提升支付寶搜索體驗,螞蟻、北大基于層次化對比學習文本生成框架
文本生成任務通常采用 teacher forcing 的方式進行訓練,這種訓練方式使得模型在訓練過程中只能見到正樣本。然而生成目標與輸入之間通常會存在某些約束,這些約束通常由句子中的關鍵元素體現,例如在 query 改寫任務中,“麥當勞點餐” 不能改成 “肯德基點餐”,這里面起到約束作用的關鍵元素是品牌關鍵詞。通過引入對比學習給生成的過程中加入負樣本的模式使得模型能夠有效地學習到這些約束。
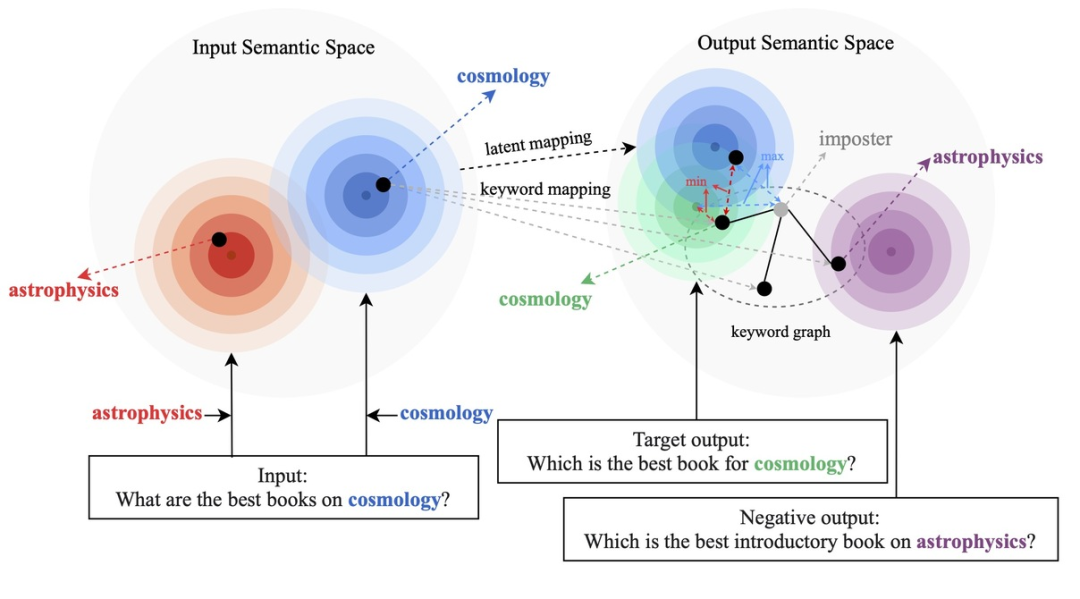
現有的基于對比學習方法主要集中在整句層面實現 [1][2],而忽略了句子中的詞粒度的實體的信息,下圖中的例子展示了句子中關鍵詞的重要意義,對于一個輸入的句子,如果對它的關鍵詞進行替換(e.g. cosmology->astrophysics),句子的含義會發生變化,從而在語義空間中的位置(由分布來表示)也會變化。而關鍵詞作為句子中最重要的信息,對應于語義分布上的一個點,它很大程度上也決定了句子分布的位置。同時,在某些情況下,現有的對比學習目標對模型來說顯得過于容易,導致模型無法真正學習到區分正負例之間的關鍵信息。
基于此,來自螞蟻集團、北大等機構的研究者提出了一種多粒度對比生成方法,設計了層次化對比結構,在不同層級上進行信息增強,在句子粒度上增強學習整體的語義,在詞粒度上增強局部重要信息。研究論文已被 ACL 2022 接收。

論文地址:https://aclanthology.org/2022.acl-long.304.pdf
方法
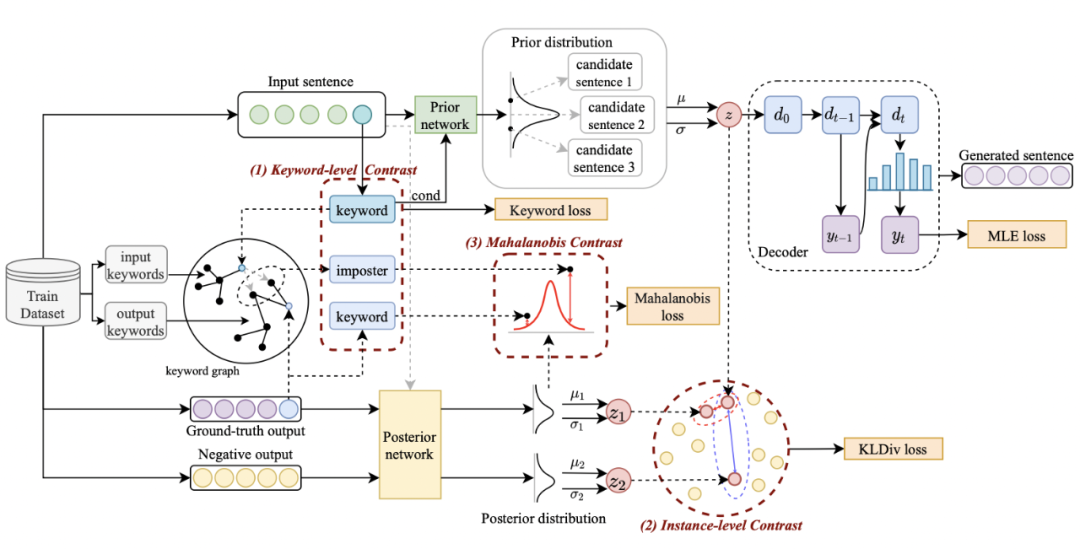
我們的方法基于經典的 CVAE 文本生成框架 [3][4],每個句子都可以映射成為向量空間中的一個分布,而句子中的關鍵詞則可以看成是這個分布上采樣得到的一個點。我們一方面通過句子粒度的對比來增強隱空間向量分布的表達,另一方面通過構造的全局關鍵詞 graph 來增強關鍵詞點粒度的表達,最后通過馬氏距離對關鍵詞的點和句子的分布構造層次間的對比來增強兩個粒度的信息表達。最終的損失函數由三種不同的對比學習 loss 相加而得到。
句子粒度對比學習
在 Instance-level,我們利用原始輸入 x、目標輸出
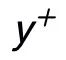
及對應的輸出負樣本構成了句子粒度的對比 pair
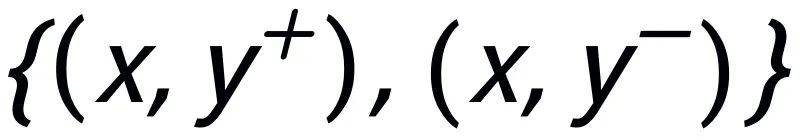
。我們利用一個先驗網絡學習到先驗分布
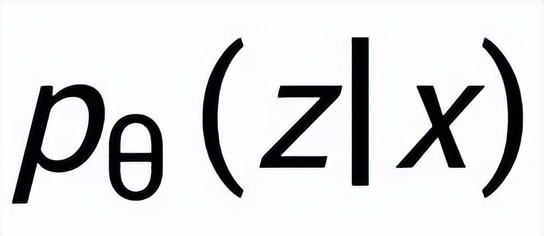
,記為
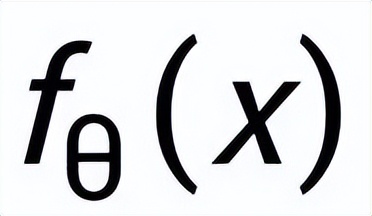
;通過一個后驗網絡學習到近似的后驗分布
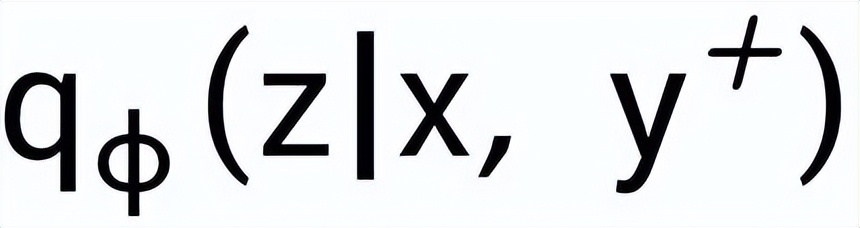
和
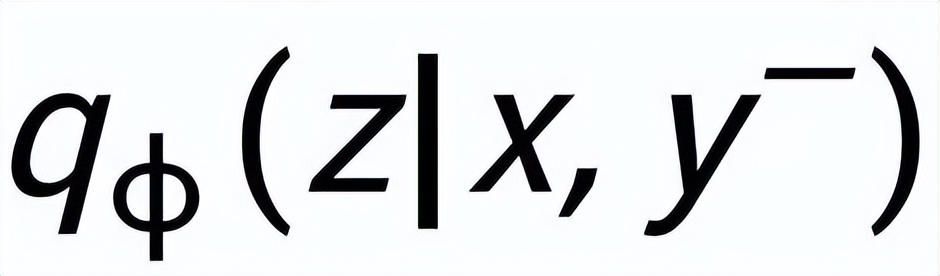
,分別記為
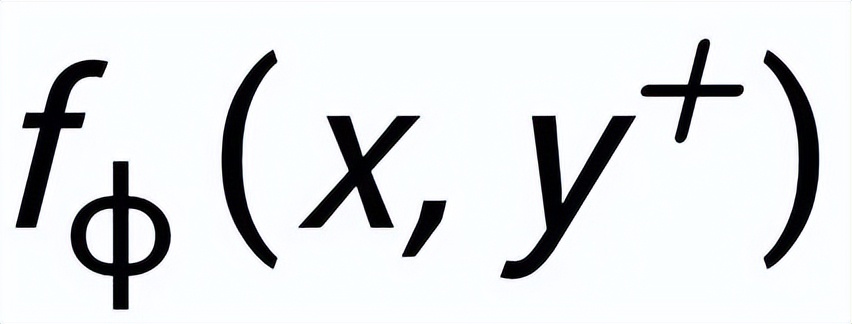
和
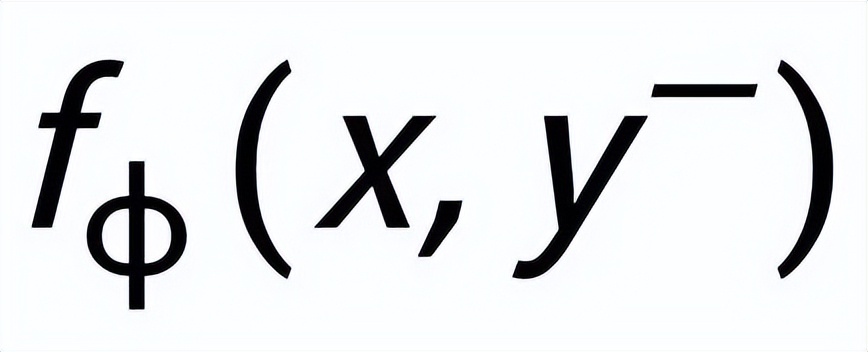
。句子粒度對比學習的目標就是盡可能的縮小先驗分布和正后驗分布的距離,同時盡可能的推大先驗分布和負后驗分布的距離,相應的損失函數如下:
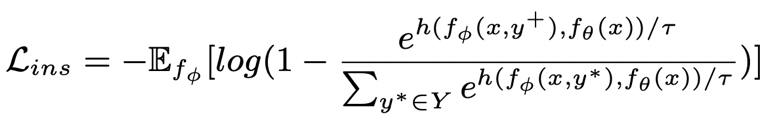
其中為正樣本或負樣本,為溫度系數,用來表示距離度量,這里我們使用 KL 散度(Kullback–Leibler divergence )[5] 來度量兩個分布直接的距離。
關鍵詞粒度對比學習
- 關鍵詞網絡
關鍵詞粒度的對比學習是用來讓模型更多的關注到句子中的關鍵信息,我們通過利用輸入輸出文本對應的正負關系構建一個 keyword graph 來達到這個目標。具體來說,根據一個給定的句對
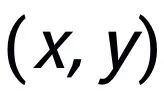
,我們可以分別從其中確定一個關鍵詞
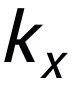
和
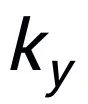
(關鍵詞抽取的方法我采用經典的 TextRank 算法 [6]);對于一個句子
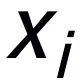
,可能存在與其關鍵詞
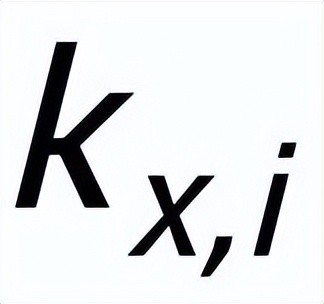
相同的其他句子,這些句子共同組成一個集合
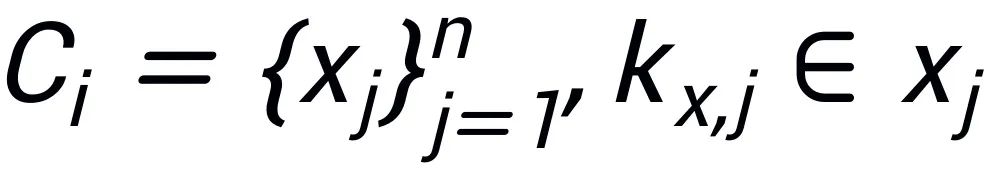
,這里面每一個句子

都有一對正負例輸出句子
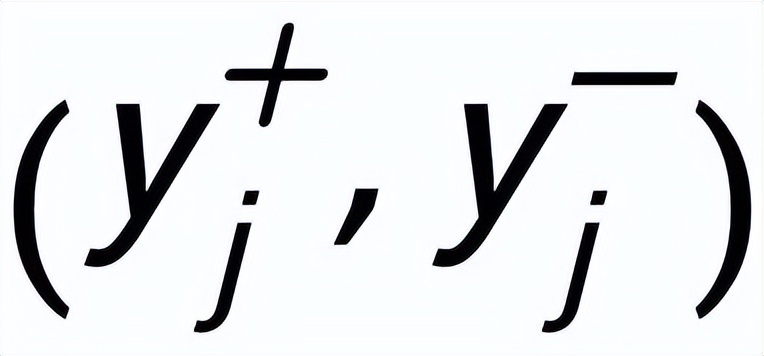
,他們分別又有一個正例關鍵詞

和負例關鍵詞

。這樣在整個集合中,對任何一個輸出的句子

,可以認為它所對應的關鍵詞
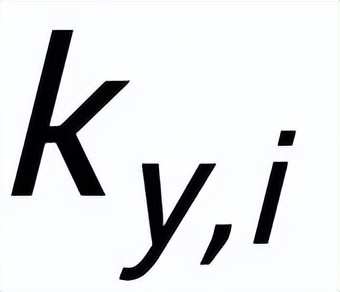
和每一個周圍的
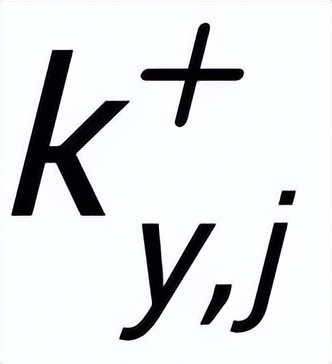
(通過句子之間的正負關系關聯)之間都存在一條正邊

,和每一個周圍的

之間都存在一條負邊

。基于這些關鍵詞節點和他們直接的邊,我們就可以構建一個 keyword graph

我們使用 BERT embedding[7] 來作為每個節點
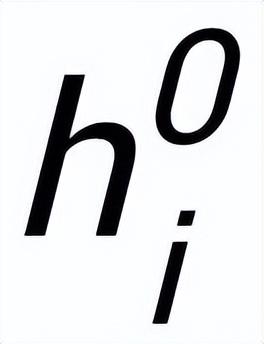
的初始化,并使用一個 MLP 層來學習每條邊的表示
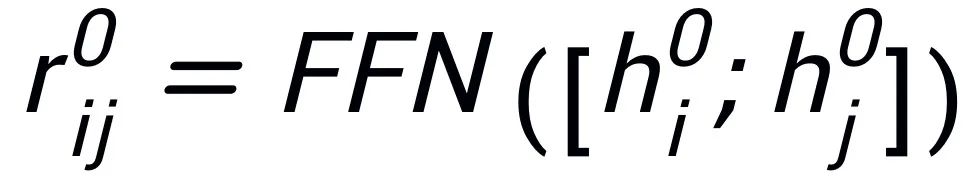
。我們通過一個 graph attention (GAT) 層和 MLP 層來迭代式地更新關鍵詞網絡中的節點和邊,每個迭代中我們先通過如下的方式更新邊的表示:
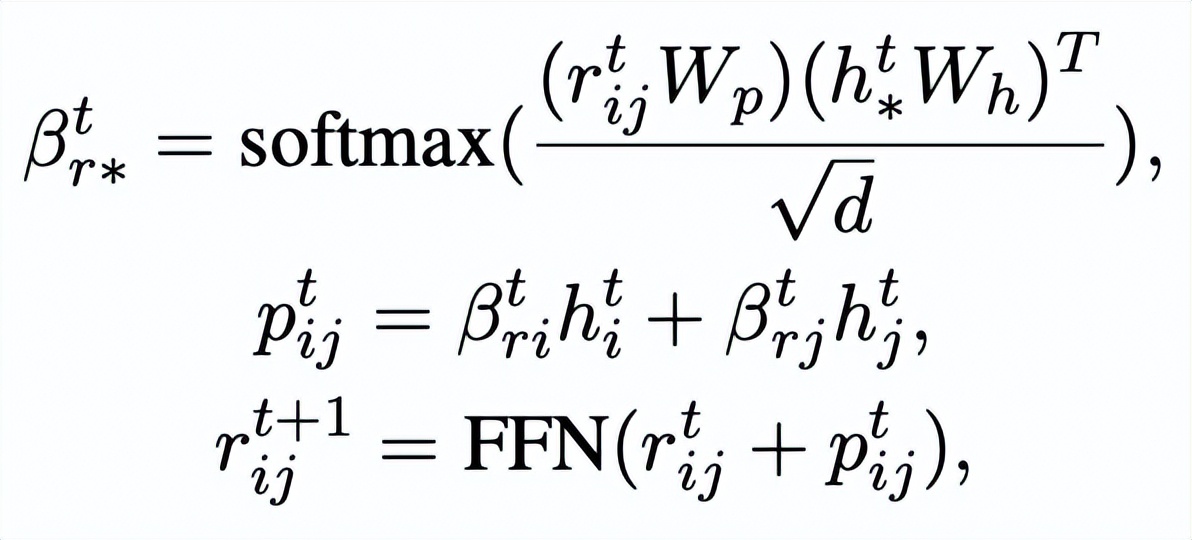
這里
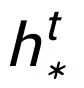
可以是
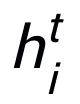
或者
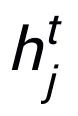
。
然后根據更新后的邊
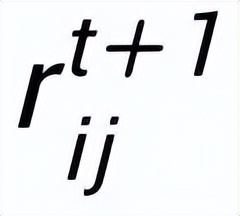
,我們通過一個 graph attention 層來更新每個節點的表示:
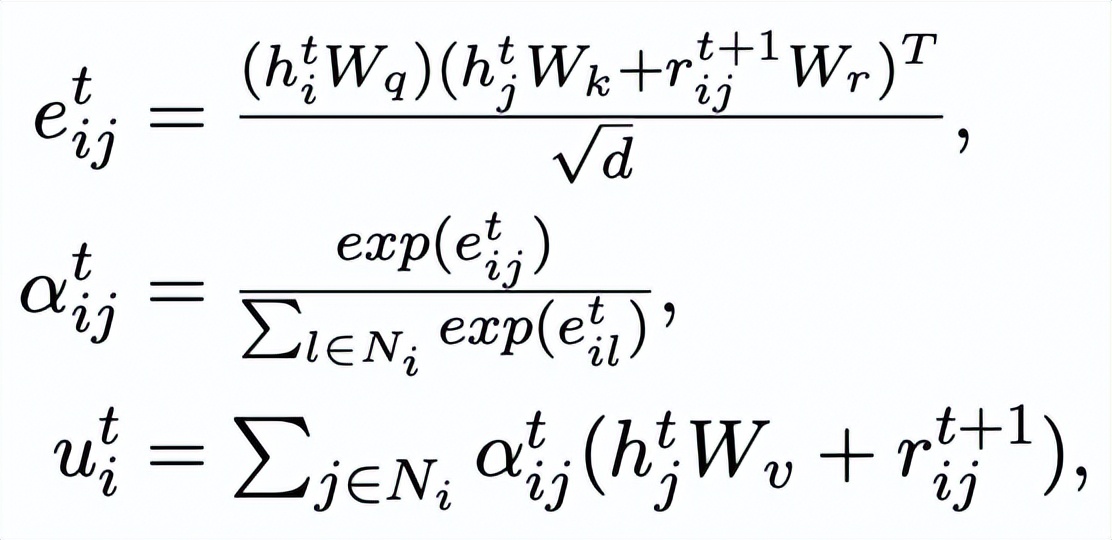
這里
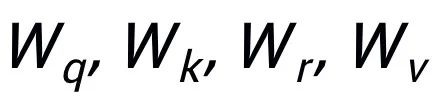
都是可學習的參數,
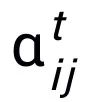
為注意力權重。為了防止梯度消失的問題,我們在
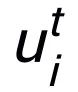
上加上了殘差連接,得到該迭代中節點的表示
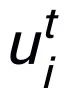
。我們使用最后一個迭代的節點表示作為關鍵詞的表示,記為 u。
- 關鍵詞對比
關鍵詞粒度的對比來自于輸入句子的關鍵詞

和一個偽裝(impostor)節點
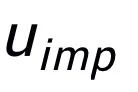
。我們將輸入句子的輸出正樣本中提取的關鍵詞記為
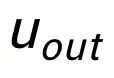
,它在上述關鍵詞網絡中的負鄰居節點記為
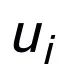
,則
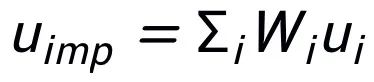
,關鍵詞粒度的對比學習 loss 計算如下:
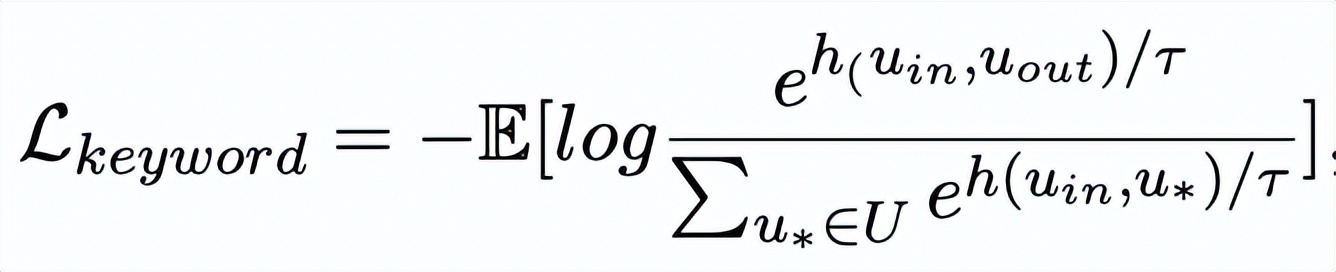
這里
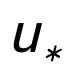
用來指代
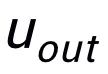
或者
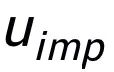
,h(·) 用來表示距離度量,在關鍵詞粒度的對比學習中我們選用了余弦相似度來計算兩個點之間的距離。
- 跨粒度對比學習
可以注意到上述句子粒度和關鍵詞粒度的對比學習分別是在分布和點上實現,這樣兩個粒度的獨立對比可能由于差異較小導致增強效果減弱。對此,我們基于點和分布之間的馬氏距離(Mahalanobis distance)[8] 構建不同粒度之間對比關聯,使得目標輸出關鍵詞到句子分布的距離盡可能小于 imposter 到該分布的距離,從而彌補各粒度獨立對比可能帶來的對比消失的缺陷。具體來說,跨粒度的馬氏距離對比學習希望盡可能縮小句子的后驗語義分布
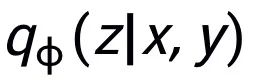
和
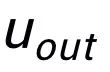
之間的距離,同時盡可能拉大其與
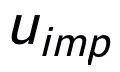
之間的距離,損失函數如下:
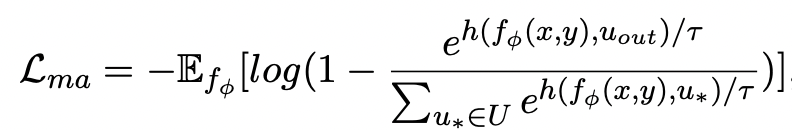
這里
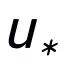
同樣用來指代
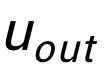
或者
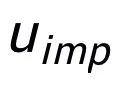
,而 h(·) 為馬氏距離。
實驗 & 分析
實驗結果
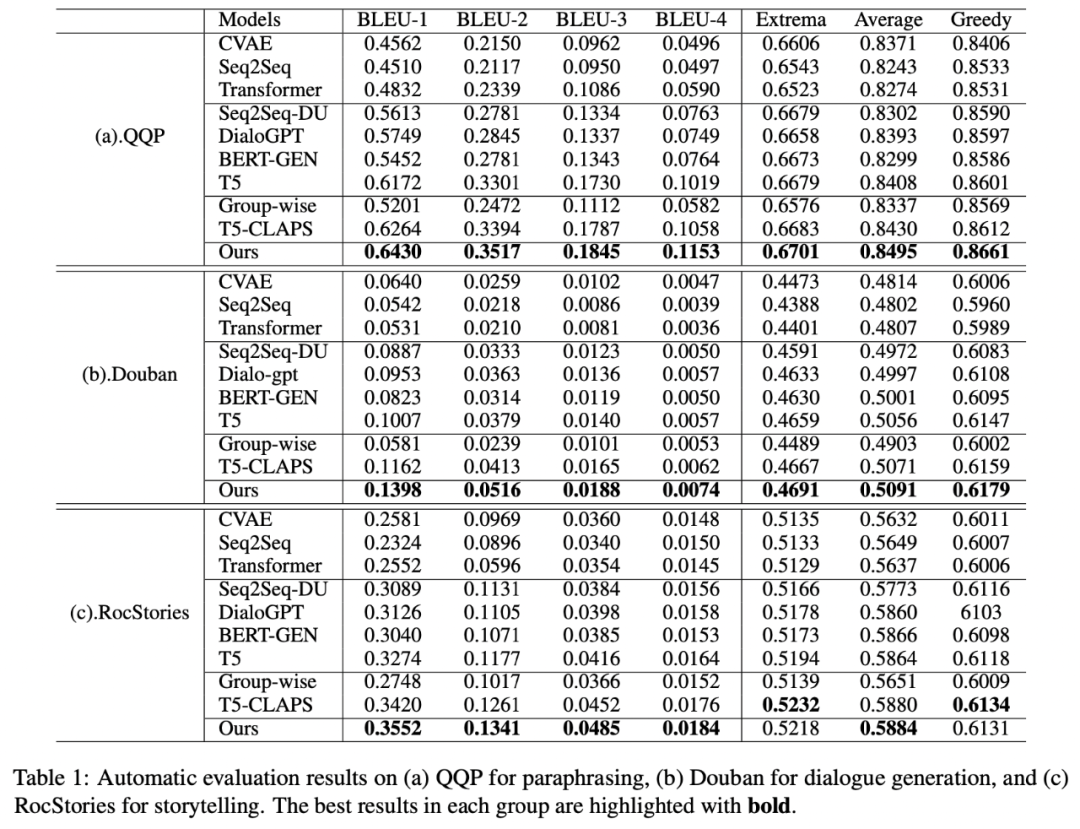
我們在三個公開數據集 Douban(Dialogue)[9],QQP(Paraphrasing)[10][11] 和 RocStories(Storytelling)[12] 上進行了實驗,均取得了 SOTA 的效果。我們對比的基線包括傳統的生成模型(e.g. CVAE[13],Seq2Seq[14],Transformer[15]),基于預訓練模型的方法(e.g. Seq2Seq-DU[16],DialoGPT[17],BERT-GEN[7],T5[18])以及基于對比學習的方法(e.g. Group-wise[9],T5-CLAPS[19])。我們通過計算 BLEU score[20] 和句對之間的 BOW embedding 距離(extrema/average/greedy)[21] 來作為自動化評價指標,結果如下圖所示:
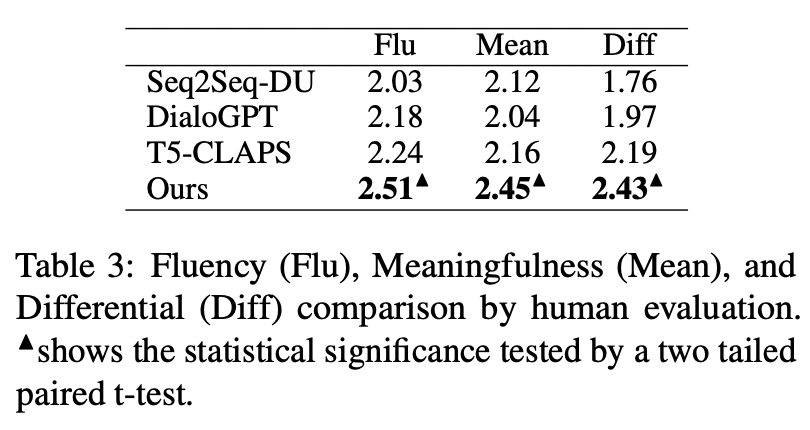
我們在 QQP 數據集上還采用了人工評估的方式,3 個標注人員分別對 T5-CLAPS,DialoGPT,Seq2Seq-DU 以及我們的模型產生的結果進行了標注,結果如下圖所示:
消融分析
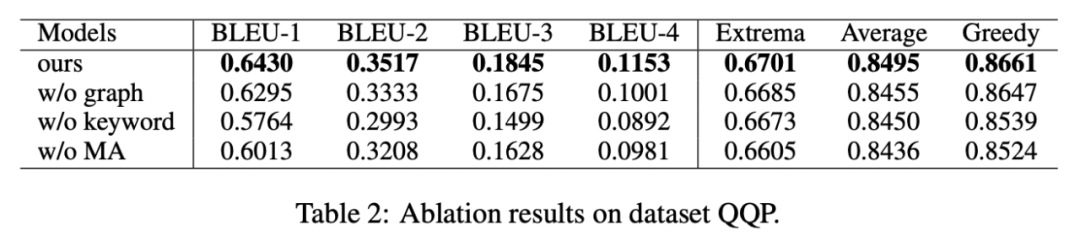
我們對是否采用關鍵詞、是否采用關鍵詞網絡以及是否采用馬氏距離對比分布進行了消融分析實驗,結果顯示這三種設計對最后的結果確實起到了重要的作用,實驗結果如下圖所示。
可視化分析
為了研究不同層級對比學習的作用,我們對隨機采樣的 case 進行了可視化,通過 t-sne[22] 進行降維處理后得到下圖。圖中可以看出,輸入句子的表示與抽取的關鍵詞表示接近,這說明關鍵詞作為句子中最重要的信息,通常會決定語義分布的位置。并且,在對比學習中我們可以看到經過訓練,輸入句子的分布與正樣本更接近,與負樣本遠離,這說明對比學習可以起到幫助修正語義分布的作用。
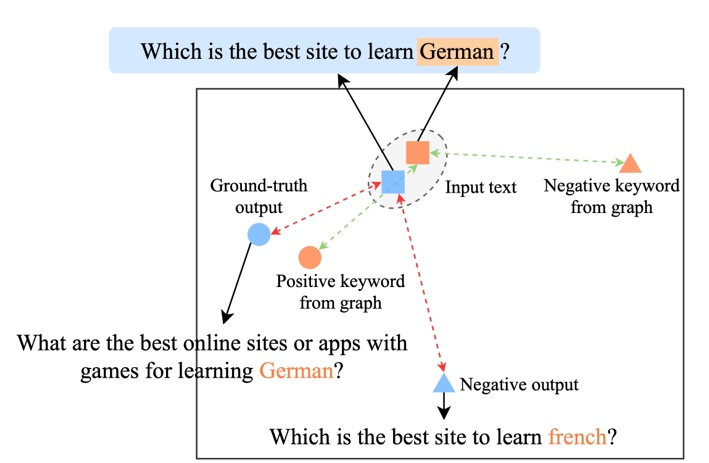
關鍵詞重要性分析
最后,我們探索采樣不同關鍵詞的影響。如下表所示,對于一個輸入問題,我們通過 TextRank 抽取和隨機選擇的方法分別提供關鍵詞作為控制語義分布的條件,并檢查生成文本的質量。關鍵詞作為句子中最重要的信息單元,不同的關鍵詞會導致不同的語義分布,產生不同的測試,選擇的關鍵詞越多,生成的句子越準確。同時,其他模型生成的結果也展示在下表中。

業務應用
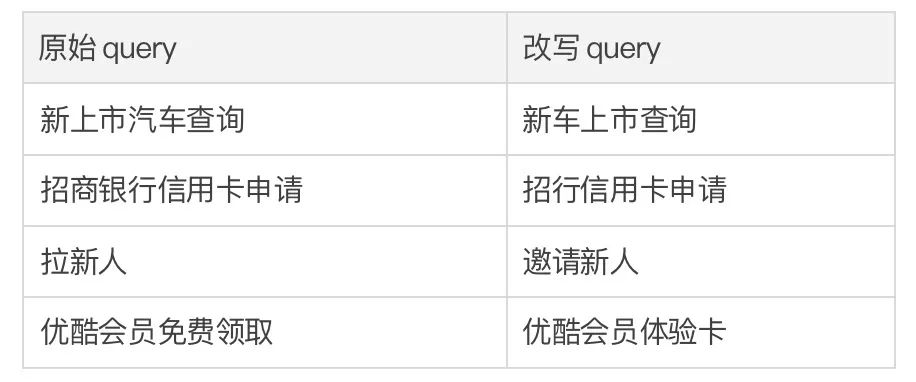
這篇文章中我們提出了一種跨粒度的層次化對比學習機制,在多個文本生成的數據集上均超過了具有競爭力的基線工作。基于該工作的 query 改寫模型在也在支付寶搜索的實際業務場景成功落地,取得了顯著的效果。支付寶搜索中的服務覆蓋領域寬廣并且領域特色顯著,用戶的搜索 query 表達與服務的表達存在巨大的字面差異,導致直接基于關鍵詞的匹配難以取得理想的效果(例如用戶輸入 query“新上市汽車查詢”,無法召回服務 “新車上市查詢”),query 改寫的目標是在保持 query 意圖不變的情況下,將用戶輸入的 query 改寫為更貼近服務表達的方式,從而更好的匹配到目標服務。如下是一些改寫示例: