介紹 Pandas 實戰中一些高端玩法

什么是多重/分層索引
多重/分層索引(MultiIndex)可以理解為堆疊的一種索引結構,它的存在為一些相當復雜的數據分析和操作打開了大門,尤其是在處理高緯度數據的時候就顯得十分地便利,我們首先來創建帶有多重索引的DataFrame數據集。
多重索引的創建
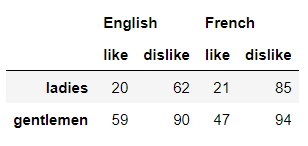
首先在“列”方向上創建多重索引,即我們在調用columns參數時傳遞兩個或者更多的數組,代碼如下:
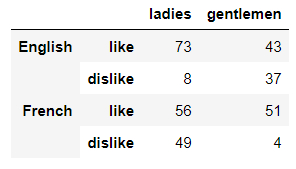
df1 = pd.DataFrame(np.random.randint(0, 100, size=(2, 4)),
index= ['ladies', 'gentlemen'],
columns=[['English', 'English', 'French', 'French'],
['like', 'dislike', 'like', 'dislike']])
output
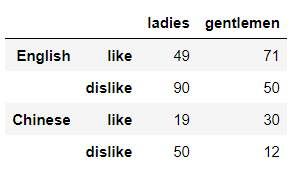
那么同理我們想要在“行”方向上存在多重索引,則是在調用index參數的時候傳遞兩個或者更多數組即可,代碼如下:
df = pd.DataFrame(np.random.randint(0, 100, size=(4, 2)),
index= [['English','', 'Chinese',''],
['like','dislike','like','dislike']],
columns=['ladies', 'gentlemen'])
output
除此之外,還有其他幾種常見的方式來創建多重索引,分別是:
- pd.MultiIndex.from_arrays
- pd.MultiIndex.from_frame
- pd.MultiIndex.from_tuples
- pd.MultiIndex.from_product
小編這里就挑其中的一種來為大家演示如何來創建多重索引,代碼如下:
df2 = pd.DataFrame(np.random.randint(0, 100, size=(4, 2)),
columns= ['ladies', 'gentlemen'],
index=pd.MultiIndex.from_product([['English','French'],
['like','dislike']]))
output
獲取多重索引的值
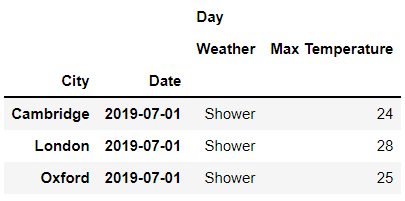
接下來我們來看一下怎么獲取帶有多重索引的數據集當中的數據,使用到的數據集是英國三大主要城市倫敦、劍橋和牛津在2019年全天的氣候數據,如下所示:
import pandas as pd
from pandas import IndexSlice as idx
df = pd.read_csv('dataset.csv',
index_col=[0,1],
header=[0,1]
)
df = df.sort_index()
df
output
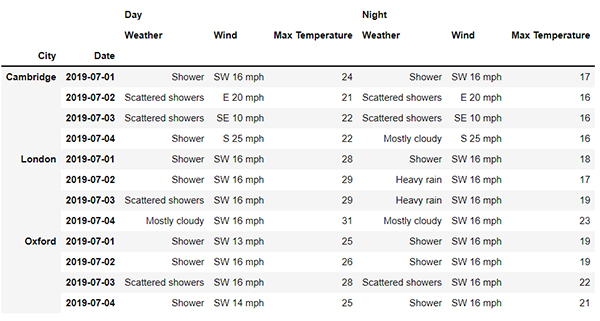
在“行”索引上,我們可以看到是“城市”以及“日期”這兩個維度,而在“列”索引上,我們看到的是則是“不同時間段”以及一些“氣溫”等指標,首先來看一下“列”方向多重索引的層級,代碼如下:
df.columns.levels
output
FrozenList([['Day', 'Night'], ['Max Temperature', 'Weather', 'Wind']])
我們想要獲取第一層級上面的索引值,代碼如下:
df.columns.get_level_values(0)
output
Index(['Day', 'Day', 'Day', 'Night', 'Night', 'Night'], dtype='object')
那么同理,第二層級的索引值,只是把當中的0替換成1即可,代碼如下:
df.columns.get_level_values(1)
output
Index(['Weather', 'Wind', 'Max Temperature', 'Weather', 'Wind',
'Max Temperature'],
dtype='object')
那么在“行”方向上多重索引值的獲取也是一樣的道理,這里就不多加以贅述了。
數據的獲取
那么涉及到數據的獲取,方式也有很多種,最常用的就是loc()方法以及iloc()方法了,例如:
df.loc['London' , 'Day']
## 或者是
df.loc[('London', ) , ('Day', )]
output
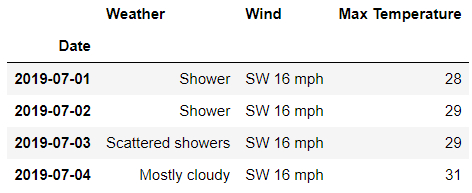
通過調用loc()方法來獲取第一層級上的數據,要是我們想要獲取所有“行”的數據,代碼如下:
df.loc[:, 'Day']
## 或者是
df.loc[:, ('Day',)]
output
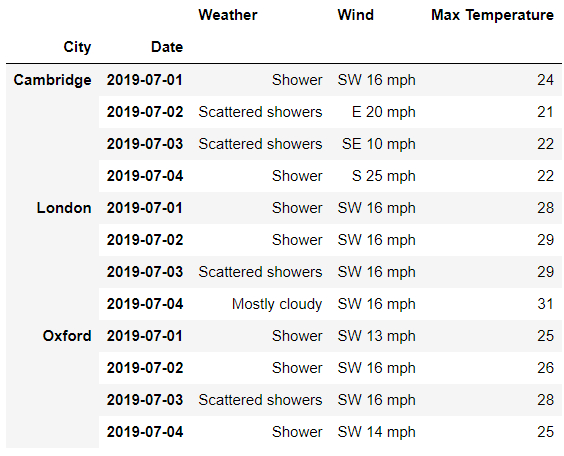
或者是所有“列”的數據,代碼如下:
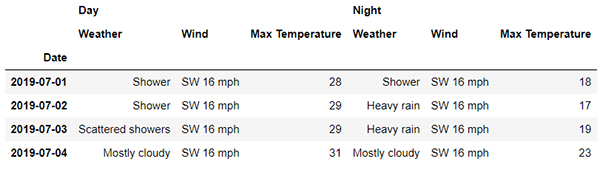
df.loc['London' , :]
## 或者是
df.loc[('London', ) , :]
output
當然我們也可以這么來做,在行方向上指定第二層級上的索引,代碼如下:
df.loc['London' , '2019-07-02']
## 或者是
df.loc[('London' , '2019-07-02')]
output

多重索引的數據獲取
假設我們想要獲取劍橋在2019年7月3日白天的數據,代碼如下:
df.loc['Cambridge', 'Day'].loc['2019-07-03']
output

在第一次調用loc['Cambridge', 'Day']的時候返回的是DataFrame數據集,然后再通過調用loc()方法來提取數據,當然這里還有更加快捷的方法,代碼如下:
df.loc[('Cambridge', '2019-07-01'), 'Day']
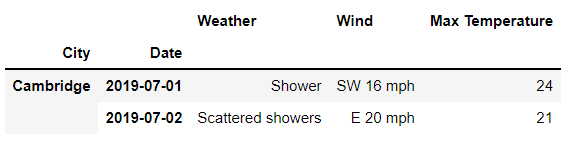
我們需要傳入元祖的形式的索引值來進行數據的提取。要是我們不只是想要獲取單行或者是單列的數據,可以這么來操作:
df.loc[
('Cambridge' , ['2019-07-01','2019-07-02'] ) ,
'Day'
]
output
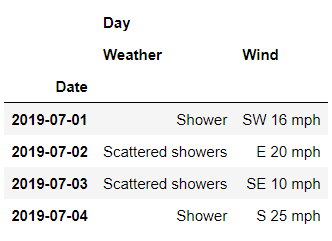
或者是獲取多列的數據,代碼如下:
df.loc[
'Cambridge' ,
('Day', ['Weather', 'Wind'])
]
output
我們要是想要獲取劍橋在2019年7月1日到3日,連續3天的白天氣候數據,代碼如下:
df.loc[
('Cambridge', '2019-07-01': '2019-07-03'),
'Day'
]
output

這么來寫是會報語法錯誤的,正確的方法應該是這么來做:
df.loc[
('Cambridge','2019-07-01'):('London','2019-07-03'),
'Day'
]
xs()方法的調用
小編另外推薦xs()方法來指定多重索引中的層級,例如我們只想要2019年7月1日各大城市的數據,代碼如下:
df.xs('2019-07-01', level='Date')
output
還能夠接受多個維度的索引,例如想要獲取倫敦在2019年7月4日的全天數據,代碼如下:
df.xs(('London', '2019-07-04'), level=['City','Date'])
output

另外還有axis參數來指定是獲取“列”方向還是“行”方向上的數據,例如我們想要獲取“Weather”這一列的數據,代碼如下:
df.xs('Weather', level=1, axis=1)
output
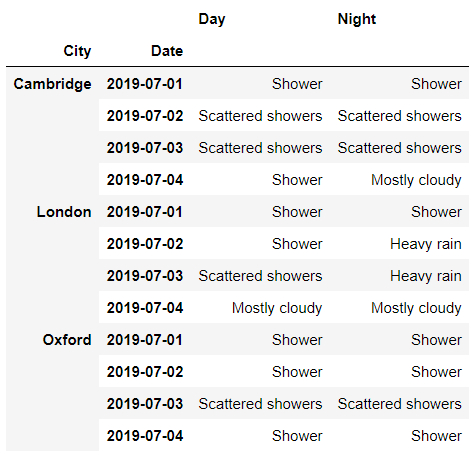
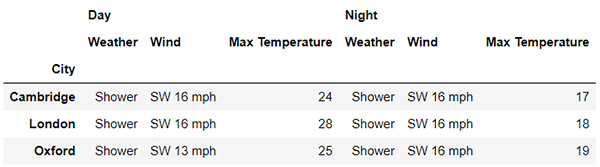
當中的level參數代表的是層級,我們將其替換成0,看一下出來的結果。
df.xs('Day', level=0, axis=1)
output
篩選出來的是三個主要城市2019年白天的氣候數據。
IndexSlice()方法的調用
同時Pandas內部也提供了IndexSlice()方法來方便我們更加快捷地提取出多重索引數據集中的數據,代碼如下:
from pandas import IndexSlice as idx
df.loc[
idx[: , '2019-07-04'],
'Day'
]
output

我們同時可以指定行以及列方向上的索引來進行數據的提取,代碼如下:
rows = idx[: , '2019-07-02']
cols = idx['Day' , ['Max Temperature','Weather']]
df.loc[rows, cols]
output