備戰618,省時省力的全鏈路壓測系統怎么搭?
?一、背景
隨著公司交易體量的不斷增長,以及圍繞“服務千萬商家,全能生意幫手”的理念不斷拼裝的業務版圖,曾經在某一段時間內發生了一些故障,給用戶和商戶帶來非常不好的體驗,也給公司帶來較大損失。
線下我們明明做了各種驗證測試,功能、性能等,怎么一上線還是各種問題?
老板或者運營同學說,我們馬上要做活動,線上能支撐得住吧?
IT環境成本又增長了,但是業務又沒有多大增長,能降低線上IT成本嗎?
上面類似的問題,相信很多同學都碰到過,解決辦法業界也有比較成熟的方案,就是全鏈路壓測。
二、解決方案
1、傳統線上壓測
在全鏈路壓測之前,我們線上環境壓測,往往采用如下方式進行:
- 線上環境預先準備好測試數據,模擬請求針對單個服務或者集群壓測;
- nginx鏡像一份流量來壓測。
上述的壓測方式有以下問題:?
- 費時費力,前期需要構建大量測試數據;
- 產生臟數據,污染線上數據庫等;
- 壓測模型需人為構建,導致壓測結果不精準;
- 僅覆蓋關鍵核心服務,壓測覆蓋面窄;
- 難以覆蓋鏈路上的基礎設施,比如slb、nginx、網絡、數據庫等。
2、現在方案
基于上述問題以及收錢吧具體業務需求,我們設計開發了全鏈路壓測系統Havok。作為公司層級的全鏈路壓測平臺,主要設計目標就是為公司業務提供真實、安全的仿真流量輸出,同時給業務團隊提供準確的容量評估數據,所以我們主要提供如下能力:
1)真實重現用戶行為,持續輸出真實壓測流量
真實復現線上用戶行為,按時間輪回放真實流量,同時不污染線上數據,用戶無感。
2)提供按速率和倍數來放大流量
在上一步的基礎能力上,可以按照預設的速率或者倍數來放大流量,進而探測線上容量。
3)具備“開箱及測”的能力
不需要前期花費過多精力構造測試數據等準備工作,做到想什么時候壓測就什么時候開始;同時不污染生產數據。
4)支持多種壓測類型
支持普遍的http接口壓測,支持收錢吧內部的rpc請求壓測以及移動設備的特殊協議壓測
5)提供壓測過程中實時的監控和過載保護能力
提供實時監控數據收集查看的能力,同時根據預定規則提供自動停止壓測來保護線上環境的能力。
三、系統架構設計
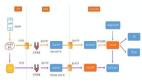
我們采取的方式是回放生產服務日志來實現壓測,包括讀和寫操作,同時根據日志的時間戳來控制阻塞/放行請求,來達到高仿真壓測的目的,整體架構如下:

- Havok-dispatcher【調度中心】:負責線上服務日志數據的下載、排序(有規則約束)、時間控制、請求分發、壓測引擎監控數據的收集和上送等功能。
- Havok-replayer【壓測引擎】:負責根據既定規則回放dispatcher訂閱的壓測請求、支持回放請求的增益調整、支持壓測數據的規則調整等功能。
- Havok-monitor【監控平臺】:收集并展示壓測引擎的數據、線上服務的監控數據、中間件等數據。
- Havok-mock【mock服務】:提供mock服務功能。
- Havok-canal【數據構造】:提供影子數據的實時增量清洗。
四、主要模塊功能介紹
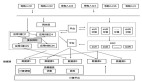
1、調度中心核心功能
調度中心核心功能是日志抽取以及請求下發,支持多個數據源、支持維度篩選、保序日志分發、增益能力、監控數據查看上送、壓測引擎的管理調度。整體設計如下圖:

1)為什么采取回放方式
假設有這么一個外賣下單接口: POST /api/order,需要傳入商戶ID、菜品ID等參數,如果計劃用100并發線程去壓這個接口,你肯定會考慮以下幾個問題:
- 是使用同一商戶、同一菜品去壓測?
- 是使用同一商戶、不同菜品去壓測?
- 是使用100個商戶、不同菜品去壓測?
- 是使用20個商戶、每個商戶相同菜品去壓測?
場景設置外,還有其他諸如:
- 緩存如何控制?是否需要避免命中緩存?是否考慮命中緩存概率?
- 查詢請求,是否要考慮存量數據的查詢效率影響?是否考慮數據庫分庫分表?
- .....
這么多場景構造,很麻煩...
日志回放方式就相對較好的解決上面的困擾,因為壓測請求場景的構造,日志里已經告訴我了,要做的就是塞到壓測請求里回放就行了,我不需要考慮如何設計。同時利用好現有的數據庫表、緩存等設施,我也就不需要考慮數據多樣性等問題。
2)如何做到高仿真
除了如實的回放請求內容外,我們還得控制好回放的節奏,就像一首歌,同樣的磁帶,播放的速度不一樣那出來的節奏肯定不一樣。所以我們還嚴格按照日志的時間戳來控制好回放的節奏,做到回放出的不僅歌詞一樣,同時節奏也一樣。timewheel模塊就承擔了這樣的職責,支持快放、慢放。
3)增益能力
為了滿足業務容量探測設計,提供了請求的增益(倍率)能力,能將一個請求復制出多份,從而實現對業務增長的模擬。另外,即便一比一等量回放,我們依然要面對回放型壓測中不得不解決的一個問題:冪等性。
f(x) = f(f(x))
舉個例子:我們的創建商戶接口 POST: /api/createMch,要求傳入的商戶名稱是唯一的(業務要求),這個時候日志里包含了一個創建商戶的動作,創建了一家小吃店:XX小吃。如果你從日志中提取后,重放這個請求,必然創建失敗:數據庫中已經存在該商戶。
因此不但需要實現請求增益能力還需要解決接口冪等性的問題。目前我們兩個思路:
- Havok 接口層面支持自定義關鍵字偏移修改,避免沖突。
- 被壓服務層面做好冪等處理。
2、壓測引擎核心功能
壓測引擎主要功能有:
1)支持分布式容器化部署
容器化部署,可以快速擴展壓測引擎能力。
2)異步發送/接收消息
采用異步請求方式處理請求和響應,提高并發能力,Havok基于goroutine來實現,如下好處:
- goroutine的切換沒有內核開銷;
- 內存占用小,線程棧空間通常是2M,goroutine棧空間通常是2K;
- G-M-P調度模型。
3)接口請求和響應字段的過濾調整
針對敏感數據統一處理;根據預定規則偏移數據以方便壓測;針對響應進行定制化assert。
4)接口層級各個維度的統計
統計接口錯誤率、吞吐量、P95等指標并上報給調度中心。
5)響應調度中心事件下發處理
處理調度中心下發的開始壓測、停止壓測、熔斷等指令。
3、數據構造
傳統的壓測很大一部分工作就是前期的數據構造,面臨如下等問題:
- 數據樣本類別分布不均衡,多樣性不足;
- 數據量偏少;
- 構建數據耗時過長。
所以我們基于阿里的canal[1]增量同步服務定制開發了符合我們壓測要求的功能,比如偏移數據等功能。達到想什么時候壓測就什么開始,相比以往大大提高了執行周期效率。
- 敏感數據,諸如電話號碼、身份證號等統一脫敏偏移處理。
- 商戶號、門店號、終端號等信息按既定規則偏移處理,不影響實際線上商戶使用。
 4、Mock第三方服務接口
4、Mock第三方服務接口
針對第三方服務,我們采取的是mock處理,mock支持延時抖動等特性,同時通過事后的正態分布分析調整mock相關配置,盡量匹配生產相關處理的生命周期模擬;
- 自研通用mock服務DeepMock[2]:壓測前,需要注入mock規則以及響應規則

5、壓測監控
線上壓測肯定會線上服務產生一定影響,所以我們需要做到對相關鏈路秒級的監控,以及針對異常快速做出熔斷等反應,架構如下:

1)施壓端監控
壓測引擎會每秒匯總好接口層級的監控數據上送給調度中心再處理,指標包括接口錯誤率、吞吐量、top90、top95、avg響應時間等。

2)服務端監控
由于公司服務設施基本部署在云上,所以服務端監控基本依賴現有云端監控設施,包括中間件監控。

6、壓測隔離
線上壓測要保證壓測行為真實、安全且可控,不會影響正常用戶的使用,并且不會對線上環境造成任何數據的污染。要做到這一點,首先需要解決的是壓測流量的識別與透傳問題。有了壓測標識后,各服務與中間件就可以依據標識來進行壓測服務是否隔離、流量是否透傳以及影子表等方案的實施。
1)壓測標識透傳
壓測標識,目前我們采取的key:value方式染色壓測流量,同時我們相關鏈路的服務以及基礎RPC框架等中間件都已配合改造以識別。
改造原理是將壓測標識的 kv 值存入 Context 中,然后發往下游的請求中都帶上該 Context,下游服務可以根據 Context 中的壓測標識完成對壓測流量的識別和處理。在實際業務中,代碼改造也非常簡單,只需要透傳 Context 即可。
7、數據隔離
線上壓測相對比較復雜的就是如何確保壓測產生的寫數據不污染線上數據,業界常見做法比如影子表、影子庫,以及數據偏移等。
我們針對不同存儲,采取不同策略:
- MySQL、MongoDB:采用影子表方式,應用層面根據壓測標識來區分壓測流量讀影子表、寫影子表;影子表數據的偏移規則支持[stress_tag]前綴、隨機字符串、uuid、字符反轉等等替換方式。
- Redis:key偏移后使用,壓測完失效或者刪除即可。
- Kafka或者MQ:兩種策略,一種業務層面直接丟棄不下發,然后后續單獨壓測;或者透傳壓測標識,consumer根據自身業務情況改造處理。
- 其他存儲:比如ES,單獨壓測集群,壓測時啟用。

8、熔斷保護機制
1)施壓端熔斷
Havok會實時分析監控指標數據,根據業務配置閾值,實時給壓測引擎下發降低QPS或者停止壓測事件,防止壓垮線上系統。
2)服務端熔斷
線上業務自身具備熔斷能力,基于相應中間件實現,根據閾值,比如錯誤率自動熔斷。
五、壓測實施
目前公司部分核心業務已經接入,包括門店碼支付、被掃支付、小程序支付等等,后續業務也在陸續推進接入中,隨著業務線壓測的推進,我們從中也學到了大量的業務知識,架構知識,接收到不少反饋,持續推動我們不斷演進和優化Havok。目前已經開源Havok[3],歡迎志同道合者提出寶貴意見或者PR。
六、總結與展望
從項目立項到成功投產壓測,得到了產研同學的大力支持和幫助,尤其是各個業務線配合改造,真心感謝,正是在大家的配合下,才能夠初具規模。展望未來我們還有較長路需要走,期望能夠幫助大家提高研發效率,及時發現性能問題。
1、易用性提高
由于多種因素影響,目前我們在用戶易用性上還有待提高,期望后續在可視化操作上投入更多精力,盡量降低研發同學使用難度,傻瓜式操作。
2、壓測與SLA建設
如何精準評估業務線的容量規劃?按照目前的壓測數據,動態評估還能支撐多久的業務規模增長?線上機器資源是否可以優化,進一步降低成本?如何配合公司層級的混沌測試?這些問題都需要我們推進和解決中。