













AI科舉制扼殺創(chuàng)新!你眼中的好模型只是「刷榜機器」
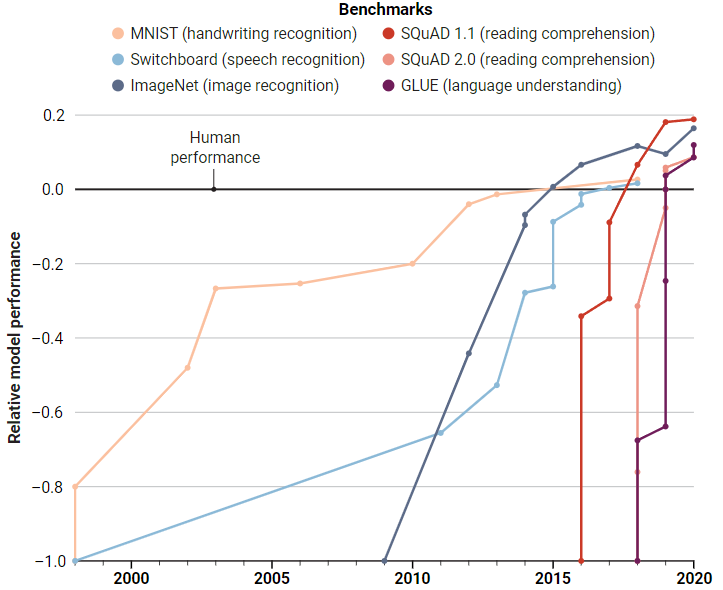
架構(gòu)2010年,基于ImageNet的計算機視覺競賽推出,激發(fā)了深度學習的一場算法與數(shù)據(jù)的革命,從此基準測試成為衡量AI模型性能的一個重要手段。
在NLP領(lǐng)域, 也有GLUE(通用語言理解評估)基準,AI模型需要在包含上千個句子的數(shù)據(jù)集上進行訓練,并在九個任務上進行測試,例如判斷一個句子是否符合語法,分析情感,或者兩個句子之間是否是邏輯蘊涵等。
GLUE剛發(fā)布時,性能最佳的模型得分還不到70分,基準創(chuàng)建人,紐約大學的計算機科學家Sam Bownman當時認為這個數(shù)據(jù)集很成功,至少難倒了AI模型。
而僅僅經(jīng)過一年的發(fā)展,AI模型的性能輕松達到90分,超越了人類的87.1分。

2019年,研究人員再次提高了基準測試的難度,發(fā)布SuperGLUE,一些任務要求AI模型不僅能夠處理句子,還要處理來自維基百科或新聞網(wǎng)站的段落后回答閱讀理解問題。
同樣,人類在基準剛發(fā)布時領(lǐng)先20分,到2021年初,計算機再次擊敗了人類的89.8分。
難道AI模型的智力水平已經(jīng)超越了人類?
在「刷榜」上,AI語言模型在經(jīng)過海量書籍、新聞文章和維基百科中數(shù)十億單詞的訓練后,一次次讓從業(yè)者興奮,可以生成令人驚艷的人類散文、推文、總結(jié)電子郵件,甚至在幾十種語言之間進行相互翻譯。
但在現(xiàn)實應用中部署或特定例子的測試時,又會讓人感嘆:AI怎么會犯如此愚蠢的錯誤?該怎么教會它改正?
2020年,微軟的計算機科學家Marco Túlio Ribeiro發(fā)布了一篇報告,指出了包括微軟、谷歌和亞馬遜在內(nèi)的各種sota模型內(nèi)的諸多隱含錯誤,比如把句子里的「what's」改成「what is」,模型的輸出就會截然不同,而在此前,從沒有人意識到這些商業(yè)模型竟會如此糟糕。
這樣訓出來的AI模型就像一個只會應試教育、成績優(yōu)異的學生,可以成功通過科學家設(shè)置的各種基準測試,卻不懂為什么,俗稱「高分低能」。
不過大多數(shù)研究人員認為,解決方案并不是放棄基準測試,而是改善。不過改善方法上,又有了分歧。
一些人認為基準測試應該更加嚴格,有人認為基準測試應該能闡明模型的偏見,還有人希望基準數(shù)據(jù)集的規(guī)模要更大一些,以便應對那些沒有單一標準答案的問題(如文本摘要),又或者利用多個評價指標來衡量模型的性能。
讓基準變得更難
一個最明顯的基準提升手段就是讓它們變得更難。
AI初創(chuàng)公司Hugging Face的研究帶頭人Douwe Kiela認為現(xiàn)有的基準測試最離譜的一點就是讓AI模型看起來已經(jīng)超越了人類,但每個NLP從業(yè)者都深知,想要達到人類水平的語言智能,還有很長的路要走。
所以Kiela開始著手創(chuàng)建一個動態(tài)數(shù)據(jù)收集和基準測試平臺Dynabench,主要針對GLUE等靜態(tài)基準存在的一些問題:性能超越人類的速度太快、很容易過擬合、具有不確定或不完善的評價指標等。
Dynabench依賴于眾包平臺,對于每個任務(如情緒分類),眾包工作人員需要提交他們認為人工智能模型會錯誤分類的短語或句子,成功欺騙到模型的樣例被加入到基準測試中。模型在這些數(shù)據(jù)上進行訓練,然后重復該過程,并且基準測試也在不斷發(fā)展,不會出現(xiàn)排行榜過時的情況。
Dynabench平臺本質(zhì)上是一個科學實驗:如果動態(tài)地收集數(shù)據(jù),讓人和模型處于循環(huán)中,而不是傳統(tǒng)的靜態(tài)方式,能讓AI模型的研究取得更快的進展嗎?
另一種改進基準的方法是縮小實驗室內(nèi)數(shù)據(jù)和現(xiàn)實場景之間的差距。現(xiàn)有的機器學習模型通常在同一個數(shù)據(jù)集中隨機選擇的示例上進行訓練和測試,而在現(xiàn)實中,數(shù)據(jù)可能會發(fā)生分布變化。
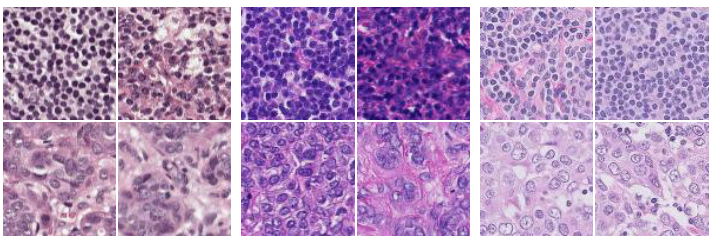
WILDS是斯坦福大學計算機科學家Percy Liang開發(fā)的基準測試,由10個精心挑選的數(shù)據(jù)集組成,可用于測試模型識別腫瘤、動物物種分類、補全計算機代碼等任務。
WILDS最關(guān)鍵的一步是每個數(shù)據(jù)集都來自多個源,例如腫瘤圖片來自五家不同的醫(yī)院,目的是考察模型在不同數(shù)據(jù)集之間的泛化能力。
WILDS 還可以測試模型的社會偏見,其中一個數(shù)據(jù)集是從新聞網(wǎng)站評論平臺收集的數(shù)十萬條有毒評論的集合,根據(jù)受辱的人口統(tǒng)計(黑人、白人、基督徒、穆斯林、LGBTQ 等)分為八個域。研究人員可以通過在整個數(shù)據(jù)集上訓練模型然后針對一部分數(shù)據(jù)進行測試來尋找盲點,例如,檢測能否識別針對穆斯林的有害評論。
打破「唯分數(shù)論」
更好的基準測試只是開發(fā)更優(yōu)模型的一種途徑,開發(fā)人員應當避免沉迷于排行榜的名次和分數(shù)。
埃因霍芬理工大學的計算機科學家Joaquin Vanschoren譴責論文中所謂的SOTA(state of the art) 正在扼殺創(chuàng)新,他呼吁AI會議中的審稿人不要再強調(diào)排行榜上的分數(shù),而主要關(guān)注創(chuàng)新點。
大部分基準測試上的分數(shù)只有一個,并不能完全反映模型之間的優(yōu)劣。
在Dynabench中,使用Dynascore對模型在基準測試中的性能進行評價,涵蓋了多種因素:準確性、速度、內(nèi)存使用、公平性和對輸入變化的魯棒性。用戶可以根據(jù)對他們最重要的因素來對模型進行排行,比如Facebook 的工程師可能比智能手表設(shè)計師更看重準確性,而后者可能更看重能源效率。
另一方面,基準數(shù)據(jù)集中問題通常沒有絕對的「ground truth」,所以分數(shù)的準確性也不一定可靠。一些基準設(shè)計者只是從測試數(shù)據(jù)中剔除模棱兩可或有爭議的例子,在數(shù)據(jù)集中也稱之為噪音。
去年,倫敦瑪麗女王大學的計算語言學家 Massimo Poesio 和他的同事創(chuàng)建了一個基準,用于評估模型從人類數(shù)據(jù)標注者之間的分歧中學習的能力。
他們將多個文本片段根據(jù)人類感覺的「好笑程度」進行排序,并以此來訓練模型,要求模型判斷兩個文本中哪段更好笑的概率,而不是簡單地提供「是或否」作為答案,每個模型都根據(jù)其估計與人類標注分布的匹配程度進行評分。
基準研究仍然小眾
目前基準相關(guān)的研究首要面臨的問題是缺乏激勵措施。
在去年發(fā)表的一篇論文中,谷歌的研究人員采訪了工業(yè)界和學術(shù)界的 53 位人工智能從業(yè)者。許多人指出,改進數(shù)據(jù)集不如設(shè)計模型更有成就感。論文的作者之一Lora Aroyo認為,機器學習社區(qū)正在改變對基準的態(tài)度,但目前仍然是一個小眾研究。
去年的NeurIPS會議上推出了一個新的track,用于審查和發(fā)表有關(guān)數(shù)據(jù)集和基準主題的論文,立即為研究這些主題創(chuàng)造了新的動力,畢竟中了就是頂會。
聯(lián)合主席 Vanschoren說,組織者預計會有幾十份提交,但最后收到了超過500篇論文,這也說明了這是眾望所歸。
一些論文提供了新的數(shù)據(jù)集或基準,而另一些則揭示了現(xiàn)有數(shù)據(jù)集或基準的問題,有研究人員發(fā)現(xiàn)在10個流行的視覺、語言和音頻基準中,測試數(shù)據(jù)中至少有 3% 的標簽不正確,這些錯誤會影響模型的排名。
盡管許多研究人員希望通過激勵措施創(chuàng)建更好的基準,但也有人不希望該領(lǐng)域過多地研究這些。
古德哈特定律(Goodhart's law)有言:一旦指標變成了目標,那它就不再是一個好指標了。

也就是說,當你嘗試用各種方法教模型怎么考試時,考試本身也就失去了意義。
最后,Ribeiro表示,基準應該是從業(yè)者工具箱中的一個工具,人們用基準來代替模型的理解,通過基準數(shù)據(jù)集來測試「模型的行為」。
參考資料:
https://www.science.org/content/article/computers-ace-iq-tests-still-make-dumb-mistakes-can-different-tests-help



















