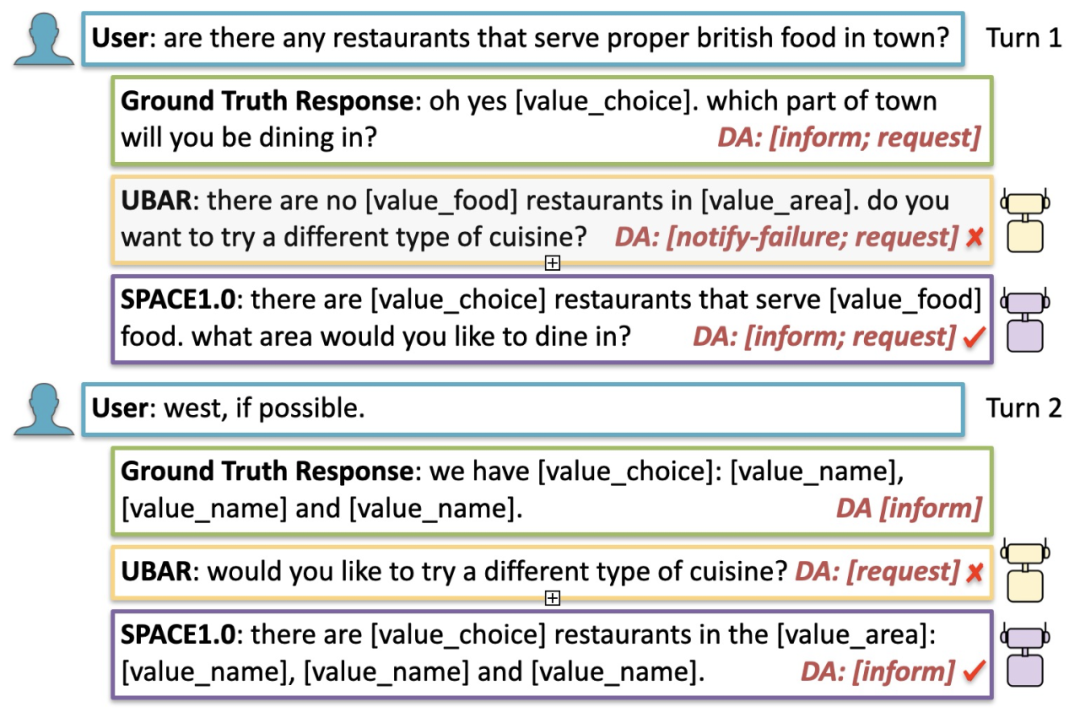
圖 11:案例分析 Case Study
SPACE1.0 模型(即 GALAXY)目前在 MultiWOZ 官網上仍然排名第一,成績截圖如下所示:
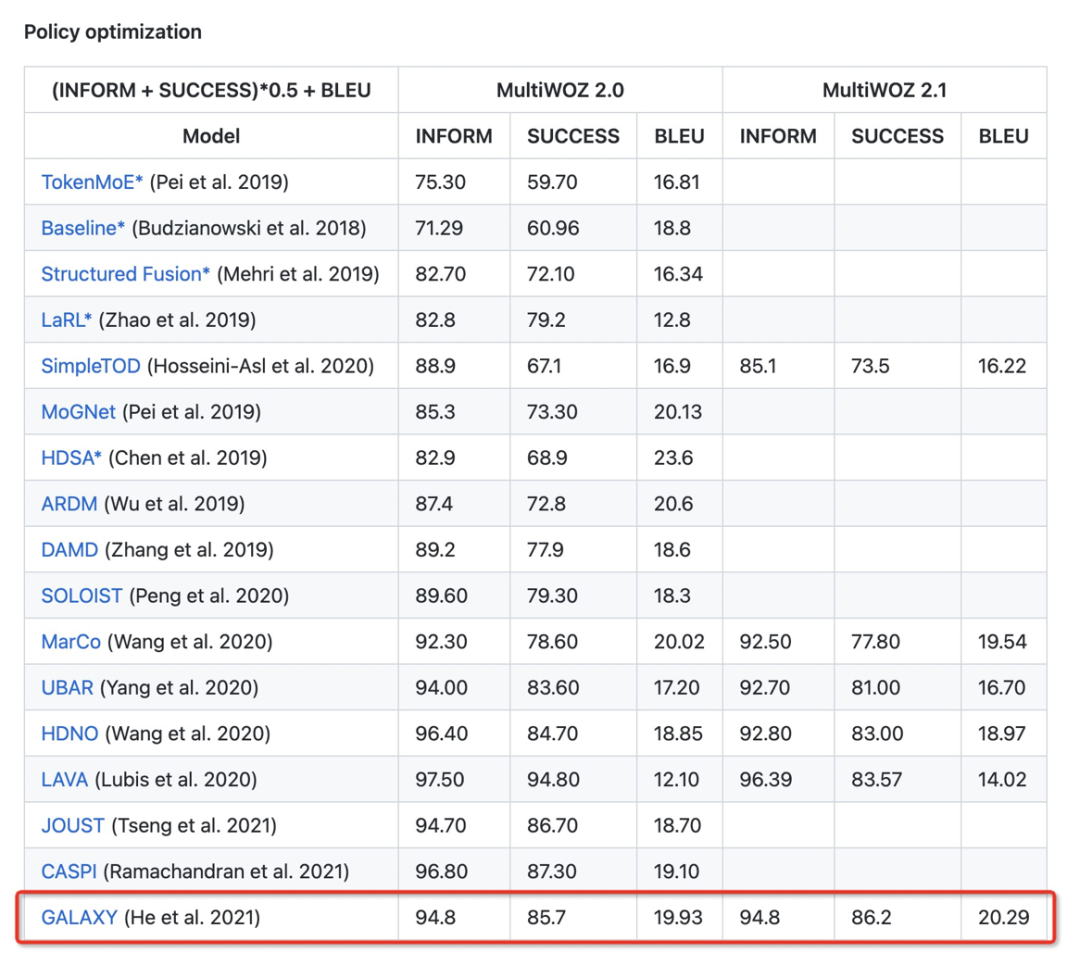
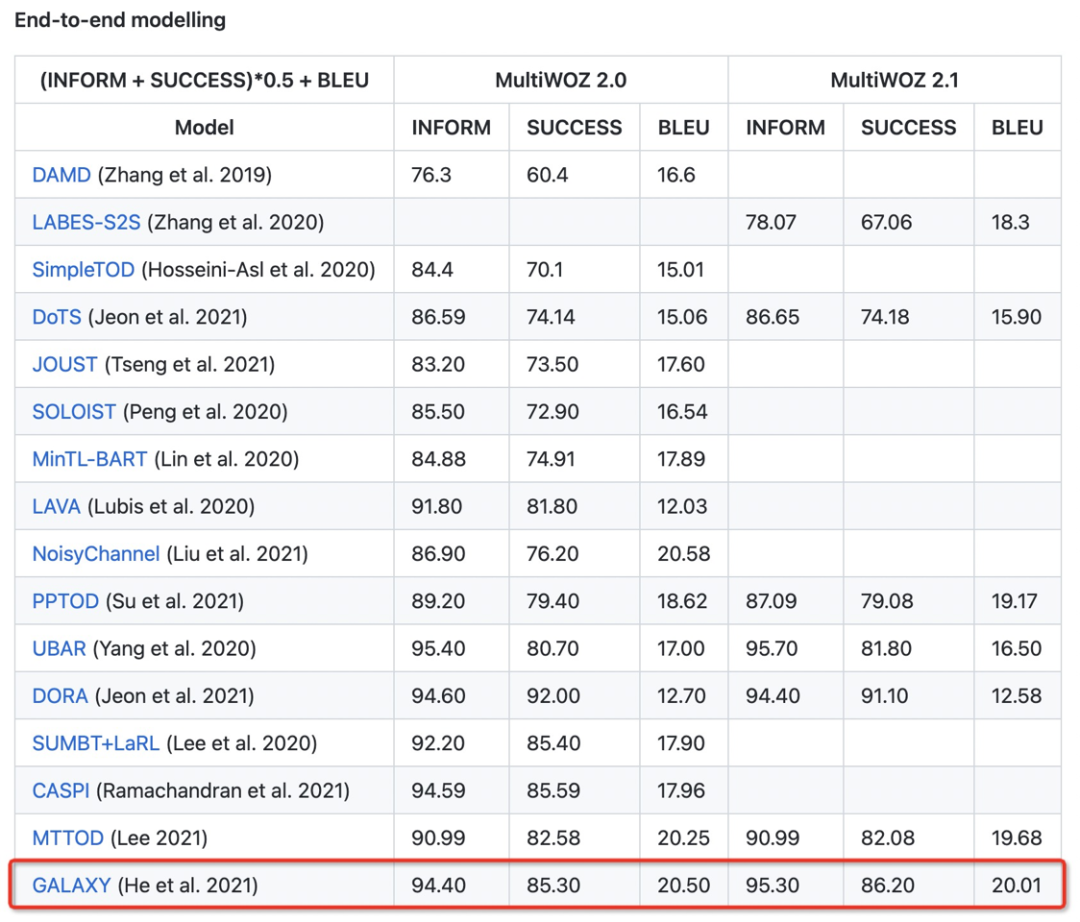
7. 總結展望
本工作主要介紹了如何通過半監督預訓練向大模型中注入特定的人類標注知識,從而使得模型在下游任務上有更加卓越的效果。和過往的半監督學習相比,我們關注的不再是如何降低對標注數據量的依賴,而是如何更加高效地融入特定標注知識,如下圖 12 所示:
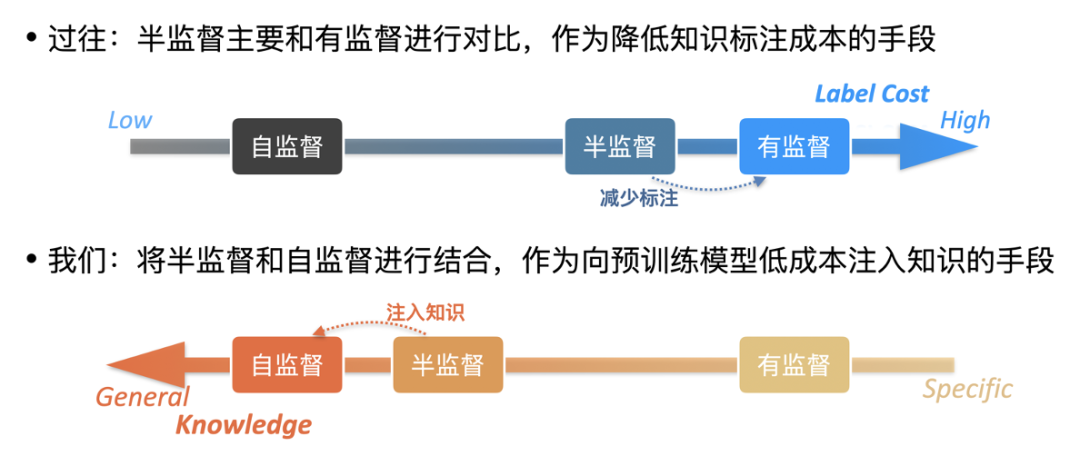
圖 12:將半監督學習從下游訓練推廣到預訓練過程
在后續的工作里,怎樣將該范式進一步推廣到各類 NLP 的任務中去,打造出一套有實用價值的半監督預訓練 SPACE 模型體系,是需要持續探索的方向,具體包括:
- 知識自動選擇:如何利用算法模型自動選擇出合適的任務知識,從大量標注數據集中找出對目標下游任務最有用的數據集集合來進行半監督預訓練是使得該范式成為通用范式的亟需研究問題。
- 半監督算法:目前我們嘗試的是基于一致性正則化的半監督預訓練方案,但整個半監督領域還有 self-taught, co-training, deep generative modeling 等諸多方法,如何綜合利用他們是一個重要研究課題。
- 異構知識統一:本文中我們僅關注了分類標注知識,針對其他類型的標注知識,序列標注知識、層次化分類知識、回歸標注等,如何進行更好的形式化表示,統一地融入到一個預訓練模型中也是一個開放問題。
- 知識注入評價:如何更加定量且顯式地度量出特定任務知識注入的程度,利用 probing 等方法對知識融入有個合理的評價也值得進一步的研究探索。
預訓練模型的打造離不開強大的 AI 算力支持,SPACE 模型的研發也得益于阿里云 EFLOPS 團隊提供的高效算力服務,在此鳴謝!?