那個在國際翻譯大賽上奪冠的模型,字節剛剛給開源了
Transformer 等文本生成主流算法的逐詞生成對適合并行計算的 GPU 并不友好,會導致 GPU 利用率低下。并行生成有助于解決這一問題。前不久,字節跳動火山翻譯團隊的并行生成翻譯系統 GLAT 拿下了 WMT2021 De-En/En-De 的雙料冠軍。為了幫助大家跟進這一成果,火山翻譯開源了一個名為 ParaGen 的 Pytorch 深度學習框架,其中包含 GLAT 模型復現和 WMT21 的代碼。

代碼地址:https://github.com/bytedance/ParaGen
文本生成是自然語言處理的一個重要研究方向,具有廣泛的應用場景。比如文本摘要、機器翻譯、文案生成等等。不同于一般的分類、標注等任務,文本生成不僅要考慮每個詞的重要性,提高單詞的預測準確性,也要兼顧詞語之間的搭配,保持整個文本的流暢度。因此一般的做法是逐詞生成,每產生一個詞都會考慮和已有詞的關系。
經過以上步驟進行文本生成的這類模型稱為自回歸模型,比如目前主流的生成算法 Transformer。該模型首先對原始文本進行編碼,比如機器翻譯中的待翻譯文本或者是文本摘要中的原文。然后再從左到右逐詞解碼產生翻譯好的文本或是摘要。基于該算法的開源軟件有 tensor2tensor、fairseq 等。然而逐詞生成對適合并行計算的 GPU 來說并不友好,導致 GPU 利用率低下,句子生成速度慢。因此近年來有很多研究探索如何并行生成文本,降低響應延時。
此前,字節跳動人工智能實驗室 (AI-Lab) 的火山翻譯團隊研發了并行生成的翻譯系統 Glancing Transformer (GLAT)(參見《ACL 2021 | 字節跳動 Glancing Transformer:驚鴻一瞥的并行生成模型》?),并且使用它一舉拿下了 WMT2021 De-En/En-De 的雙料冠軍 (參見《并行生成奇點臨近!字節跳動 GLAT 斬獲 WMT2021 大語種德英自動評估第一》?),彰顯出了并行生成的強大潛力。ParaGen 正是在這個背景下應運而生。團隊的研究者們發現,對于并行生成來說,單單是模型的改進已經不能滿足研究的需求,訓練方法、解碼算法的改進也變得日益重要。而 ParaGen 的開發正是為了解放并行生成研究的生產力。
在 ParaGen 中,火山翻譯開源了 GLAT 模型復現和 WMT21 的代碼,幫助大家更好地去跟進并行生成的研究結果。在未來,火山翻譯也將開源更多并行生成相關的技術,推動并行生成技術的進一步發展,幫助并行生成這一技術逐漸走向更多的生產應用。與此同時,除了并行生成以外,ParaGen 也支持了多元化的自然語言處理任務,包括自回歸翻譯、多語言翻譯、預訓練模型、生成任務、抽取任務、分類任務等,并提供從零復現的代碼,幫助剛接觸自然語言處理研究的同學更快進入到研究的狀態。
ParaGen 讓開發更靈活、更自由、更簡便
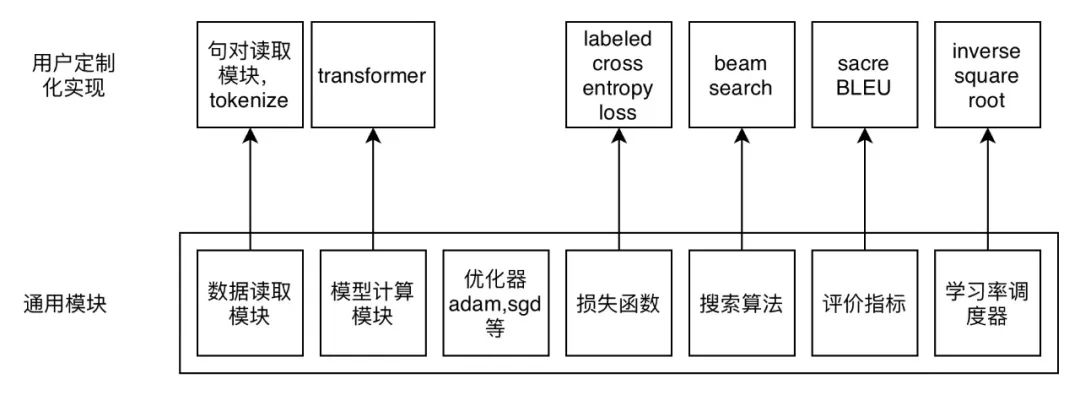
ParaGen 支持了多達 13 種可自定義模塊,包括數據讀入、數據預處理、數據采樣、數據加載、網絡模塊、訓練模型、推斷模型、優化目標、搜索算法、優化器、數值規劃器、訓練算法和評價目標,相比于同類的文本生成框架,大大提高了二次開發的靈活性。而對于不同的模塊,ParaGen 采用微內核的設計,每個模塊只提供一些通用基本的實現,彼此之間互相獨立,比如數值優化器中 InverseSquareRootRateScheduler、網絡模塊的 positional embedding、數據讀入的 JsonDataset 等。也正是得益于這細致的 13 類模塊拆解,ParaGen 可以更方便地進行自定義。例如需要實現 glancing training 的方式,在 ParaGen 里面僅僅只需要重載一個 forward_loss 函數,就可以模塊化的實現自定義的訓練。
import torch
from paragen.trainers.trainer import Trainer
from paragen.trainers import register_trainer
@register_trainer
class GLATTrainer(Trainer):
"""
Trainer with glancing strategy
"""
def _forward_loss(self, samples):
glancing_output = self._generator(**samples['net_input'])
fused_samples = self._fusing(samples, glancing_output)
logging_states = self._criterion(**fused_samples)
return loss
不同于既往的過程式開發,ParaGen 更偏向于組裝式開發。過程式開發中,框架固定一個流程代碼,用戶則想辦法將各個模組填入到流程里面。而 ParaGen 的組裝式開發則是完全不同。想象你目前正要實現一個任務,ParaGen 像是一個工具箱,你可以根據自己想要的功能組裝出一個完整的流程出來,比如可以選擇合適的 Dataset 類來進行數據讀取、選擇 Sampler 來進行 batch 組合、選擇 Metric 來進行結果評估、甚至定義自己的訓練流程等等。而在碰到了沒有實現的工具時,ParaGen 的工具又可以作為父類使用,通過重載一小部分的函數來定制自己的專屬工具,以適配更多的任務。
與此同時,ParaGen 代碼結構拆解的更加細致,用戶只要花 2-3 小時閱讀代碼就能了解整個項目的框架,從而定制自己的任務。不僅如此,ParaGen 也提供了相應的教程,幫助初學者認識學習了解整個 ParaGen 代碼的基本知識和使用方式。
ParaGen 讓開發更穩定
ParaGen 能夠很好的支持不同方向的同時開發。ParaGen 支持可插拔的方式進行代碼開發,允許用戶脫離框架進行開發。用戶可以在任何的目錄下開發自己專屬的模塊,并通過 --lib {my_lib} 命令進行導入 ParaGen 執行,使得二次開發代碼獨立于主代碼,更加有利于二次開發代碼的維護和主框架的穩定,保證了不同項目開發的并行性和穩定性,不會引起彼此代碼的沖突。
ParaGen 采用 apache2 開源協議,該協議十分寬松,比如允許其他開發人員二次開發后閉源等,方便更多的優秀開發人員或者團隊的參與。
作為首款翻譯質量超過傳統自回歸模型的并行文本生成軟件,ParaGen 證明了同時兼顧速度和質量的可行性,為后續研究提供了可復現的實現。在應用層面,極大地滿足了終端部署的低功耗快速響應的性能需求。在后續的開發中,ParaGen 一方面會探索更多并行算法,比如條件隨機場模型,進一步提高性能。另一方面也會開拓更多的部署環境,比如移動終端,嵌入式系統等等,方便更多實際場景的應用開發。?