













多模態技術在淘寶主搜召回場景的探索
搜索召回作為搜索系統的基礎,決定了效果提升的上限。如何在現有的海量召回結果中,繼續帶來有差異化的增量價值,是我們面臨的主要挑戰。而多模態預訓練與召回的結合,為我們打開了新的視野,帶來線上效果的顯著提升。
前言
多模態預訓練是學術界與工業界研究的重點,通過在大規模數據上進行預訓練,得到不同模態之間的語義對應關系,在多種下游任務如視覺問答、視覺推理、圖文檢索上能夠提升效果。 在集團內部,多模態預訓練也有一些研究與應用。 在淘寶主搜場景中,用戶輸入的Query與待召回商品之間存在天然的跨模態檢索需求,只是以往對于商品更多地使用標題和統計特征,忽略了圖像這樣更加直觀的信息。 但對于某些有視覺元素的Query(如白色連衣裙、碎花連衣裙),相信大家在搜索結果頁都會先被圖像所吸引。
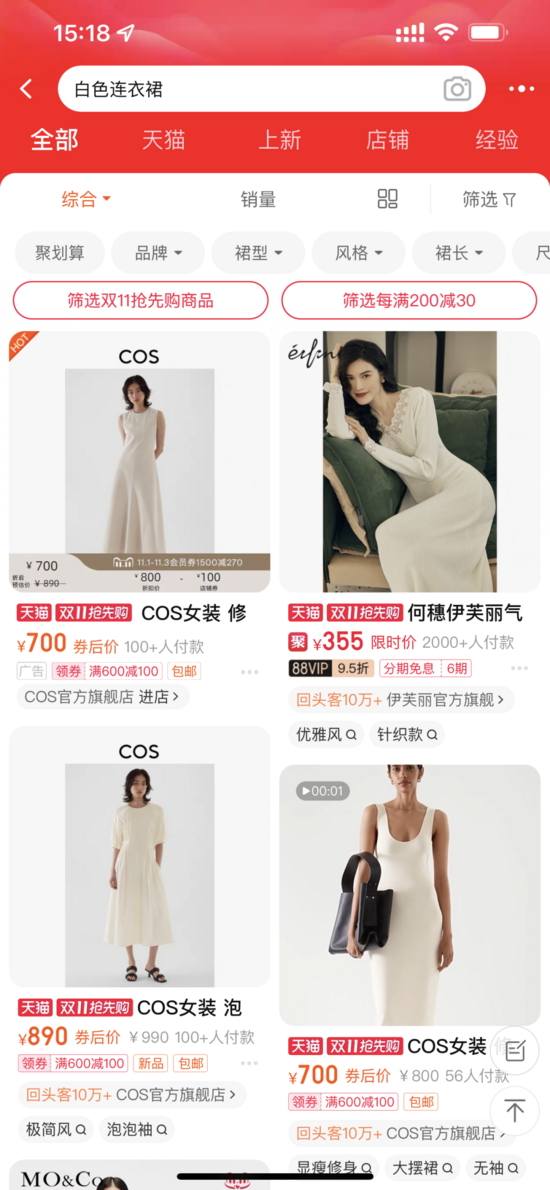

淘寶主搜場景
一方面是圖像占據著更顯著的位置,另一方面則是圖像可能包含著標題所沒有的信息,如白色、碎花這樣的視覺元素。對于后者,需要區分兩種情況:一種是標題中有信息、但由于顯示限制無法完全展示,這種情況不影響商品在系統鏈路里的召回;另一種是標題中沒有信息但圖像中有,也就是圖像相對于文本可以帶來增量。后者是我們需要重點關注的對象。
? 技術問題與解決思路
在主搜召回場景中應用多模態技術,有兩個主要問題需要解決:
- 多模態圖文預訓練模型一般融合圖像、文本兩種模態,主搜由于有Query的存在,在原本商品圖像、標題的圖文模態基礎上,需要考慮額外的文本模態。同時,Query與商品標題之間存在語義Gap,Query相對短且寬泛,而商品標題由于賣家會做SEO,往往長且關鍵詞堆砌。
- 通常預訓練任務與下游任務的關系是,預訓練采用大規模無標注數據,下游采用少量有標注數據。但對于主搜召回來說,下游向量召回任務的規模巨大,數據在數十億量級,而受限于有限的GPU資源,預訓練只能采用其中相對少量的數據。在這種情況下,預訓練是否還能對下游任務帶來增益。
我們的解決思路如下:
- 文本-圖文預訓練 :將Query和商品Item分別過Encoder,作為雙塔輸入到跨模態Encoder。如果從Query和Item雙塔來看,它們在后期才進行交互,類似于雙流模型,不過具體看Item塔,圖像和標題兩個模態在早期就進行了交互,這部分是單流模型。所以,我們的模型結構是區別于常見的單流或雙流結構的。這種設計的出發點是:更有效地提取Query向量和Item向量,為下游的雙塔向量召回模型提供輸入,并且能夠在預訓練階段引入雙塔內積的建模方式。為了建模Query與標題之間存在的語義聯系與Gap,我們將Query和Item雙塔的Encoder共享,再分別學習語言模型。
- 預訓練與召回任務聯動 :針對下游向量召回任務的樣本構造方式與Loss,設計了預訓練階段的任務及建模方式。區別于常見的圖文匹配任務,我們采用Query-Item和Query-Image匹配任務,并將Query下點擊最多的Item作為正樣本,將Batch內的其他樣本作為負樣本,增加采用Query和Item雙塔內積方式建模的多分類任務。這種設計的出發點是:使預訓練更靠近向量召回任務,在有限的資源下,盡可能為下游任務提供有效的輸入。另外,對向量召回任務來說,如果預訓練輸入的向量在訓練過程中是固定不變的,就無法有效地針對大規模數據做調整,為此,我們還在向量召回任務里建模了預訓練向量的更新。
預訓練模型
? 建模方法
多模態預訓練模型需要從圖像中提取特征,再與文本特征融合。從圖像中提取特征的方式主要有三種:使用CV領域訓練好的模型提取圖像的RoI特征、Grid特征和Patch特征。從模型結構來看,根據圖像特征和文本特征融合方式的不同,主要有兩類:單流模型或雙流模型。在單流模型中,圖像特征與文本特征在早期就拼接在一起輸入Encoder,而在雙流模型中,圖像特征和文本特征分別輸入到兩個獨立的Encoder,然后再輸入到跨模態Encoder中進行融合。
? 初步探索
我們提取圖像特征的方式是:將圖像劃分為Patch序列,使用ResNet提取每個Patch的圖像特征。在模型結構上,嘗試過單流結構,也就是將Query、標題、圖像拼接在一起輸入Encoder。經過多組實驗,我們發現在這種結構下,很難提取出純粹的Query向量和Item向量作為下游雙塔向量召回任務的輸入。如果提取某一向量時,Mask掉不需要的模態,會使得預測與訓練不一致。這個問題類似于,在一個交互型的模型里直接提取出雙塔模型,根據我們的經驗,這種模型的效果不如經過訓練的雙塔模型。基于此,我們提出了一種新的模型結構。
? 模型結構
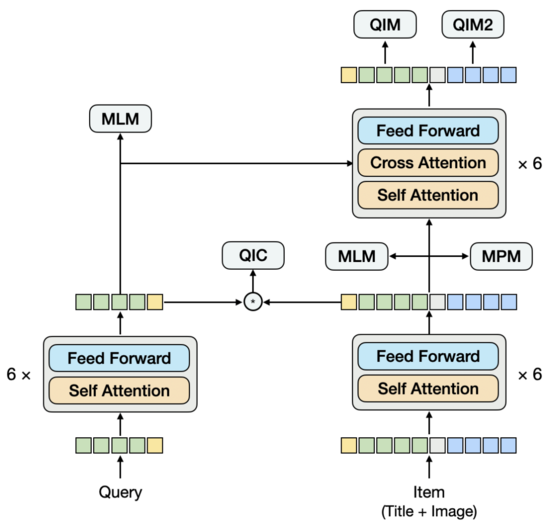
類似雙流結構,模型下方由雙塔構成,上方通過跨模態Encoder融合雙塔。與雙流結構不同的是,雙塔不是分別由單一模態構成,其中的Item塔中包含了Title和Image圖文雙模態,Title和Image拼接在一起輸入Encoder,這部分類似單流模型。為了建模Query與Title之間存在的語義聯系與Gap,我們將Query和Item雙塔的Encoder共享,再分別學習語言模型。
對于預訓練來說,設計合適的任務也是比較關鍵的。我們嘗試過常用的Title和Image的圖文匹配任務,雖然能達到比較高的匹配度,但對于下游向量召回任務帶來的增益很少,這是因為用Query去召回Item時,Item的Title和Image是否匹配不是關鍵因素。所以,我們在設計任務時,更多地考慮了Query與Item之間的關系。目前,一共采用5種預訓練任務。
? 預訓練任務
- Masked Language Modeling (MLM):在文本Token中,隨機Mask掉15%,用剩下的文本和圖像預測出被Mask的文本Token。對于Query和Title,有各自的MLM任務。MLM最小化交叉熵Loss:
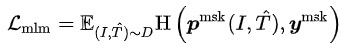 其中 表示剩下的文本token
其中 表示剩下的文本token - Masked Patch Modeling (MPM):在圖像的Patch Token中,隨機Mask掉25%,用剩下的圖像和文本預測出被Mask的圖像Token。MPM最小化KL散度Loss:
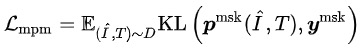 其中 表示剩下的圖像token
其中 表示剩下的圖像token - Query Item Classification (QIC): 一個Query下點擊最多的Item作為正樣本,Batch內其他樣本作為負樣本。QIC將Query塔和Item塔的[CLS] token通過線性層降維到256維,再做相似度計算得到預測概率,最小化交叉熵Loss:
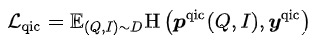 其中
其中 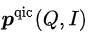 的計算可以采取多種方式:
的計算可以采取多種方式:
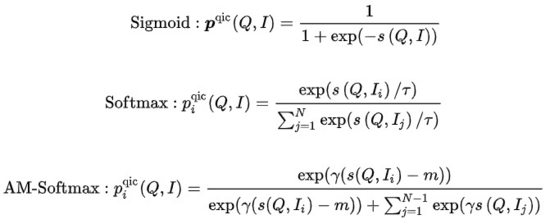
其中 表示相似度計算, 表示溫度超參數, 和m分別表示縮放因子和松弛因子
- Query Item Matching (QIM):一個Query下點擊最多的Item作為正樣本,Batch內與當前Query相似度最高的其他Item作為負樣本。QIM使用跨模態Encoder的[CLS] token計算預測概率,最小化交叉熵Loss:
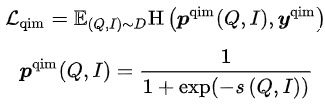
- Query Image Matching (QIM2):在QIM的樣本中,Mask掉Title,強化Query與Image之間的匹配。QIM2最小化交叉熵Loss:
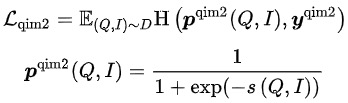
模型的訓練目標為,最小化整體Loss:
在這5種預訓練任務中,MLM任務和MPM任務位于Item塔的上方,建模Title或Image的部分Token被Mask后,使用跨模態信息相互恢復的能力。Query塔上方有獨立的MLM任務,通過共享Query塔和Item塔的Encoder,建模Query與Title之間的語義聯系與Gap。QIC任務使用雙塔內積的方式,將預訓練和下游向量召回任務做一定程度的對齊,并用AM-Softmax拉近Query的表示與Query下點擊最多Item的表示之間的距離,推開Query與其他Item的距離。QIM任務位于跨模態Encoder的上方,使用跨模態信息建模Query和Item的匹配。出于計算量的考慮,采用通常NSP任務的正負樣本比1:1,為了進一步推開正負樣本之間的距離,基于QIC任務的相似度計算結果構造了難負樣本。QIM2任務與QIM任務位于同樣的位置,顯式建模圖像相對于文本帶來的增量信息。
向量召回模型
? 建模方法
在大規模信息檢索系統中,召回模型位于最底層,需要在海量的候選集中打分。出于性能的考慮,往往采用User和Item雙塔計算向量內積的結構。向量召回模型的一個核心問題是:如何構造正負樣本以及負樣本采樣的規模。我們的解決方法是:將用戶在一個頁面內的點擊Item作為正樣本,在全量商品池中根據點擊分布采樣出萬級別的負樣本,用Sampled Softmax Loss在采樣樣本中推導出Item在全量商品池中的點擊概率。
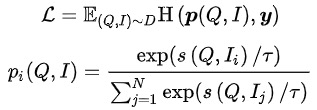
其中 表示相似度計算, 表示溫度超參數
? 初步探索
遵循常見的FineTune范式,我們嘗試過將預訓練的向量直接輸入到雙塔MLP,結合大規模負采樣和Sampled Softmax來訓練多模態向量召回模型。不過,與通常的小規模下游任務相反,向量召回任務的訓練樣本量巨大,在數十億量級。我們觀察到MLP的參數量無法支撐模型的訓練,很快就會達到自身的收斂狀態,但效果并不好。同時,預訓練向量在向量召回模型中作為輸入而不是參數,無法隨著訓練的進行得到更新。這樣一來,在相對小規模數據上進行的預訓練,與大規模數據上的下游任務有一定的沖突。
解決的思路有幾種,一種方法是將預訓練模型融合到向量召回模型中,但預訓練模型的參數量過大,再加上向量召回模型的樣本量,無法在有限的資源約束下,以合理的時間進行常態化訓練。另一種方法是在向量召回模型中構造參數矩陣,將預訓練向量載入到矩陣中,隨著訓練的進行更新矩陣的參數。經過調研,這種方式在工程實現上成本比較高。基于此,我們提出了簡單可行地建模預訓練向量更新的模型結構。
? 模型結構
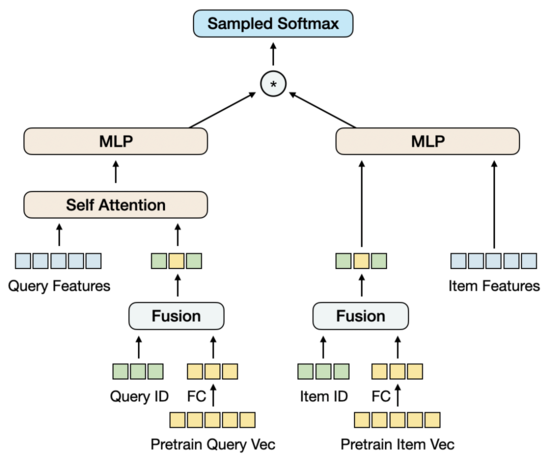
我們先將預訓練向量通過FC降維,之所以在這里而不是在預訓練中降維,是因為目前的高維向量對于負樣本采樣來說還在可接受的性能范圍內,這種情況下,在向量召回任務中降維是與訓練目標更一致的。同時,我們引入Query和Item的ID Embedding矩陣,Embedding維度與降維后的預訓練向量的維度保持一致,再將ID與預訓練向量融合在一起。這個設計的出發點是:引入足以支撐大規模訓練數據的參數量,同時使預訓練向量隨著訓練的進行得到適應性地更新。
在只用ID和預訓練向量融合的情況下,模型的效果不僅超過了只用預訓練向量的雙塔MLP的效果,也超過了包含更多特征的Baseline模型MGDSPR。更進一步,在這個基礎上引入更多的特征,可以繼續提升效果。
實驗分析
? 評測指標
對于預訓練模型的效果,通常是用下游任務的指標來評測,而很少用單獨的評測指標。但這樣一來,預訓練模型的迭代成本會比較高,因為每迭代一個版本的模型都需要訓練對應的向量召回任務,再評測向量召回任務的指標,整個流程會很長。有沒有單獨評測預訓練模型的有效指標?我們首先嘗試了一些論文中的Rank@K,這個指標主要是用來評測圖文匹配任務:先用預訓練模型在人工構造的候選集中打分,再計算根據分數排序后的Top K結果命中圖文匹配正樣本的比例。我們直接將Rank@K套用在Query-item匹配任務上,發現結果不符合預期,一個Rank@K更好的預訓練模型,在下游的向量召回模型中可能會獲得更差的效果,無法指導預訓練模型的迭代。基于此,我們將預訓練模型的評測與向量召回模型的評測統一起來,采用相同的評測指標及流程,可以相對有效地指導預訓練模型的迭代。
Recall@K :評測數據集由訓練集的下一天數據構成,先將同一個Query下不同用戶的點擊、成交結果聚合成 ,再計算模型預測的Top K結果 命中 的比例:
,再計算模型預測的Top K結果 命中 的比例:
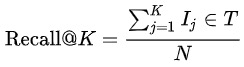
在模型預測Top K結果的過程中,需要從預訓練/向量召回模型中提取Query和Item向量,使用近鄰檢索得到一個Query下的Top K個Item。通過這個流程模擬線上引擎中的向量召回,來保持離線與在線的一致性。對于預訓練模型來說,這個指標與Rank@K的區別是:在模型中提取Query和Item向量進行向量內積檢索,而不是直接用模態融合后的模型來打分;另外,一個Query下不僅要召回與之匹配的Item,還要召回這個Query下不同用戶的點擊、成交Item。
對于向量召回模型,在Recall@K提高到一定程度后,也需要關注Query和Item之間的相關性。一個相關性差的模型,即使能提高搜索效率,也會面臨Bad Case增加導致的用戶體驗變差和投訴輿情增多。 我們采用與線上相關性模型一致的離線模型,評測Query和Item之間以及Query和Item類目之間的相關性。
? 預訓練實驗
我們選取部分類目下1億量級的商品池,構造了預訓練數據集。
我們的Baseline模型是經過優化的FashionBert,加入了QIM和QIM2任務,提取Query和Item向量時采用只對非Padding Token做Mean Pooling的方式。以下實驗探索了以雙塔方式建模,相對于單塔帶來的增益,并通過消融實驗給出關鍵部分的作用。

從這些實驗中,我們能得出如下結論:
- 實驗8 vs 實驗3:經過調優后的雙塔模型,在Recall@1000上顯著高于單塔Baseline。
- 實驗3 vs 實驗1/2:對單塔模型來說,如何提取Query和Item向量是重要的。我們嘗試過Query和Item都用[CLS] token,得到比較差的結果。實驗1對Query和Item分別用對應的Token做Mean Pooling,效果要好一些,但進一步去掉Padding Token再做Mean Pooling,會帶來更大的提升。實驗2驗證了顯式建模Query-Image匹配來突出圖像信息的作用,會帶來提升。
- 實驗6 vs 實驗4/5:實驗4將Item塔的MLM/MPM任務上移到跨模態Encoder,效果會差一些,因為將這兩個任務放在Item塔能夠增強Item表示的學習;另外,在Item塔做基于Title和Image的跨模態恢復會有更強的對應關系。實驗5驗證了對Query和Item向量在訓練和預測時增加L2 Norm,會帶來提升。
- 實驗6/7/8:改變QIC任務的Loss會帶來提升,Softmax相比于Sigmoid更接近下游的向量召回任務,AM-Softmax則更進一步推開了正樣本與負樣本之間的距離。
? 向量召回實驗
我們選取10億量級有點擊的頁面,構造了向量召回數據集。在每個頁面中包含3個點擊Item作為正樣本,從商品池中根據點擊分布采樣出1萬量級的負樣本。在此基礎上,進一步擴大訓練數據量或負樣本采樣量,沒有觀察到效果的明顯提升。
我們的Baseline模型是主搜的MGDSPR模型。以下實驗探索了將多模態預訓練與向量召回結合,相對于Baseline帶來的增益,并通過消融實驗給出關鍵部分的作用。
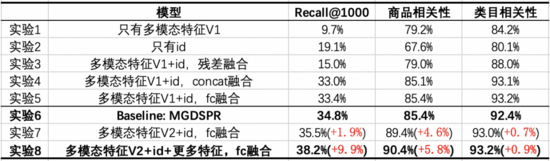
從這些實驗中,我們能得出如下結論:
- 實驗7/8 vs 實驗6:多模態特征與ID通過FC融合后,在3個指標上都超過了Baseline,在提升Recall@1000的同時,對商品相關性提升更多。在此基礎上,加入與Baseline相同的特征,能進一步提升3個指標,并在Recall@1000上提升得更多。
- 實驗1 vs 實驗2:只有多模態特征相比于只有ID,Recall@1000更低,但相關性更高,且相關性接近線上可用的程度。說明這時的多模態召回模型,從召回結果來看有更少的Bad Case,但對點擊、成交的效率考慮得不夠。
- 實驗3/4/5 vs 實驗1/2:將多模態特征與ID融合后,能夠在3個指標上都帶來提升,其中將ID過FC再與降維后的多模態特征相加,效果更好。不過,與Baseline相比,在Recall@1000上仍有差距。
- 實驗7 vs 實驗5:疊加預訓練模型的優化后,在Recall@1000、商品相關性上都有提升,類目相關性基本持平。
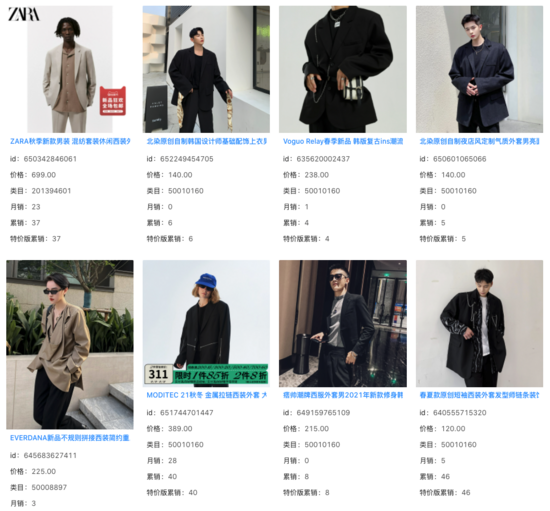
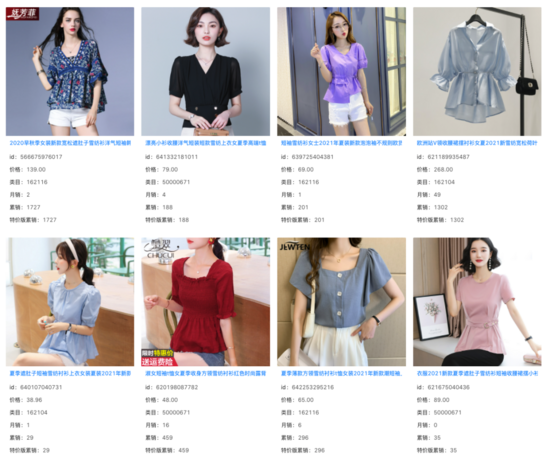
我們在向量召回模型的Top 1000結果中,過濾掉線上系統已經能召回的Item,發現其余增量結果的相關性基本不變。在大量Query下,我們看到這些增量結果捕捉 到了商品Title之外的圖像信息,并對Query和Title之間存在的語義Gap起到了一定的作用。
query: 痞帥西裝
query: 女掐收腰小衫
總結和展望
針對主搜場景的應用需求,我們提出了文本-圖文預訓練模型,采用了Query和Item雙塔輸入跨模態Encoder的結構,其中Item塔是包含圖文多模態的單流模型。通過Query-Item和Query-Image匹配任務,以及Query和Item雙塔內積方式建模的Query-Item多分類任務,使預訓練更接近下游的向量召回任務。同時,在向量召回中建模了預訓練向量的更新。在資源有限的情況下,使用相對少量數據的預訓練,對使用海量數據的下游任務仍然帶來了效果的提升。
在主搜的其他場景中,如商品理解、相關性、排序,也存在應用多模態技術的需求。我們也參與到了這些場景的探索中,相信多模態技術在未來會給越來越多的場景帶來增益。
團隊介紹
淘寶主搜召回團隊:團隊負責主搜鏈路中的召回、粗排環節,目前的主要技術方向為基于全空間樣本的多目標個性化向量召回、基于大規模預訓練的多模態召回、基于對比學習的相似Query語義改寫以及粗排模型等。

























