Kafka 萬億級消息實踐之資源組流量掉零故障排查分析
作者 | vivo 互聯網服務器團隊-Luo Mingbo
一、Kafka 集群部署架構
為了讓讀者能與小編在后續的問題分析中有更好的共鳴,小編先與各位讀者朋友對齊一下我們 Kafka 集群的部署架構及服務接入 Kafka 集群的流程。
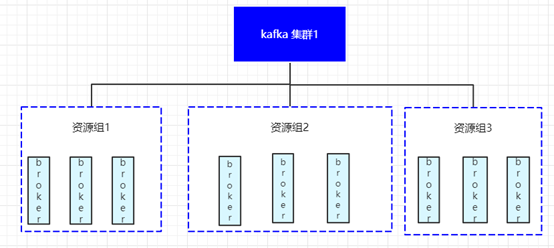
為了避免超大集群我們按照業務維度將整個每天負責十萬億級消息的 Kafka 集群拆分成了多個 Kafka 集群。拆分粒度太粗會導致單一集群過大,容易由于流量突變、資源隔離、限速等原因導致集群穩定性和可用性受到影響,拆分粒度太細又會因為集群太多不易維護,集群內資源較少應對突發情況的抗風險能力較弱。
由于 Kafka 數據存儲和服務在同一節點上導致集群擴縮容周期較長,遇到突發流量時不能快速實現集群擴容扛住業務壓力,因此我們按照業務維度和數據的重要程度及是否影響商業化等維度進行 Kafka 集群的拆分,同時在 Kafka 集群內添加一層邏輯概念“資源組”,資源組內的 Node 節點共享,資源組與資源組之間的節點資源相互隔離,確保故障發生時不會帶來雪崩效應。
二、業務接入 Kafka 集群流程
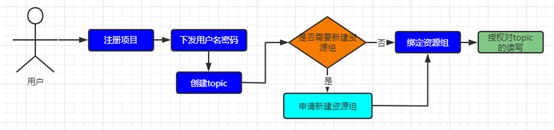
- .在 Kafka 平臺注冊業務項目。
- 若項目的業務數據較為重要或直接影響商業化,用戶需申請創建項目獨立的資源組,若項目數據量較小且對數據的完整性要求不那么高可以直接使用集群提供的公共資源組無需申請資源組。
- 項目與邏輯概念資源組綁定。
- 創建 topic,創建 topic 時使用 Kafka 平臺提供的接口進行創建,嚴格遵守 topic 的分區分布只能在項目綁定的資源組管理的 broker 節點上。
- 授權對 topic 的讀寫操作。
通過上述的架構部署介紹及接入流程接入介紹相信大家有很多相關知識點都與小編對齊了。
從部署架構圖我們可以清晰的了解到我們這套集群部署在服務端最小的資源隔離單元為“資源組”即在同一個資源組下的多個broker節點之間會有影響,不同的資源組下的broker節點做了邏輯隔離。
上述的相關知識點對齊后我們將開啟我們的故障排查之旅。
三、故障情況介紹
故障發生時,故障節點所在資源組的多個 topic 流量幾乎全部掉零,生產環境我們對 Kafka 集群的磁盤指標READ、WRITE、IO.UTIL、AVG.WAIT、READ.REQ、WRITE.REQ做了告警監控,由于故障發生在凌晨,整個故障的處理過程持續實踐較長,導致了業務方長時間的topic流量整體掉零對業務造成不小的影響。
四、監控指標介紹
4.1 流量監控情況
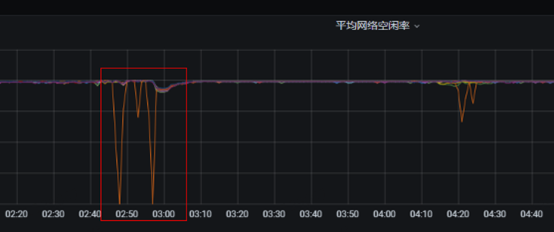
1、故障節點在故障發生時網絡空閑率出現短暫的掉零情況,且與生產流量監控指標一致。一旦生產流量上升故障節點的網絡空閑率就同步掉零。
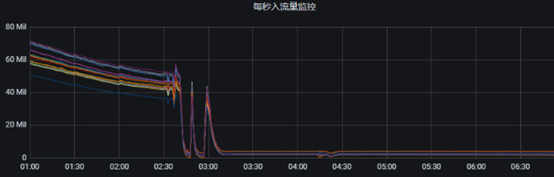
2、Grafana 監控指標中topic生產流量幾乎全部掉零。
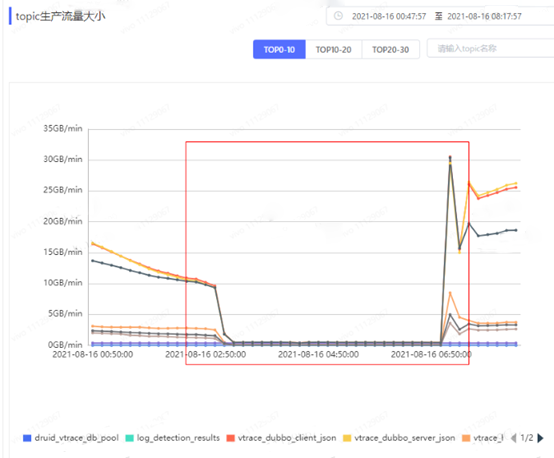
3、Kafka 平臺項目監控中也體現了當前項目的多個topic生產流量指標掉零。
4.2 磁盤指標監控
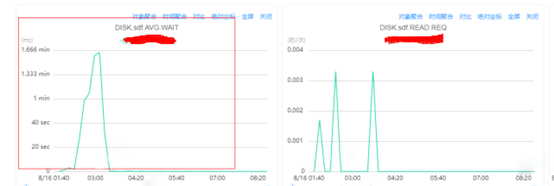
SDF 盤的IO.UTIL指標達到100%, 80%左右我們認為是服務可穩定運行的指標閾值。
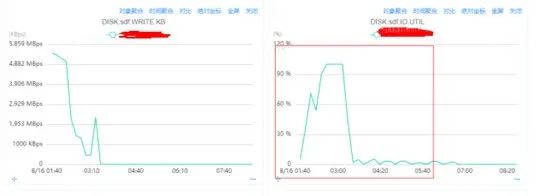
SDF 盤的AVG.WAIT指標達到分鐘級等待,一般400ms左右的延遲我們認為是服務可穩定運行的閾值。
4.3 Kafka 服務端日志及系統日志情況
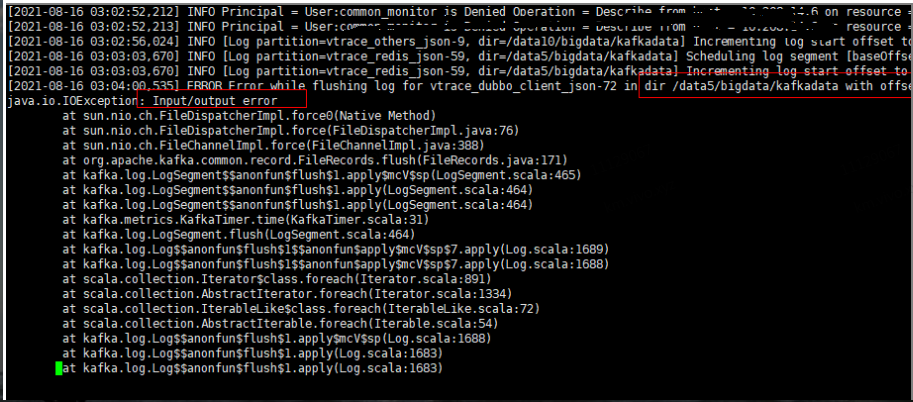
Kafka集群controller節點的日志中出現Input/Output error的錯誤日志。
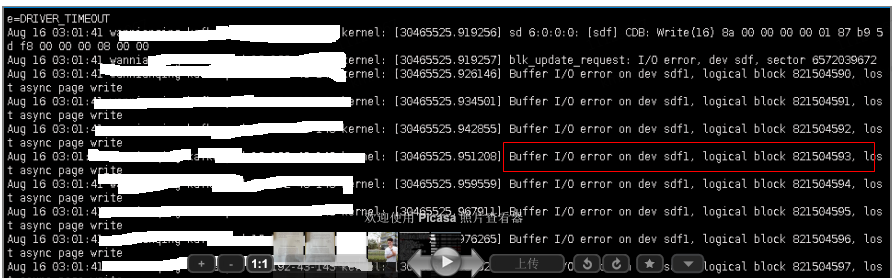
Linux 系統日志中出現Buffer I/O error 的錯誤日志
五、故障猜想及分析
從上述的指標監控中很明顯的可以得出結論,故障原因是由于 Kafka broker節點的sdf盤磁盤故障導致的,只需在對應的 Kafka broker 節點上將sdf盤踢掉重啟即可恢復。那這樣就結束了嗎 ?of course not。
對 Kafka 有一定認識的小伙伴應該都知道,創建topic時topic的分區是均勻分布到集群內的不同broker節點上的,即使內部某一臺broker節點故障,其他分區應該能正常進行生產消費,如果其他分區能進行正常的生產和消費就不應該出現整個topic的流量幾乎全掉零的情況。
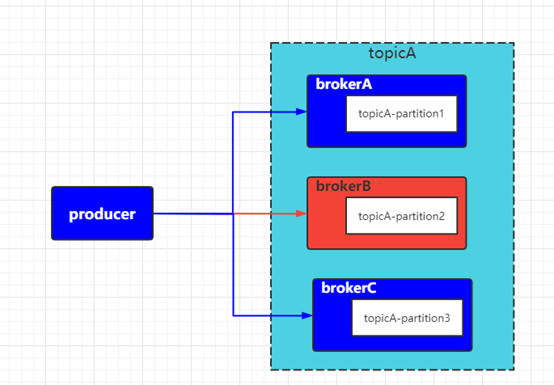
如上圖所示,topicA 的三個分區分別分布在 brokerA、brokerB、brokerC三個物理主機節點上。
生產者producer向TopicA發送消息時會分別與brokerA、brokerB、brokerC三個物理主機節點建立長鏈接進行消息的發送,此時若 brokerB 節點發生故障無法向外部提供服務時按照我們的猜想應該不會影響到brokerA和brokerC兩個節點繼續向producer提供接收消息的服務。
但從監控指標的數據展示來分析當brokerB節點出現故障后topic整體流量掉零與我們的猜想大相徑庭。
既然是出現類似了服務雪崩的效應導致了部分topic的整體流量幾乎掉零那么我們在猜想問題發生的原因時就可以往資源隔離的方向去思考,看看在整個過程中還有哪些地方涉及到資源隔離的環節進行猜想。
Kafka 服務端我們按照資源組的方式做了 Kafka broker的邏輯隔離且從Grafana監控上可以看出有一些topic的流量并沒有嚴重掉零的情況,那么我們暫時將分析問題的目光轉移到 Kafka client端,去分析 Kafka producer的發送消息的過程是否存在有資源隔離地方沒有做隔離導致了整體的雪崩效應。
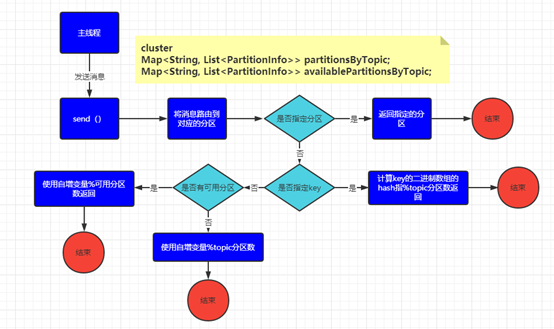
六、Kafka 默認分區器的分區規則
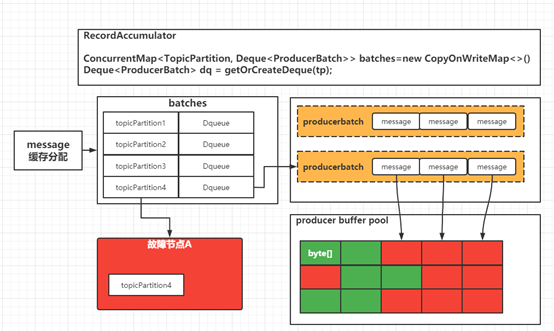
對 Kafka 生產流程流程有一定了解的同學肯定知道,Kafka 作為了大數據生態中海量數據的消息中間件,為了解決海量數據的并發問題 Kafka 在設計之初就采用了客戶端緩沖消息,當消息達到一定批量時再進行批量消息的發送。
通過一次網絡IO將批量的數據發送到 Kafka 服務端。關于Kafka producer客戶端緩沖區的設計小編后續會單獨一個篇幅進行深入的探索,鑒于篇幅問題不再此處進行詳細分析。
基于此處的分析我們對一批消息發送到一個故障節點時的容錯方案可以有以下猜想:
- 快速失敗,記錄故障節點信息。下次進行消息路由時只路由到健康的節點上。快速釋放消息緩沖內存。
- 快速失敗,記錄故障節點信息,下次進行消息路由時當消息路由到故障節點上時直接報錯,快速釋放緩沖區內存。
- 等待超時,當次消息等待超時后,下次進行消息路由時依然會出現路由到故障節點上的情況,且每次等待超時時間后才釋放占用的資源。
上述猜想中,如果是第一種情況,那么每次消息路由只路由到健康的節點上不會出現雪崩效應耗盡客戶端緩沖區資源的情況;
第二種情況,當消息路由到故障節點上時,直接拒絕分配緩沖區資源也不會造成雪崩效應;
第三種情況,每次需要在一個或多個超時時間后才能將故障節點所占用的客戶端緩沖區資源釋放,在海量消息發送的場景下一個超時時間周期內故障節點上的消息足以將客戶端緩沖區資源耗盡,導致其他可用分區無法分配客戶端緩沖區資源導致出現雪崩效應。
帶著上述的猜想打開kafka client producer的源代碼分析下defaultPartitioner的分區規則得到如下的分配邏輯:
發送消息時是否指定了分區,若指定了分區那消息就直接發往該分區無需重新路由分區。
消息是否指定了key,若消息指定了key,使用key的hash值與topic的分區數進行模運算,得出消息路由的分區號(對應第三種猜想)。
消息未指定分區也未指定key,使用自增變量與topic的可用分區進行模運算,得出消息路由的分區號(對應第一種猜想)。
七、總結
- 從源碼中分析出若發送消息的時候指定了key,并使用的是 Kafka producer默認的分區分配器請款下會出現 Kafka producer 客戶端緩沖區資源被耗盡而出現topic所有分區雪崩效應。
- 跟業務系統同學了解了他們的發送邏輯確實在消息發送指定了key并使用的是 Kafka producer的默認分區分配器。
- 問題得到論證。
八、建議
- 若非必要發送消息時不要指定key,否則可能會出現topic所有分區雪崩效應。
- 若確實需要發送消息指定key,建議不要使用Kafka producer默認的分區分配器,因為指定key的情況下使用 Kafka producer的默認分區分配器會出現雪崩效應。