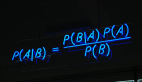機器學(xué)習(xí)算法集錦:從貝葉斯到深度學(xué)習(xí)及各自優(yōu)缺點
在我們?nèi)粘I钪兴玫降耐扑]系統(tǒng)、智能圖片美化應(yīng)用和聊天機器人等應(yīng)用中,各種各樣的機器學(xué)習(xí)和數(shù)據(jù)處理算法正盡職盡責(zé)地發(fā)揮著自己的功效。本文篩選并簡單介紹了一些最常見算法類別,還為每一個類別列出了一些實際的算法并簡單介紹了它們的優(yōu)缺點。
https://static.coggle.it/diagram/WHeBqDIrJRk-kDDY
目錄
- 正則化算法(Regularization Algorithms)
- 集成算法(Ensemble Algorithms)
- 決策樹算法(Decision Tree Algorithm)
- 回歸(Regression)
- 人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Network)
- 深度學(xué)習(xí)(Deep Learning)
- 支持向量機(Support Vector Machine)
- 降維算法(Dimensionality Reduction Algorithms)
- 聚類算法(Clustering Algorithms)
- 基于實例的算法(Instance-based Algorithms)
- 貝葉斯算法(Bayesian Algorithms)
- 關(guān)聯(lián)規(guī)則學(xué)習(xí)算法(Association Rule Learning Algorithms)
- 圖模型(Graphical Models)
正則化算法
它是另一種方法(通常是回歸方法)的拓展,這種方法會基于模型復(fù)雜性對其進行懲罰,它喜歡相對簡單能夠更好的泛化的模型。
例子:
- 嶺回歸(Ridge Regression)
- 最小絕對收縮與選擇算子(LASSO)
- GLASSO
- 彈性網(wǎng)絡(luò)(Elastic Net)
- 最小角回歸(Least-Angle Regression)
優(yōu)點:
- 其懲罰會減少過擬合
- 總會有解決方法
缺點:
- 懲罰會造成欠擬合
- 很難校準(zhǔn)
集成算法

集成方法是由多個較弱的模型集成模型組,其中的模型可以單獨進行訓(xùn)練,并且它們的預(yù)測能以某種方式結(jié)合起來去做出一個總體預(yù)測。
該算法主要的問題是要找出哪些較弱的模型可以結(jié)合起來,以及結(jié)合的方法。這是一個非常強大的技術(shù)集,因此廣受歡迎。
- Boosting
- Bootstrapped Aggregation(Bagging)
- AdaBoost
- 層疊泛化(Stacked Generalization)(blending)
- 梯度推進機(Gradient Boosting Machines,GBM)
- 梯度提升回歸樹(Gradient Boosted Regression Trees,GBRT)
- 隨機森林(Random Forest)
優(yōu)點:
當(dāng)先最先進的預(yù)測幾乎都使用了算法集成。它比使用單個模型預(yù)測出來的結(jié)果要精確的多
缺點:
- 需要大量的維護工作
決策樹算法
決策樹學(xué)習(xí)使用一個決策樹作為一個預(yù)測模型,它將對一個 item(表征在分支上)觀察所得映射成關(guān)于該 item 的目標(biāo)值的結(jié)論(表征在葉子中)。
樹模型中的目標(biāo)是可變的,可以采一組有限值,被稱為分類樹;在這些樹結(jié)構(gòu)中,葉子表示類標(biāo)簽,分支表示表征這些類標(biāo)簽的連接的特征。
例子:
- 分類和回歸樹(Classification and Regression Tree,CART)
- Iterative Dichotomiser 3(ID3)
- C4.5 和 C5.0(一種強大方法的兩個不同版本)
優(yōu)點:
- 容易解釋
- 非參數(shù)型
缺點:
- 趨向過擬合
- 可能或陷于局部最小值中
- 沒有在線學(xué)習(xí)
回歸(Regression)算法
回歸是用于估計兩種變量之間關(guān)系的統(tǒng)計過程。當(dāng)用于分析因變量和一個 多個自變量之間的關(guān)系時,該算法能提供很多建模和分析多個變量的技巧。具體一點說,回歸分析可以幫助我們理解當(dāng)任意一個自變量變化,另一個自變量不變時,因變量變化的典型值。最常見的是,回歸分析能在給定自變量的條件下估計出因變量的條件期望。
回歸算法是統(tǒng)計學(xué)中的主要算法,它已被納入統(tǒng)計機器學(xué)習(xí)。
例子:
- 普通最小二乘回歸(Ordinary Least Squares Regression,OLSR)
- 線性回歸(Linear Regression)
- 邏輯回歸(Logistic Regression)
- 逐步回歸(Stepwise Regression)
- 多元自適應(yīng)回歸樣條(Multivariate Adaptive Regression Splines,MARS)
- 本地散點平滑估計(Locally Estimated Scatterplot Smoothing,LOESS)
優(yōu)點:
- 直接、快速
- 知名度高
缺點:
- 要求嚴(yán)格的假設(shè)
- 需要處理異常值
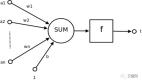
人工神經(jīng)網(wǎng)絡(luò)

人工神經(jīng)網(wǎng)絡(luò)是受生物神經(jīng)網(wǎng)絡(luò)啟發(fā)而構(gòu)建的算法模型。
它是一種模式匹配,常被用于回歸和分類問題,但擁有龐大的子域,由數(shù)百種算法和各類問題的變體組成。
例子:
- 感知器
- 反向傳播
- Hopfield 網(wǎng)絡(luò)
- 徑向基函數(shù)網(wǎng)絡(luò)(Radial Basis Function Network,RBFN)
優(yōu)點:
- 在語音、語義、視覺、各類游戲(如圍棋)的任務(wù)中表現(xiàn)極好。
- 算法可以快速調(diào)整,適應(yīng)新的問題。
缺點:
- 需要大量數(shù)據(jù)進行訓(xùn)練
- 訓(xùn)練要求很高的硬件配置
- 模型處于「黑箱狀態(tài)」,難以理解內(nèi)部機制
- 元參數(shù)(Metaparameter)與網(wǎng)絡(luò)拓撲選擇困難。
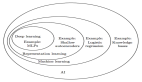
深度學(xué)習(xí)(Deep Learning)
深度學(xué)習(xí)是人工神經(jīng)網(wǎng)絡(luò)的最新分支,它受益于當(dāng)代硬件的快速發(fā)展。
眾多研究者目前的方向主要集中于構(gòu)建更大、更復(fù)雜的神經(jīng)網(wǎng)絡(luò),目前有許多方法正在聚焦半監(jiān)督學(xué)習(xí)問題,其中用于訓(xùn)練的大數(shù)據(jù)集只包含很少的標(biāo)記。
例子:
- 深玻耳茲曼機(Deep Boltzmann Machine,DBM)
- Deep Belief Networks(DBN)
- 卷積神經(jīng)網(wǎng)絡(luò)(CNN)
- Stacked Auto-Encoders
優(yōu)點/缺點:見神經(jīng)網(wǎng)絡(luò)
支持向量機

給定一組訓(xùn)練事例,其中每個事例都屬于兩個類別中的一個,支持向量機(SVM)訓(xùn)練算法可以在被輸入新的事例后將其分類到兩個類別中的一個,使自身成為非概率二進制線性分類器。
SVM 模型將訓(xùn)練事例表示為空間中的點,它們被映射到一幅圖中,由一條明確的、盡可能寬的間隔分開以區(qū)分兩個類別。
隨后,新的示例會被映射到同一空間中,并基于它們落在間隔的哪一側(cè)來預(yù)測它屬于的類別。
優(yōu)點:
- 在非線性可分問題上表現(xiàn)優(yōu)秀
缺點:
- 非常難以訓(xùn)練
- 很難解釋
降維算法
和集簇方法類似,降維追求并利用數(shù)據(jù)的內(nèi)在結(jié)構(gòu),目的在于使用較少的信息總結(jié)或描述數(shù)據(jù)。
這一算法可用于可視化高維數(shù)據(jù)或簡化接下來可用于監(jiān)督學(xué)習(xí)中的數(shù)據(jù)。許多這樣的方法可針對分類和回歸的使用進行調(diào)整。
例子:
- 主成分分析(Principal Component Analysis (PCA))
- 主成分回歸(Principal Component Regression (PCR))
- 偏最小二乘回歸(Partial Least Squares Regression (PLSR))
- Sammon 映射(Sammon Mapping)
- 多維尺度變換(Multidimensional Scaling (MDS))
- 投影尋蹤(Projection Pursuit)
- 線性判別分析(Linear Discriminant Analysis (LDA))
- 混合判別分析(Mixture Discriminant Analysis (MDA))
- 二次判別分析(Quadratic Discriminant Analysis (QDA))
- 靈活判別分析(Flexible Discriminant Analysis (FDA))
優(yōu)點:
- 可處理大規(guī)模數(shù)據(jù)集
- 無需在數(shù)據(jù)上進行假設(shè)
缺點:
- 難以搞定非線性數(shù)據(jù)
- 難以理解結(jié)果的意義
聚類算法
聚類算法是指對一組目標(biāo)進行分類,屬于同一組(亦即一個類,cluster)的目標(biāo)被劃分在一組中,與其他組目標(biāo)相比,同一組目標(biāo)更加彼此相似(在某種意義上)。
例子:
- K-均值(k-Means)
- k-Medians 算法
- Expectation Maximi 封層 ation (EM)
- 最大期望算法(EM)
- 分層集群(Hierarchical Clstering)
優(yōu)點:
- 讓數(shù)據(jù)變得有意義
缺點:
- 結(jié)果難以解讀,針對不尋常的數(shù)據(jù)組,結(jié)果可能無用。
基于實例的算法(Instance-based Algorithms)
基于實例的算法(有時也稱為基于記憶的學(xué)習(xí))是這樣學(xué) 習(xí)算法,不是明確歸納,而是將新的問題例子與訓(xùn)練過程中見過的例子進行對比,這些見過的例子就在存儲器中。
之所以叫基于實例的算法是因為它直接從訓(xùn)練實例中建構(gòu)出假設(shè)。這意味這,假設(shè)的復(fù)雜度能隨著數(shù)據(jù)的增長而變化:最糟的情況是,假設(shè)是一個訓(xùn)練項目列表,分類一個單獨新實例計算復(fù)雜度為 O(n)
例子:
- K 最近鄰(k-Nearest Neighbor (kNN))
- 學(xué)習(xí)向量量化(Learning Vector Quantization (LVQ))
- 自組織映射(Self-Organizing Map (SOM))
- 局部加權(quán)學(xué)習(xí)(Locally Weighted Learning (LWL))
優(yōu)點:
- 算法簡單、結(jié)果易于解讀
缺點:
- 內(nèi)存使用非常高
- 計算成本高
- 不可能用于高維特征空間
貝葉斯算法(Bayesian Algorithms)
貝葉斯方法是指明確應(yīng)用了貝葉斯定理來解決如分類和回歸等問題的方法。
例子:
- 樸素貝葉斯(Naive Bayes)
- 高斯樸素貝葉斯(Gaussian Naive Bayes)
- 多項式樸素貝葉斯(Multinomial Naive Bayes)
- 平均一致依賴估計器(Averaged One-Dependence Estimators (AODE))
- 貝葉斯信念網(wǎng)絡(luò)(Bayesian Belief Network (BBN))
- 貝葉斯網(wǎng)絡(luò)(Bayesian Network (BN))
優(yōu)點:
- 快速、易于訓(xùn)練、給出了它們所需的資源能帶來良好的表現(xiàn)
缺點:
- 如果輸入變量是相關(guān)的,則會出現(xiàn)問題
關(guān)聯(lián)規(guī)則學(xué)習(xí)算法
關(guān)聯(lián)規(guī)則學(xué)習(xí)方法能夠提取出對數(shù)據(jù)中的變量之間的關(guān)系的最佳解釋。比如說一家超市的銷售數(shù)據(jù)中存在規(guī)則 {洋蔥,土豆}=> {漢堡},那說明當(dāng)一位客戶同時購買了洋蔥和土豆的時候,他很有可能還會購買漢堡肉。
例子:
- Apriori 算法(Apriori algorithm)
- Eclat 算法(Eclat algorithm)
- FP-growth
圖模型(Graphical Models)
圖模型或概率圖模型(PGM/probabilistic graphical model)是一種概率模型,一個圖(graph)可以通過其表示隨機變量之間的條件依賴結(jié)構(gòu)(conditional dependence structure)。
例子:
- 貝葉斯網(wǎng)絡(luò)(Bayesian network)
- 馬爾可夫隨機域(Markov random field)
- 鏈圖(Chain Graphs)
- 祖先圖(Ancestral graph)
優(yōu)點:
- 模型清晰,能被直觀地理解
缺點:
- 確定其依賴的拓撲很困難,有時候也很模糊