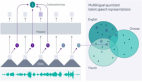
找不到中文語音預訓練模型?中文版 Wav2vec 2.0和HuBERT來了
Wav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等語音預訓練模型,通過在多達上萬小時的無標注語音數據(如 Libri-light )上的自監督學習,顯著提升了自動語音識別(Automatic Speech Recognition, ASR),語音合成(Text-to-speech, TTS)和語音轉換(Voice Conversation,VC)等語音下游任務的性能。然而這些模型都沒有公開的中文版本,不便于應用在中文語音研究場景。
WenetSpeech [4] 是由西工大音頻、語音和語言處理研究組 (ASLP@NPU)、出門問問、希爾貝殼聯合發布的 1 萬多小時多領域語音數據集。為了彌補中文語音預訓練模型的空缺,我們開源了基于 WenetSpeech 1 萬小時數據訓練的中文版 Wav2vec 2.0 和 HuBERT 模型。
為了驗證預訓練模型的性能,我們在 ASR 任務進行了驗證。實驗結果表明,在 100 小時有監督數據 ASR 任務上,預訓練模型學到的語音表征相對于傳統聲學 FBank 特征有顯著的性能提升,甚至僅用 100 小時有監督數據能夠得到和 1000 小時有監督數據可比的結果。
模型鏈接:https://github.com/TencentGameMate/chinese_speech_pretrain
模型介紹
Wav2vec 2.0 模型

圖 1: Wav2vec 2.0 模型結構 (Baevski et al., 2020)
Wav2vec 2.0 [1] 是 Meta 在 2020 年發表的無監督語音預訓練模型。它的核心思想是通過向量量化(Vector Quantization,VQ)構造自建監督訓練目標,對輸入做大量掩碼后利用對比學習損失函數進行訓練。模型結構如上圖 1,基于卷積網絡(Convoluational Neural Network,CNN)的特征提取器將原始音頻編碼為幀特征序列,通過 VQ 模塊把每幀特征轉變為離散特征 Q,并作為自監督目標。同時,幀特征序列做掩碼操作后進入 Transformer [5] 模型得到上下文表示 C。最后通過對比學習損失函數,拉近掩碼位置的上下文表示與對應的離散特征 q 的距離,即正樣本對。原論文中,Wav2vec 2.0 BASE 模型采用 12 層的 Transformer 結構,用 1000 小時的 LibriSpeech 數據進行訓練,LARGE 模型則采用 24 層 Transformer 結構,用 6 萬小時的 Libri-light 數據訓練。訓練時間方面,BASE 模型使用 64 塊 V100 顯卡訓練 1.6 天,LARGE 使用 128 塊 V100 顯卡訓練 5 天。在下游 ASR 評測中,即使只用 10 分鐘的有監督數據,系統仍可得到 4.8 的詞錯誤率(Word Error Rate, WER)結果。
HuBERT 模型

圖 2: HuBERT 模型結構 (Hsu et al., 2021)
HuBERT [2] 是 Meta 在 2021 年發表的模型,模型結構類似 Wav2vec 2.0,不同的是訓練方法。Wav2vec 2.0 是在訓練時將語音特征離散化作為自監督目標,而 HuBERT 則通過在 MFCC 特征或 HuBERT 特征上做 K-means 聚類,得到訓練目標。HuBERT 模型采用迭代訓練的方式,BASE 模型第一次迭代在 MFCC 特征上做聚類,第二次迭代在第一次迭代得到的 HuBERT 模型的中間層特征上做聚類,LARGE 和 XLARGE 模型則用 BASE 模型的第二次迭代模型提取特征做聚類。從原始論文實驗結果來看,HuBERT 模型效果要優于 Wav2vec 2.0,特別是下游任務有監督訓練數據極少的情況,如 1 小時、10 分鐘。
中文預訓練模型
實驗配置我們使用 WenetSpeech [4] train_l 集的 1 萬小時中文數據作為無監督預訓練數據。數據主要來源于 YouTube 和 Podcast,覆蓋了各種類型錄制場景、背景噪聲、說話方式等,其領域主要包括有聲書、解說、紀錄片、電視劇、訪談、新聞、朗讀、演講、綜藝和其他等 10 大場景。我們基于 Fairseq 工具包 [6] 分別訓練了 Wav2vec 2.0 和 HuBERT 模型,遵循 [1,2] 的模型配置,每個預訓練模型模型包括 BASE 和 LARGE 兩種大小。對于 BASE 模型,我們使用 8 張 A100 顯卡,梯度累計為 8,模擬 64 張顯卡進行訓練。對于 LARGE 模型,我們使用 16 張 A100 顯卡,梯度累計為 8,模擬 128 張顯卡進行訓練。
下游語音識別任務驗證為了驗證預訓練模型在下游 ASR 任務的效果,我們遵循 ESPnet [7,8,9] 工具包中的 Conformer [10] 模型實驗配置,即將預訓練模型作為特征提取器,對于輸入語音提取預訓練模型各隱層表征進行加權求和,得到的語音表征將替換傳統 FBank 特征作為 Conformer ASR 模型的輸入。
- Aishell 數據集
我們使用 Aishell 178 小時訓練集作為有監督數據進行訓練,分別對比了使用 FBank 特征、Wav2vec 2.0 BASE/LARGE 模型特征和 HuBERT BASE/LARGE 模型特征的字錯誤率 (Character Error Rate, CER) 結果。同時,我們額外對比了使用 WenetSpeech train_l 集 1 萬小時中文數據進行訓練時,其在 Aishell 測試集上的效果。訓練數據使用了變速(0.9、1.0、1.1 倍)和 SpecAugment 數據增廣技術,解碼方式為 beam search,使用了基于 Transformer 的語言模型進行 rescoring。

表 1:不同模型在 Aishell 測試集上的字錯誤率(CER%)結果
根據表 1 結果可以看到,通過結合上萬小時無監督數據訓練的預訓練模型,下游 ASR 任務效果均有顯著提升。尤其是使用 HuBERT LARGE 模型時,在 Test 集上得到約 30% 的 CER 相對提升,實現了目前在 178h 有監督訓練數據下業界最好結果。
- WenetSpeech 數據集
我們使用 WenetSpeech train_s 集 100 小時中文數據作為有監督數據進行訓練,分別對比了使用 FBank 特征、Wav2vec 2.0 BASE/LARGE 模型特征和 HuBERT BASE/LARGE 模型特征的字錯誤率 (Character Error Rate, CER) 結果。同時,我們額外對比了使用 WenetSpeech train_m 集 1000 小時和 train_l 集 1 萬小時中文數據 FBank 特征訓練的模型結果。訓練數據沒有使用變速或 SpecAugment 數據增廣技術,解碼方式為 beam search,沒有使用語言模型 rescoring。

表 2:不同模型在 WenetSpeech 測試集上的字錯誤率(CER%)結果
根據表 2 結果可以看到,通過結合上萬小時無監督數據訓練的預訓練模型,下游 ASR 結果得到了巨大提升。尤其當使用 HuBERT LARGE 作為語音表征提取器時,使用 100 小時有監督數據訓練的 ASR 模型要比 1000 小時基于 FBank 特征訓練的模型效果要好,甚至接近 1 萬小時數據訓練的模型。
更多語音下游任務實驗結果請關注 GitHub 鏈接(https://github.com/TencentGameMate/chinese_speech_pretrain)。歡迎大家使用我們提供的中文語音預訓練模型開展研究工作,一起探索語音預訓練模型在中文和相關眾多場景下的應用。