這五個字,能優(yōu)化你80%的程序性能問題
本篇關注程序性能優(yōu)化。聚焦這個主題,本是偶然。始于玩笑,終于本心。本想找點高大上的讓人直呼牛逼的東西,奈何能力有限,只能給大家一些既便宜、又好用、還簡單的普通東西了,不知道你們會不會喜歡。
分為五個主題,分別是『池』『序』『分』『減』『并』:
一、『池』字訣

池化,降低可重用對象的創(chuàng)建和回收代價。
不知道你們發(fā)現沒有,無論是電影還是游戲中,主角總是孤膽單英雄,最多三五成群。但Boss不一樣,Boss手一揮,必須有一群小怪一擁而上,畢竟幫主角刷點經驗也是好的。
小怪的特點是:數量多,容易死,循環(huán)用。電影不可能請?zhí)嗟娜貉荩虼宋覀兘洺D馨l(fā)現一人分飾多角的超級龍?zhí)住6螒蚶铮膊豢赡苊恳粋€小怪都完全不一樣,因為創(chuàng)建它們還挺消耗時間和內存的。哈哈,現在你知道了,你正在打的小怪很可能與剛剛死前掉金幣的那只是同一只。
代碼中,如果某些對象有重用的價值,并且創(chuàng)建的時候會消耗大量的CPU或IO資源。那么在出現性能瓶頸的時候,一個合理的優(yōu)化方向就是池化。剛剛例子中,對游戲中小怪進行池化,通常稱為對象池,類似的還有線程池、連接池等。
灰太狼:我一定會回來的~
二、『序』字訣
順序讀寫,減少隨機IO,減少cache miss。
『內存順序讀寫的性能要遠好于隨機讀寫』,『磁盤順序讀寫的性能要遠好于隨機讀寫』。類似的話我相信很多程序員都似曾相識,然而,我同樣相信很多程序員在寫代碼的時候從來沒有認真考慮過這件事件。

當年做游戲的時候,我見過很多人使用hash表存儲場景中的各類對象:花鳥魚蟲、白云蒼狗,并每幀遍歷hash表以確定位置或攻擊信息。我建議他們改成遍歷有序表的快照(MVCC了解一下),其中一個原因是可以提高遍歷性能,而另一個更重要的原因是可以在遍歷的過程中修改表結構(插入刪除對象)。
有序表一種基于有序數組的字典結構,C#中有一個名為SortList的標準庫實現
多年以來,CPU一直是計算機中跑得最快的部件,也因此被慣出來一個多吃多占的毛病。無論是讀內存還是讀磁盤,從來不講究按需分配,而是大塊大塊的拿數據。當把一大塊連續(xù)的數據拿到手里的時候,CPU自己也知道一次肯定吞不下,但總覺得多吞幾次就好了。
但這個特點其實是需要程序員去配合的,如果代碼使用連續(xù)內存的數據結構,比如array,那在遍歷的時候就相當于投其所好;而如果代碼使用hash表,則遍歷的時候cache miss的可能性就大大增加。
鑒于java在服務器領域的成功,有些公司使用java開發(fā)游戲服務器,我建議他們換一種語言。原因是游戲服務器很可能需要處理大量跟點、向量等三維空間相關的運算,而在java中,默認一切都是對象。于是在一個Vertex(頂點)數組中,看似連續(xù)的Vertex對象在物理內存中實際上是離散的,這樣的遍歷效果就會差很多。而對C++, Golang,甚至C#這類語言來說,它們都支持struct。當把Vertex定義為struct的時候,一個Vertex數組的占用的內存就是連續(xù)的,遍歷效果會比java好很多。
在后端的技術棧中,kafka絕對是一個非常另類的存在。擅長kafka的人,覺得無它不歡,而不了解它的人,則覺得可有可無。關于kafka為什么這么快的討論有很多,其中有一個繞不過的原因是:kafka會順序讀寫磁盤。我們通常認為磁盤的讀寫性能遠低于內存,但實際上,在關閉fsync的前提下,SSD固態(tài)硬盤的順序讀寫速度與內存的隨機讀寫速度是相當的,大概都是1 GiB/s,而如果是隨機讀取,則SSD固態(tài)硬盤SSD的Seek速度會直降到70MiB/s,速度下降到1/15。
三、『分』字訣
鴻蒙伊始,民智不開。為教化萬民,神器計算機降世。下凡走得急,零件沒湊齊。計算機天生殘疾,CPU與其它IO部件速度差異過大。為平衡這種速度差異,人間有智者布局各方,分字訣應劫而生,它們是分批、分幀、分頁、分時、分片、分區(qū)、分庫、分表、分離。
1. 分批≈緩存+緩沖
在系統設計之初,每次修改對應一次IO可能是最簡單、最直接的設計,不過隨著系統流量變大,IO可能會很快成為系統瓶頸。相比于內存操作來說,磁盤IO吞吐小,網絡IO延遲大。為了減少IO與內存之間的速度差異,爭取每次IO都物盡其用才是上上之選。將多次IO合并為一次,減少磁盤IO(特別是fsync)的次數和網絡IO的round-trip次數。
所謂讀優(yōu)化靠緩存,寫優(yōu)化靠緩沖,而分批≈緩存+緩沖。往小了說,緩存就是一塊用于讀內存,緩沖就是一塊用于寫的內存。往大了說,緩存就是Redis,緩沖就是Kafka。這些都是在微服務體系中司空見慣的招數,不用我多說。
分批優(yōu)化化身千萬,可謂無孔不入,甚至多數流行的數據中間件都提供了批量IO操作的API:
- MySQL的insert語句支持在values中一次插入多行數據。
- Redis的Pipeline操作可以批量執(zhí)行多個操作。
- ElasticSearch有專門的_bulk api支持在單次調用中索引或刪除多條數據。
- Kafka更是把分批操作貫徹到了極致:它根本就不提供發(fā)送單條消息的功能,使用send()發(fā)送的單條消息其實會被Kafka偷偷在內存里攢起來,是的你被騙了。
- 包括MySQL, Redis在內的各類數據中間件,跟WAL日志落盤時機相關的配置中,一定有一條是只寫Page Cache,然后后臺線程定期刷盤的策略。(注:嚴格說來,Redis那個不能叫WAL,因為它是寫后日志。)
- 在游戲引擎中,把頂點數據提交的顯卡的Draw Call也都是合并批次的,否則會卡死你。
分批的缺點是在數據一致性差,無論是緩存還是緩沖都存在同樣的問題。緩存的話,如果不存在嚴格的一致保障手段,往往只建議展示用,不作為數據修改依據。參考文章《緩存就像showgirl,看看就行了》。而緩沖在內存的這段時間內,如果進程崩潰了,會丟失部分數據。因此在選擇分批優(yōu)化的時候,架構師需要仔細斟酌數據一致性問題,比如是否可以接受偶爾丟失數據,或者是否需要在數據輸入端提供重試策略。
但不管如何,分批都可能是最重要的IO優(yōu)化手段:它邏輯簡單,不涉及多線程并發(fā),對數據結構沒有特殊的要求,系統改造成本低。可以說,無論何時遇到IO性能瓶頸,分批改造都應該是順位第一的候選方案。
2. 分幀、分頁、分時
1)分幀,是專用于單線程+阻塞IO的平滑技術
很多時候,由于受框架限制(比如游戲或網頁渲染),我們不得不在單一線程中同時處理用戶邏輯與IO操作,這時如果IO消耗時間過長,就會阻塞用戶邏輯代碼,從而讓用戶感覺到卡頓現象。
Redis由于其單線程特性,很多耗時比較長的操作也需要分攤到多幀執(zhí)行。比如hash表的rehash操作,當表的鍵值對過多時,rehash會產生的龐大的計算量,如果一次性完成可能會導致server對外暫停服務。Redis選擇將rehash分攤到多次執(zhí)行,稱為漸進式rehash。
另外,對于比較大的hash表,hgetall一次性獲取所有數據可能會卡死server進程甚至導致宕機,建議采用hscan來分次獲取hash表中的數據。Redis中像這類支持迭代式掃描的命令有四個,分別是:scan, sscan, hscan和zscan。
2)分頁可以看作是一種另類的分幀操作:
在運營類項目中,由于后臺數據龐大,很多時候無法在單一網頁中顯示,通過分頁顯示,可以避免一次性數據獲取帶來的DB加載壓力和網絡傳輸壓力。
3)分時復用指多對象輪流使用同一個硬件的技術,多見于跟硬件打交道的底層軟件。
比如,分時操作系統:一種采用時間片輪轉的方式同時為幾個甚至幾百個用戶服務的操作系統;分時復用網絡:指采用同一物理連接的不同時段來傳輸不同的信號,以達到多路傳輸目的的網絡基礎設施。
但有一種分時復用技術,雖然它的名字里沒有分時二字,卻與后端開發(fā)息息相關,那就是IO多路復用(洋名:Reactor):單線程同時監(jiān)聽多個文件句柄,哪個句柄就緒,就通知應用線程讀寫哪個句柄的技術。
3. 分片、分區(qū)、分庫、分表
隨著77年恢復高考,這些年近視的年輕人越來越多了,于是人們越發(fā)的無法區(qū)分那些換個馬夾兒就重新出來混的二貨們。就像洗發(fā)水,猛一看飄柔、海飛絲、潘婷百花齊放,仔細一看,全特么是寶潔的。沒錯,這么土味的名字,竟然不是國貨,害我自以為愛了這么多年的國。
分片、分區(qū)、分庫、分表也一樣,名字挺花,療效一樣,都是為了突破單體性能限制的水平擴展的方案,洋名字:scale out。因為方案類似,大家遇到的問題自然也是相同的。它們首先要搞定的就是路由問題,也就是把數據拆分之后,某個key儲存到哪個分片/區(qū)/庫/表的問題。路由方案可簡單分為兩類:
一種是非確定性路由,即相同的key多次路由可以映射到的不同的計算單元,常見方案有:輪詢、隨機。非確定性路由多用于無狀態(tài)節(jié)點間的任務分配,比如nginx把請求隨機分配到無狀態(tài)的微服務節(jié)點上。
另一種是確定性路由,即相同的key多次路由必須映射到的相同的存儲單元,常見方案為:區(qū)間,Hash,配置表。確定性路由多用于有狀態(tài)節(jié)點間的任務分配,比如Kafka按user_id把來自同一用戶的請求映射到同一個存儲分區(qū)。
以MySQL為例,它支持四種分區(qū)類型,分別是Range, List, Hash, Key。因為跟存儲密切相關,它們全是確定性路由算法,其中Range對應區(qū)間,List是配置表,Hash與Key則都是Hash類型。
除了應用于多機水平擴展,在單機內存中分片方案也有應用。比如JDK1.8之前,ConcurrentHashMap通過將整個Map劃分成N(默認16個)個Segment,而每個Segment各自持有獨立的鎖,從而從整體上減少并發(fā)沖突。
4. 分離
分離式設計是一種架構模式,通過把單元功能單一化、純粹化、專業(yè)化,可以降低開發(fā)和維護成本,同時提高功能單元的可復用性,這在設計模式中我們通常稱之為單一職責。目前,常見的分離式架構設計有讀寫分離、存算分離。
讀寫分離在國人的文章中常用于指代MySQL寫走主庫,而讀走從庫,這有些狹義了。廣義上讀寫分離的重點是:讀路徑不關心寫,寫路徑不關心讀,兩者均關注于自己的功能實現,而毋需為對方的作出任何犧牲或讓步。更多的細節(jié)我在文章《23.kafka心中的事件溯源》中有更詳細的描述,感興趣的讀者可以點擊查看。
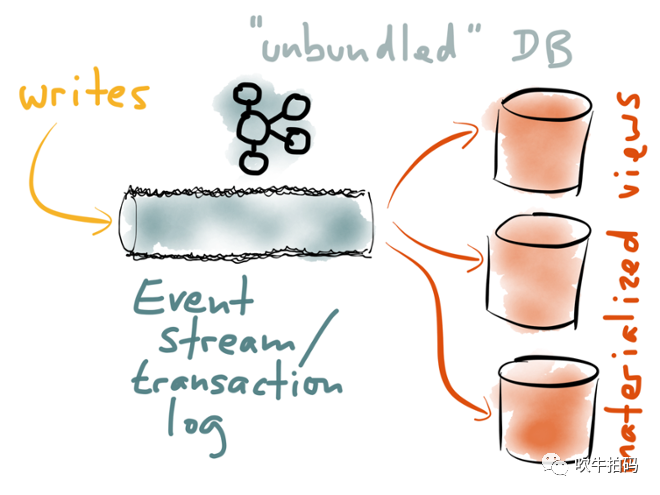
這里我想強調的是,讀寫分離是分離式DB(Unbunding Databases)的雛形。我們應該認識到,不存在一種單一的數據模型可以滿足所有的訪問模式。MySQL在線業(yè)務、Redis加速查詢、ES全文索引、DW離線分析,每一種衍生數據系統都有各自不可替代作用。
如上圖所示,通過統一寫端,派生讀端,可以形成一種遵循unix傳統的架構模型:單一任務做好單一事情,內部通過低級API(pipe)通信,外部通過高級語言(shell)組合。在分離式DB架構中,目前看來最合適的,能起到粘接劑作用的是Event Stream(Event Log)。期望未來有那么一天,我們能像在shell中寫ps | grep java一樣,寫出mysql | elasticsearch這樣的代碼,屆時就是分離式DB摘取王之桂冠的榮耀時刻。
如果說讀寫分離是拆功能,那么存算分離就是拆資源:把計算資源(CPU、內存)和存儲資源(磁盤)拆分開來。早期的云DB,其實是把單體DB搬到云上。人們很快發(fā)現云DB與單機DB的不同之處:一是隨著企業(yè)數字化轉型的深入,數量總量飆升,單機存儲捉襟見肘;二是在應對雙十一這類突發(fā)性流量時,計算峰值波動很大,這使得云DB對彈性伸縮能力要求極高。問題一可以通過分庫分表這類trick的方式緩解,但問題二對原有單體DB『存算一體』的架構提出了挑戰(zhàn)。于是,存算分離的架構應運而生,也就是云原生數據庫架構。

存算分離聽起來很云端,似乎跟我們平時的工作關系很小。但其實有一類架構它就在我們身邊,只是我們可能沒有意識到它也是存算分離架構,那就是微服務架構。計算節(jié)點無狀態(tài),存儲節(jié)點無計算;計算節(jié)點橫向擴展,存儲節(jié)點縱向擴展。
就像Duck Test講的:如果它看起來像鴨子、游泳像鴨子、叫聲像鴨子,那么它可能就是只鴨子。
四、『減』字訣
很多時候我們都講不要過早優(yōu)化,因為多數業(yè)務的初期,數據量都很少,任何設計都不太可能出現性能問題。反而業(yè)務上線后,由于進展不符合預期,導致調整業(yè)務邏輯的可能性更大。因此,怎么簡單怎么來才是最優(yōu)選擇,更快的實現業(yè)務比業(yè)務跑得更快優(yōu)先級更高。再者,你難道不覺得,就憑咱們拿的那萬兒八千的工資,在非常合理的情況下,就不應該寫出支撐千萬并發(fā)的系統,嘛?
萬一哪天系統開始出現性能瓶頸呢?該怎么辦?恭喜哈,這是好事,說明公司賺錢了,更重要是通過你的系統賺錢了。首先,你要做的第一件事就是跟老板要經費,經費到手,萬事不愁。然后,想辦法把系統恢復到數據量小的時候,這不就又順理成章的撐住了嘛?接著,經費沒地方花了不是?總得找個地方放啊,我私下認為你的錢包就是一個不錯的地方。
怎么把數據量再次變小呢?勸退用戶是一個辦法,但我估計老板可能太不樂意。
一個更可行的選擇是優(yōu)化數據結構和算法。比如給DB建索引就是一個辦法,同樣的查詢,同樣是千萬級的數據,有索引和無索引的查詢速度千差萬別,因為索引會極大減少掃描的數據行數。
另一個選擇是裁剪數據。就像Java的GC會定期清理垃圾一樣,如果你發(fā)現DB里的數據大部分都是過期無效的,或者是基本上不會再查詢到的數據,把過期數據歸檔,減少線上數據集的尺寸會是一個非常好的選擇。該操作系統改造成本極低,對線上業(yè)務無影響,對數據后臺則可以看心情逐步改造。所有相關人員都壓力不大,但效果卻是線上系統從此秒開,絕對騷得一批。其實前面提到的分片、分區(qū)、分庫、分表,也都是在變相減小單位處理單元上的數據量,只不過它們改造成本高,實施難度大。特別是,在決定采用分表之前,應慎重考慮歸檔是不是一個更合理的選擇。
當年做手游,發(fā)現游戲在4k屏的手機上運行極慢,手機的GPU根本帶不動,嘗試了各種優(yōu)化手段都不好使。誰曾想,最終解決問題的,竟然是降低游戲的輸出分辨率。
算法上縮,物理上減,現在連國家不開始提倡65歲退休了,我們的老系統也一定能才堅持幾年。
五、『并』字訣
終于到了并發(fā),一個大部分人都覺得應該有用,同時大部分人覺得用起來發(fā)怵的優(yōu)化手段。
如果說前面的『池』、『序』、『分』、『減』這幾條頂多算工程技巧,憑著我們聰明的大腦&反復思考就有可能搞清楚的話,『并發(fā)』這一條就是一個學術問題。換句話說,即使經過幾年的系統學習,也很少有人敢拍胸脯說自己的并發(fā)代碼無 bug。
并發(fā)真有這么難么?從編程語言的角度看,并發(fā)不就是多線程和死鎖么?賢者大神們的文章已經解釋得很清楚了,像《不環(huán)保的死鎖:破解死鎖,我們一般從下三路入手》、《線程安全,唯快不破》,只要規(guī)避掉死鎖的幾個必要條件,還不是怎么順手怎么寫?而且,運氣好的話還可以無鎖解決并發(fā)問題,不但準,而且快。
然而真相遠不是這么簡單。我們知道DB是解決數據安全和數據一致性問題的集大成者,我們嘗試從DB的角度來觀察一下。DB事務有ACID四個屬性,其中I是指隔離性Isolation,而它的研究核心就是并發(fā)問題。
毛爺爺說事務物是運動發(fā)展的,我覺得他說的是對的。兩年之前還沒有新冠肺炎呢,今天它已經像吃飯喝水一樣融入到了我們每個人的生活當中。在早期的ANSI SQL92標準中,涉及到的并發(fā)異象只有4種,然而發(fā)展到今天,常見的并發(fā)異象已經有7種之多,它們分別是:臟讀、臟寫、讀傾斜(不可重復讀)、寫傾斜,不可重復讀、幻讀、更新丟失。每一種并發(fā)異象都有不同的原因,以及不同的解決方案,而這還不是全部。其實我很想稍微給大家科普一下這些異象相關的內容,但是我發(fā)現細節(jié)實在太多了。我盲猜后端的知識體系中,可能有一半都跟并發(fā)有關。
沒人否定當年敲定SQL92標準的應該算DB專家吧?連當前ANSI的專家都沒能完全搞清楚事情,誰敢告訴我他輕松就能搞定?
所謂單機并發(fā)榨硬件,多機并發(fā)擴上限(scale out)。當單線程服務遭遇性能瓶頸,同時相應的機器硬件還有富余的時候,進行多線程改造從而充分壓榨硬件性能可能會是一個比較好的選擇。相應的,當單機性能已經無法滿足服務需要的時候,就需要進行分布式改造,通過水平擴容的方式提升整體服務能力。這兩種思路,對應到『分』字訣中,恰好是分表與分庫的區(qū)別:如果只是數據量上去了,CPU和內存壓力都不大,那就分表再壓榨一下;反之,如果流量大增,單機負載已經抗不住了,就可以考慮選擇分庫。
『并』字訣好使,但并不好掌握。引入并發(fā)會極大增大代碼復雜度,提高維持數據一致性的難度。就像分庫分表一樣,它的痛,只有用過的人才知道,因此,往往只會作為終極優(yōu)化手段。不用則已,用則需要有面對困難的勇氣和決心。
六、優(yōu)化即置換
作為一名程序員,你一定聽過這樣一句話:好的架構不是設計出來的,而是演化出來的。想要獲得什么,就要付出代價,就像想要討老婆,就得努力掙錢一樣。優(yōu)化會使代碼邏輯變得復雜,流程變得混亂。因此簡單設計,先上線,用錢堆,這些看起來很土的選擇很多時候可能比盲目優(yōu)化更能使我們遠離漩渦。
但無論如何,經常的,持續(xù)的分煎餅是個好習慣。
特別是山東煎餅,山東泰安的。