













長文本生成更流暢,斯坦福引入時間控制方法,論文入選ICLR 2022
近年來,包括 GPT-2 在內的大型語言模型在文本生成方面非常成功,然而,大型語言模型會生成不連貫的長文本。一個原因是不能提前計劃或表征長段文本動態。因此,它們常常產生游離的內容,語篇結構差,關聯性低 ; 文本在生成時似乎沒有錨定目標。當自回歸模型生成更長的文本時,這些連貫性問題進一步惡化,因為模型很難推斷超出其預期的文本終點。這些問題表明,大型語言模型目前無法正確捕捉文檔從開始到結束的演變過程,而這對于完成面向目標的任務至關重要,例如故事、對話或菜譜生成。
但是,使用學習的局部動態去生成精準的 goal-conditioned trajectories 是很難的,尤其是長跨度的 trajectories。
在近期的一項研究中,斯坦福大學的研究者探索了一種替代方案,該替代方案明確假設了具有 goal-conditioned 生成的簡單、固定動態模型。這種新穎的方法提高了長文本生成的性能,人類評估者對其輸出的評分比基線方法高 28.6%。
研究者提出了時間控制(Time Control),作為學習已知 goal-conditioned 動態的潛在空間的方法。他們假設非目標導向生成的 meandering 文本在潛在空間內可以表征為布朗運動,這種運動使得相鄰句子的嵌入變得更為相似,相距較遠的句子相異。借助固定的開始和結束節點,目標導向的行為能夠合并進該模型。在這種情況下,布朗運動變為了布朗橋,由此產生的潛在軌跡遵循簡單的封閉式動態。

論文鏈接:https://arxiv.org/pdf/2203.11370.pdf
在時間控制中,研究者推導了一個新的對比目標,用于學習一個具有布朗橋動態的潛空間。然后,利用這個潛在空間來生成保持局部連貫性并提高全局連貫性的文本。為了完成文本生成,時間控制首先通過固定在起始點和終止點的布朗橋過程規劃一個潛在的軌跡。然后它有條件地使用這個潛在規劃生成句子。在本文中,研究者根據時間控制的潛在軌跡,通過微調 GPT2 來解碼潛在規劃、生成文本。來自時間控制的軌跡作為文檔中的抽象語義位置,指導生成精細調整的語言模型。
總體來說,這項研究的貢獻包括:
- 推導了時間控制語言模型,該語言模型用一種新的對比目標學習的布朗橋動態顯式地模擬潛在結構。
- 在一系列文本域中,與針對具體任務的方法相比,時間控制能夠生成更多或同樣連貫的任務文本,包括文本填充和強制生成長文本。
- 驗證了結論,潛在表征通過評估與人類實驗的語篇一致性來競爭性地捕捉文本動態。
- 同時調整了方法,以理解對比目標的重要性,強化了布朗橋動態,并明確建立潛在動態模型。
時間控制(TIME CONTROL)
時間控制背后的洞察是學習一個具有平滑時間動態的潛在空間,用于建模和生成連貫的文本。研究者將時間控制分為三個部分。第一部分討論通過對比學習訓練編碼器將句子映射到布朗橋的潛在空間。第二部分討論了訓練解碼器從這個潛在空間重構句子。第三部分討論了從時間控制生成文本。
使用布朗橋動態訓練編碼器
這里的編碼器是一個從原始輸入空間到潛在空間的非線性映射,f_θ: X → Z。該編碼器的目標是將高維順序數據映射到低維潛在隨機過程,在本文中是布朗橋過程。在 t = 0 的任意起點 z_0 和 t = T 的終點 z_T 之間的布朗橋過程的密度是:
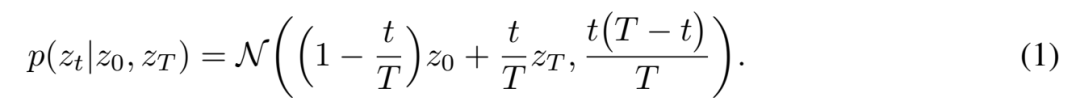
這種密度很容易理解: 它就像 trajectory 起點和終點之間的一個嘈雜的線性插值,起點的 z_T 應該更像 z_0,終點更像 z_T。不確定度在中間區域最高,在終點附近最低。
圖 1 展示了目標如何轉換為訓練編碼器的語言設置。客觀事實取材于文獻中的三句話。從同一文本中抽取的句子構成了一個平滑的潛在 trajectory,它們應該彼此接近,在潛在空間中遵循條件密度。從不同文本中抽取的句子不應該構成一個平穩的 trajectory,也不太可能遵循橋動態。

圖 1
使用潛在規劃訓練解碼器
這一部分討論了如何訓練一個語言模型來解碼潛在的生成計劃。首先使用預訓練的編碼器 f_θ 將訓練數據集中的所有句子映射到學習的潛在空間。這給出了數據集文檔的句子級潛在代碼 (z0,. . . ,zT,. . ,zT) 的布朗橋軌跡。然后,并不從零開始學習解碼器,而是根據過去上下文和潛在計劃微調 GPT2 生成文本。
在推理時間根據潛在規劃生成文本
圖 2 展示了經過訓練的解碼器如何在推理時生成文本。給定兩個端點 z_0,z_T,從一個潛在的布朗橋中抽取 trajectory 樣本,然后由這個橋上的解碼器生成。在許多情況下,我們可能并不清楚布朗橋的結束點。在這種情況下,可以編碼一組對應于開始點和結束點的句子(例如訓練集的第一個和最后一個句子),并對這些點擬合高斯形成一個密度估計。在這種情況下,生成涉及到首先從高斯采樣,然后像以前一樣從橋生成。有關訓練和生成的更多細節,可以參閱附錄 b。
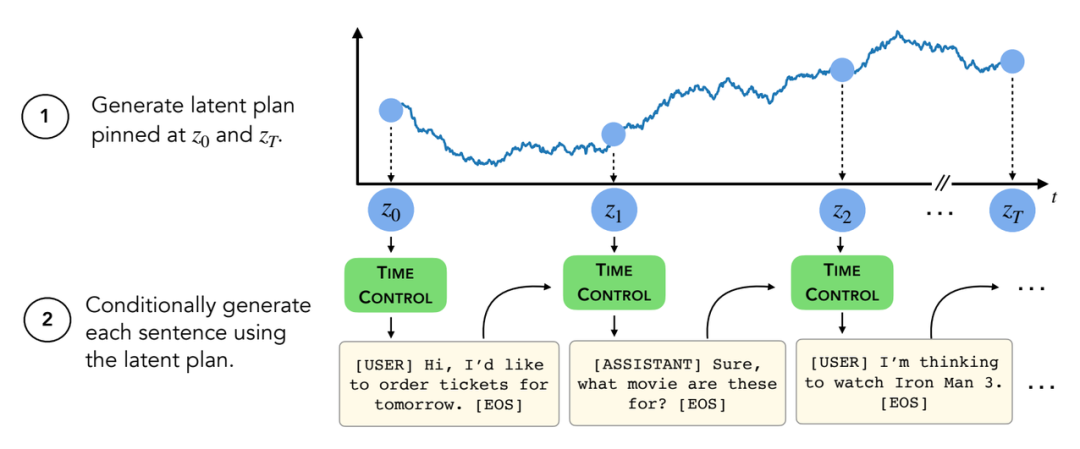
圖 2
實驗
在實驗部分,研究者評估了時間控制捕捉文本動態的能力。具體來說,可拆分為以下的研究問題:
1、時間控制能夠為局部文本動態建模嗎?第 4.1 節使用一個句子排序預測任務來研究這個問題: 給定來自同一文檔的兩個句子,評估不同的模型是否能夠預測它們的原始順序。
2、時間控制能生成局部連貫的文本嗎?第 4.2 節使用文本填充任務來研究這個問題: 給定前綴和后綴,評估不同模型之間填充的效果。
3、時間可以控制全局文本動態模型嗎?第 4.3 節通過檢查生成部分的長度來研究維基百科城市文章的文本生成問題。
4、時間控制可以生成長的連貫文檔嗎?第 4.4 節研究了強制長文本生成的這個問題: 評估模型在生成過程中被迫外推時如何保存全局文本統計數據(例如典型的部分順序和長度)。
研究者使用不同的潛在維度運行時間控制(d = 8,16,32)。編碼器架構是一個從 Huggingface 獲得的凍結的 GPT2 預訓練模型和可訓練的 MLP 網絡。研究者提取出與 EOS token 對應的最后一層隱藏狀態,并在隱藏狀態的頂部訓練 4 層 MLP。該 MLP 網絡具有中級的 ReLU 激活,并且受到隨機梯度下降的訓練,學習率為 1 e-4,動量為 0.9。
這里評價了時間控制在語篇連貫設置中對局部語篇動態的模擬效果(RQ1)。語篇連貫通常是通過測試線性分類器是否能夠檢測有序和無序句子對來衡量表征是否能夠捕獲語篇結構。這里比較了時間控制的編碼器與 GPT2 的最后一層的隱藏狀態對應的 EOS token(Radford et al., 2019), BERT (Devlin et al., 2019), ALBERT (Lan et al., 2019), Sentence BERT (Reimers et al., 2019), SimCSE (Gao et al., 2021)。后四種方法被設計為句子嵌入模型。如表 1 所示,也進行了消融研究。

表 1: 語篇連貫的準確率由訓練過的線性分類器的測試準確率來衡量。
RQ1 的答案是肯定的:時間控制可以對對話和文章中的局部文本動態進行建模。
然后,實驗了評估時間控制如何生成局部連貫文本 (RQ2) 的文本填充設置。文本填充需要一個模型,讓一個缺少句子的不完整文本變得完整。例如,「Patty 很高興她的朋友們能來。Patty 和她的朋友們玩得很開心。」這里文本填充的挑戰是生成一個與左右相鄰句子局部連貫的句子。
研究者在 BLEU (Papineni et al. ,2002) ,ROUGE (Lin,2004) ,BLEURT (Sellam et al. ,2020)和 BERTScore (Zhang et al. ,2019)上評估了生成句和 ground truth 填充句之間的語篇連貫性,如表 2 和表 17 所示。
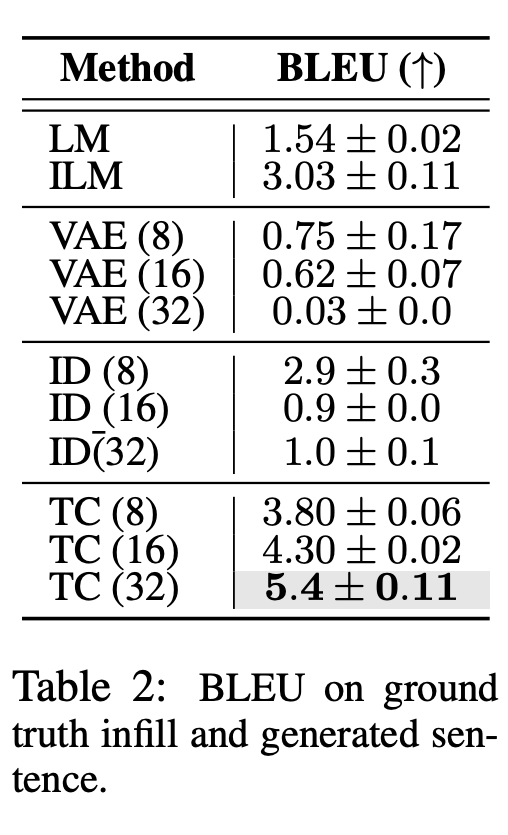
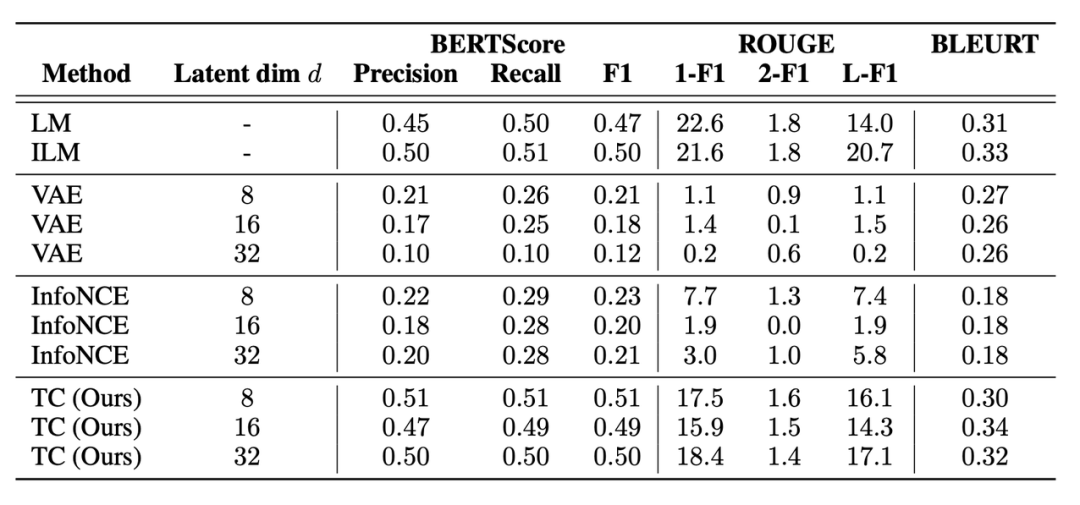
此外還包括人類作為補充句子的生成結果連貫程度的評估。參與者被要求對 ILM、LM 和 Time Control 生成的填充句子進行 1-5 的評分(從不合理到非常合理)。

RQ2 的答案是:由于明確了潛在動態,時間控制可以生成局部連貫的文本。
通過評估這些方法是否模擬了 Wikisection 上的文檔結構,研究者評估了時間控制對全局文本動態 (RQ3) 建模的效果。他們檢查了生成的區段長度是否與數據集中的平均長度匹配。Wikisection 的每份文檔都包含一個城市的摘要、歷史、地理和人口部分。
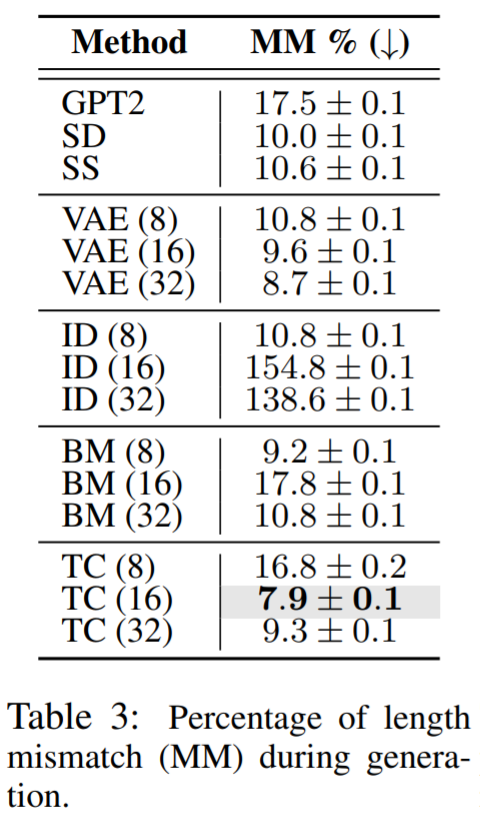
評估結果肯定了時間控制對于建模全局文本動態的重要性,例如匹配文檔結構,這回答了 RQ3。
在省略 EOS token 的情況下,研究者評估了時間控制生成全局連貫文本 (RQ4) 的效果,稱之為強制長文本生成設置,因為模型必須在生成時外推到其自然的終點以外。作為參考,1000 個 token 要比一般的 Wikisection 文檔(最長的文本域)長 50% 。在這項任務上,本文提出的方法也獲得了更好的表現。
總結來說,時間控制提高了文本填充和話語連貫性任務的性能,并在排序和文本長度一致性為長文本生成保留了文本結構,證明了本文提出的方法能夠生成更多局部和全局連貫的文本。團隊認為,時間控制還可以擴展到具有順序數據的其他領域,例如視頻或音頻,或者在沒有已知固定起點和終點的情況下處理任意橋接過程。
更多詳情可參考原論文。


























