貝葉斯深度學習:一個統一深度學習和概率圖模型的框架
?人工智能(AI)的進展顯示,通過構建多層的深度網絡,利用大量數據進行學習,可以獲得性能的顯著提升。但這些進展基本上是發生在感知任務中,對于認知任務,需要擴展傳統的AI范式。
4月9日,羅格斯大學計算機科學系助理教授王灝,在AI TIME青年科學家——AI 2000學者專場論壇上,分享了一種基于貝葉斯的概率框架,能夠統一深度學習和概率圖模型,以及統一AI感知和推理任務。
據介紹,框架有兩個模塊:深度模塊,用概率型的深度模型表示;圖模塊,即概率圖模型。深度模塊處理高維信號,圖模塊處理偏推斷的任務。
以下是演講全文,AI科技評論做了不改變原意的整理:
今天和大家分享關于貝葉斯深度學習的工作,主題是我們一直研究的概率框架,希望用它統一深度學習和概率圖模型,以及統一AI感知和推理任務。
眾所周知,深度學習加持下的AI技術已經擁有了一定的視覺能力,能夠識別物體;閱讀能力,能夠文本理解;聽覺能力,能夠語音識別。但還欠缺一些思考能力。
“思考”對應推理推斷任務,具體指它能夠處理復雜的關系,包括條件概率關系或者因果關系。
深度學習適合處理感知任務,但“思考”涉及到高層次的智能,例如決策數據分析、邏輯推理。概率圖由于能非常自然的表示變量之間的復雜關系,所以處理推理任務具有優勢。
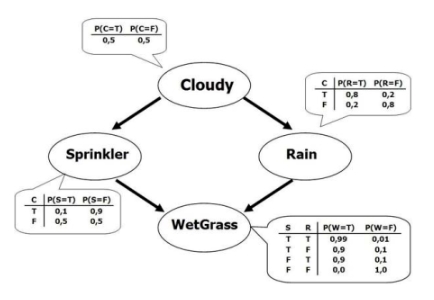

如上圖,概覽圖示例。任務是:想通過目前草地上噴頭開或關,以及外面的天氣來推斷外面的草地被打濕的概率是多少,也可以通過草地被打濕反推天氣如何。概率圖的缺點是無法高效處理高維數據。
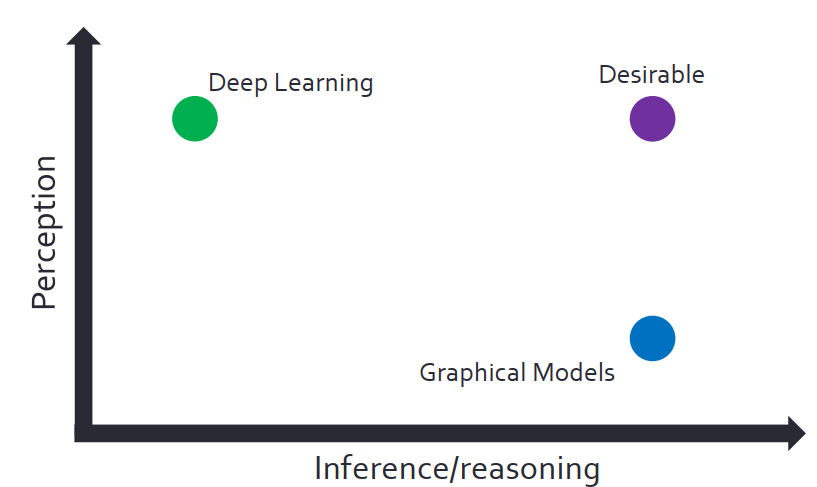
總結一下,深度學習比較擅長感知類的任務,不擅長推理、推斷任務,概率圖模型擅長推理任務,但不擅長感知任務。
很不幸,現實生活中這兩類任務一般是同時出現、相互交互。因此,我們希望能夠把深度學習的概率圖統一成單一的框架,希望達到兩全其美。
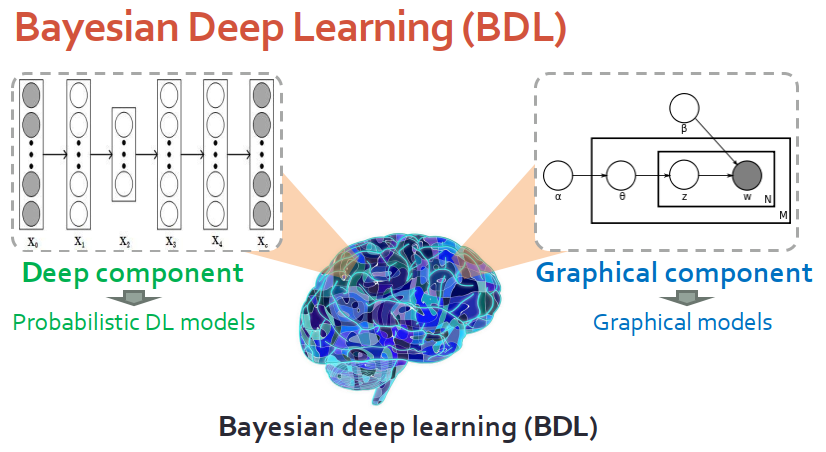
我們提出的框架是貝葉斯深度學習。有兩個模塊:深度模塊,用概率型的深度模型表示;圖模塊,即概率圖模型。深度模塊處理高維信號,圖模塊處理偏推斷的任務。
值得一提的是,圖模塊本質是概率型的模型,因此為了保證能夠融合,需要深度模型也是概率型。模型的訓練可以用經典算法,例如MAP、MCMC、VI。

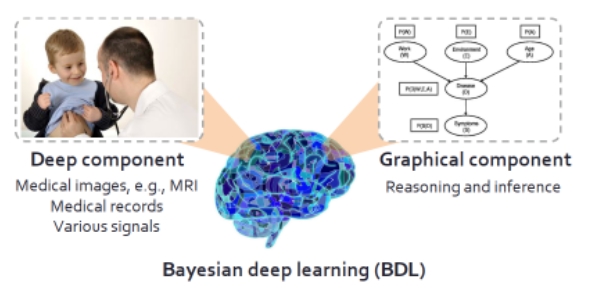
給具體的例子,在醫療診斷領域,深度模塊可以想象成是醫生在看病人的醫療圖像,圖模塊就是醫生根據圖像,在大腦中判斷、推理病癥。從醫生的角度, 醫療圖像中的生理信號是推理的基礎,優秀的能力能夠加深他對醫療圖像的理解。
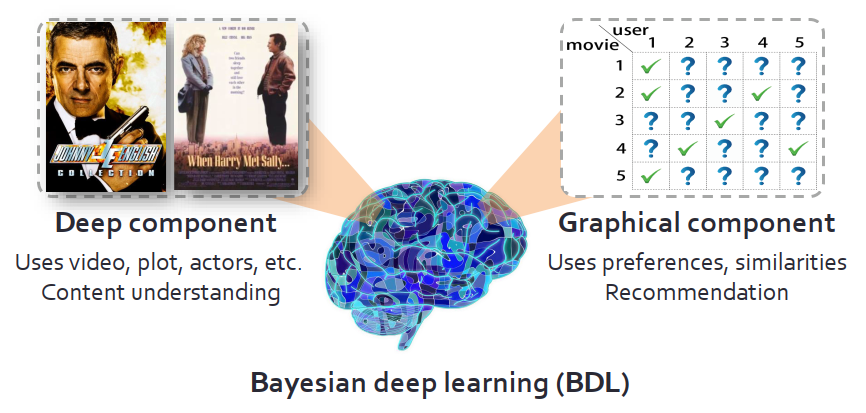
引申一下,電影推薦系統里,可以把深度模塊想象成是對電影的視頻情節、演員等內容的理解,而圖模塊需要對用戶喜好、電影偏愛之間的相似性進行建模。進一步,視頻內容理解和“喜好”建模也是相輔相成的。
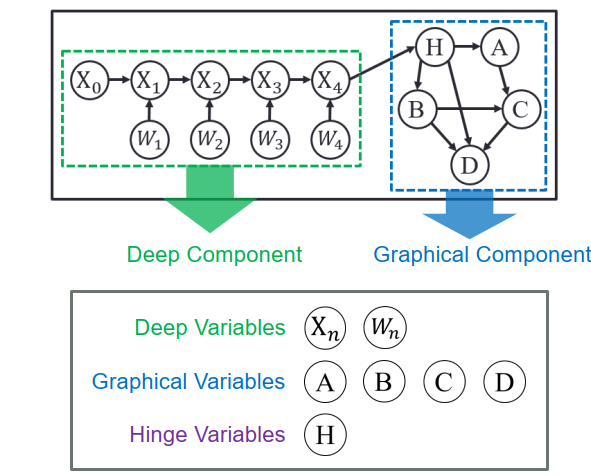
具體到模型細節,我們將概率圖模型的變量分為三類:深度變量,屬于深度模塊,假設產生于比較簡單的概率分布;圖變量,屬于圖模塊,和深度模塊沒有直接相連,假設它來自于相對比較復雜的分布;樞紐變量,屬于深度模塊和圖模塊中相互聯系的部分。
下面介紹該框架是如何在實際應用中效果。
推薦系統
推薦系統基本假設是:已知用戶對某些電影的喜好,然后希望預測用戶對其他電影的喜好。

可以將用戶對電影的喜愛寫成評分矩陣(Rating Matrix),該矩陣非常稀疏,用來直接建模,得到的準確性非常低。在推薦系統中,我們會依賴更多的信息,例如電影情節、電影的導演、演員信息進行輔助建模。
為了對內容信息進行建模,并進行有效提純,有三種方式可供選擇:手動建立特征,深度學習全自動建立特征、采用深度學習自適應建立特征。顯然,自適應的方式能夠達到最好的效果。
不幸的是,深度學習固有的獨立同分布假設,對于推薦系統是致命的。因為假設用戶和用戶之間沒有任何的關聯的,顯然是錯誤的。
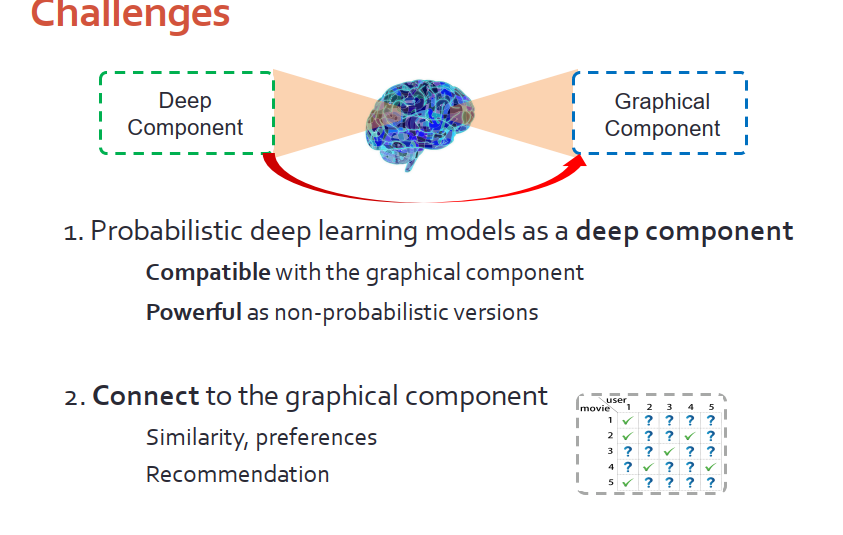
為了解決上述困難,我們推出協同深度學習,能夠將“獨立”推廣到“非獨立”。該模型有兩個挑戰:
1.如何找到有效的概率型的深度模型作為深度模塊。希望該模型能夠和圖模塊兼容,且和非概率型模塊的效果相同。
2.如何把深度模塊連接到主模塊里,從而進行有效建模。
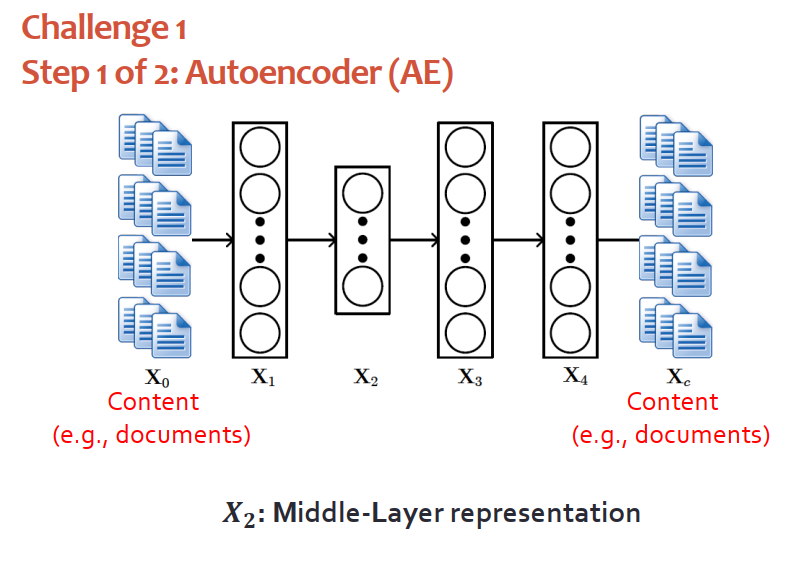
來看第一個挑戰。自編碼器是很簡單的深度學習模型,一般會被用在非監督的情況下提取特征,中間層的輸出會被作為文本的表示。值得一提的是,中間層的表示它是確定性的,它不是概率型的,和圖模塊不兼容,無法工作。
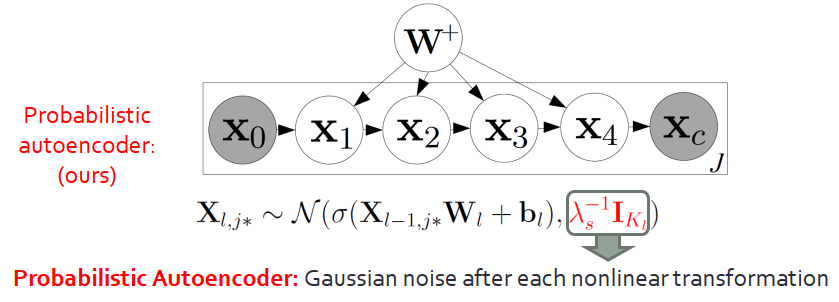
我們提出概率型的自編碼器,區別在于將輸出由“確定的向量”變換成“高斯分布”。概率型的自編碼器可以退化成標準自編碼器,因此后者是前者的一個特例。
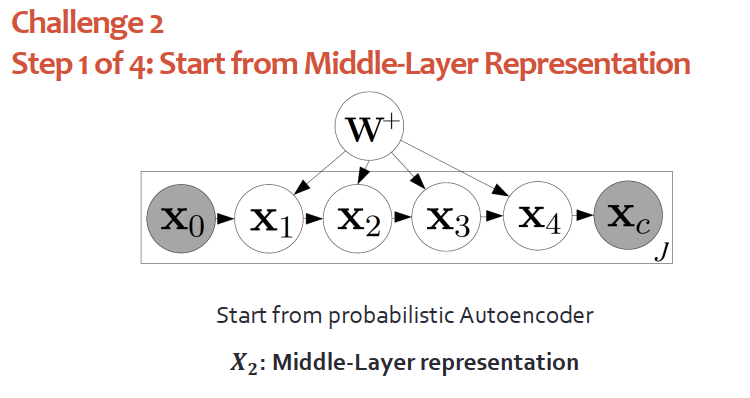
如何將深度模塊與圖模塊相聯系?先從高斯分布中提出物品j的隱向量:

然后從高斯分布中,提取出用戶i的隱向量:
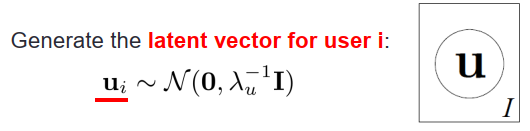
基于這兩個隱向量們就可以從另外高斯分布采樣出用戶i對物品j的分布,高斯分布的均值是兩個隱向量的內積。
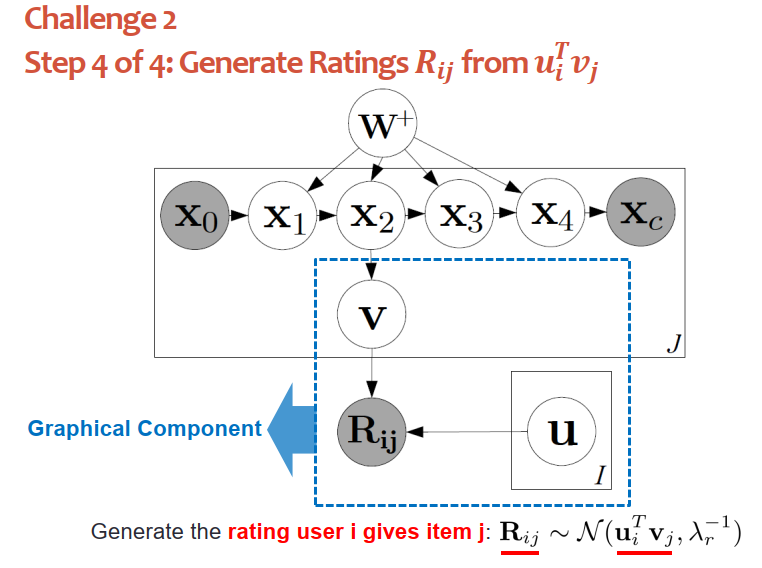
上圖藍框表示圖模塊。定義了物品、用戶、評分等等之間的條件概率關系。一旦有了條件概率關系,就能通過評分反推用戶、物品的隱向量,可以根據“內積”預測未知的背景。
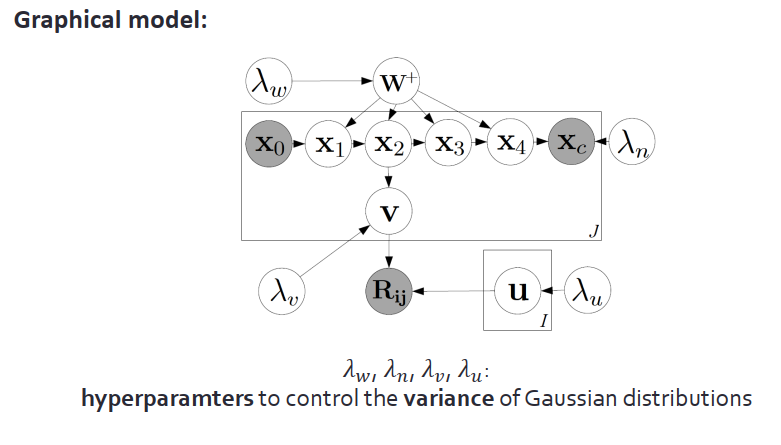
上圖是整個模型的圖解,其中λ是控制高斯分布方差的超參數。為了評測模型效果,我們用了三個數據集:citeulike-a、citeulike-t、Netflix。對于citeulike是用了每篇論文的標題和摘要,Netflix是用電影情節介紹作為內容信息。
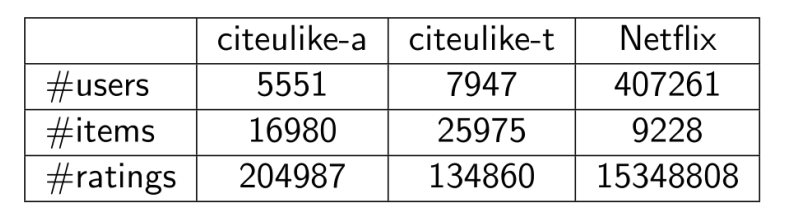
實驗結果如下圖所示,Recall@M指標表示,我們的方法大幅度超越基準模型。在評分矩陣更加稀疏的時候,我們模型性能提高幅度甚至可以更大。原因在于,矩陣越稀疏,模型會更加依賴內容信息,以及從內容提取出來的表示。
推薦系統性能提升能夠提升企業利潤,根據麥肯錫咨詢公司的調查,亞馬遜公司中35%的營業額是由推薦系統帶來的。這意味著推薦系統每提升1%個點,都會有6.2億美金的營業額提升。

小結一下,到目前為止,我們提出了概率型的深度模型作為貝葉斯深度學習框架的深度模塊,非概率型的深度模型其實是概率型深度模型的特例。針對深度的推薦系統提出層級貝葉斯模型,實驗表明該系統可以大幅度推薦系統的效率。
其他應用設計
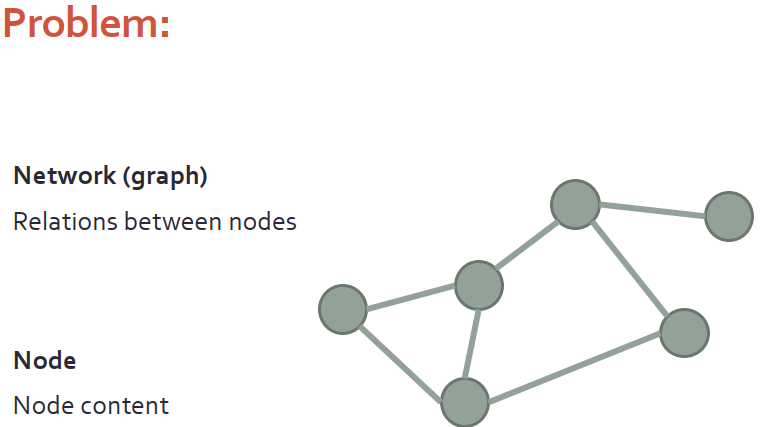
給定一個圖,我們知道邊,并了解節點的內容。此圖如果是社交網絡,其實就是表示著用戶之間的朋友關系,節點內容就是用戶貼在社交平臺上的圖片或者文本。這種圖關系,也可以表示論文的標題、摘要、引用等等聯系。
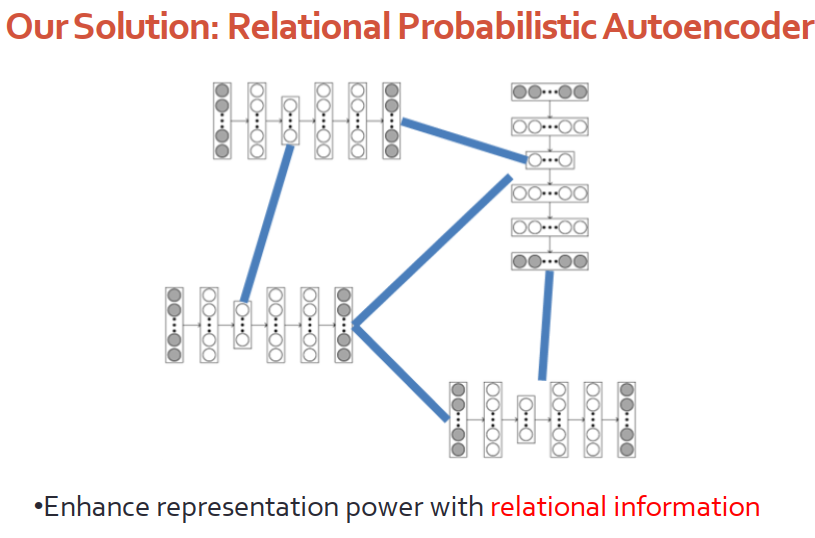
我們的任務是希望模型能夠學習到節點的表達,即能夠捕獲內容信息,又能夠捕獲圖的信息。
解決方案是基于貝葉斯深度學習框架,設計關系型的概率自編碼器。深度模塊專門負責處理每個節點的內容,畢竟深度學習能夠在處理高維信息是有優勢的;圖模塊處理節點節點之間的關系,例如引用網絡以及知識圖譜復雜的關系。

在醫療領域,我們關注醫療監測。任務場景是:家里有小型雷達,會發射信號,設計的模型希望能夠根據從病人身上反射的信號,發現病人是否按時用藥、用藥的次序是否正確。問題在于:用藥的步驟非常復雜,需要理清順序。
基于貝葉斯深度學習概率框架方法,用深度模塊處理非常高維的信號信息,用圖模塊對在醫療專有知識進行建模。
值得一提的是,即使對于不同應用的同一模型,里面的參數具有不同的學學習方式,例如可以用MAP、貝葉斯方法直接學習參數分布。
對于深度的神經網絡來說,一旦有了參數分布,可以做很多事情,例如可以對預測進行不確定性的估計。另外,如果能夠拿到參數分布,即使數據不足,也能獲得非常魯棒的預測。同時,模型也會更加強大,畢竟貝葉斯模型等價于無數個模型的采樣。
下面給出輕量級的貝葉斯的學習方法,可以用在任何的深度學習的模型或者任何的深度神經網絡上面。
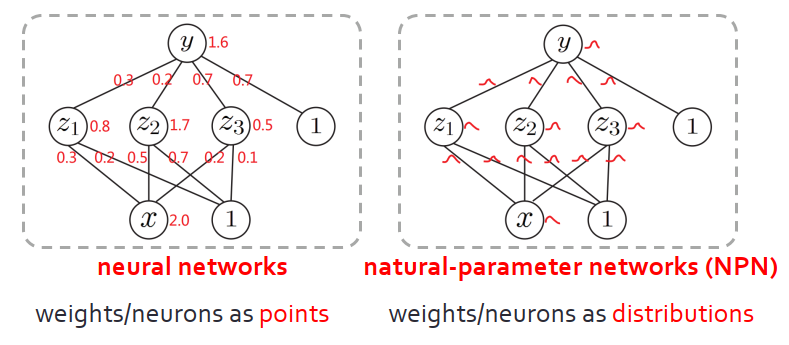
首先明確目標:方法足夠高效,可通過后向傳播進行學習,并“拋棄”采樣過程,同時模型能夠符合直覺。
我們的關鍵思路是:把神經網絡的神經元以及參數,看成分布,而不是簡單的在高維空間的點或者是向量。允許神經網絡在學習的過程中進行前向傳播、后向傳播。因為分布是用自然參數表示,該方法命名為NPN(natural-parameter networks)。?