服務治理怎么做:降級、熔斷、全鏈路壓測
作者:greencoatman
在高峰期或者流量激增的情況下,為了防止系統崩潰,可以暫時關閉或降低某些非關鍵服務的質量。
 圖片
圖片
服務降級的常見場景
- 系統負載過高:在高峰期或者流量激增的情況下,為了防止系統崩潰,可以暫時關閉或降低某些非關鍵服務的質量。
- 依賴服務故障:當某個依賴服務不可用時,通過服務降級可以提供替代方案或者簡化的功能,以確保系統核心功能的正常運作。
- 網絡問題:在網絡延遲或不穩定的情況下,降低某些服務的請求頻率或數據量,以減輕系統負擔。
- 資源不足:當系統資源(如 CPU、內存)不足時,通過服務降級減少資源消耗。
服務降級的策略
- 功能降級:暫時關閉或簡化某些非關鍵功能。例如,關閉推薦系統、日志記錄等不影響核心功能的服務。
- 數據降級:降低數據返回的粒度或數量。例如,從詳細數據切換為概要數據。
- 延遲處理:將非緊急的任務延遲處理或批量處理。例如,將某些后臺任務延遲執行,減輕當前系統負擔。
- 限流:限制部分用戶的訪問,優先保證核心用戶或付費用戶的服務質量。
實施服務降級的技術手段
- 熔斷器模式(Circuit Breaker Pattern):當檢測到某個服務不可用時,主動切斷對該服務的調用,避免影響其他服務。
- 限流器(Rate Limiter):限制單位時間內的請求數量,防止系統過載。
- 降級開關:通過配置中心動態調整服務降級策略,靈活應對不同場景。
- 緩存:使用緩存減輕數據庫或其他后端服務的壓力,提供快速響應。
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
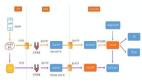
工作流程
請求通過熔斷器:
- 每個請求通過熔斷器進行計數,監控其成功或失敗狀態。
- 如果請求成功,計數器重置。
- 如果請求失敗,計數器記錄失敗。
監控和評估:
Hystrix 會監控一段時間內(例如 10 秒)的請求數量和失敗率。
如果在這段時間內請求數量超過設定的最小請求數,并且失敗率超過設定的閾值,熔斷器將跳到打開狀態。
短路請求:
在打開狀態下,所有請求都會被短路,不會真正調用下游服務,而是立即返回一個預設的降級響應。
這樣可以防止下游服務的故障影響到整個系統,并減輕下游服務的負載。
嘗試恢復:
在打開狀態持續一段時間后,熔斷器進入半開狀態,允許少量請求通過。
如果這些請求成功,熔斷器將關閉,恢復正常請求。
如果這些請求失敗,熔斷器將重新打開,并繼續短路請求。
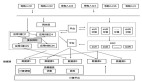
 服務灰度發布設計與實踐
服務灰度發布設計與實踐
 圖片
圖片
優點:
- 降低風險:通過逐步發布新版本,團隊可以在小范圍內驗證新功能的有效性,降低全量發布帶來的風險。
- 快速反饋:在發布過程中,可以迅速收集用戶反饋和監控數據,及時發現和解決問題。
- 持續交付:灰度發布與持續交付和持續部署實踐相結合,可以實現快速、頻繁和穩定的發布。
- 平滑過渡:避免了大規模發布帶來的潛在問題,確保系統平穩運行。
服務灰度發布的工具
- 服務網關:如 NGINX、Kong 等,可以配置流量路由規則,實現灰度發布。
- 容器編排:如 Kubernetes,可以通過配置滾動更新和分階段發布策略實現灰度發布。
- 服務網格:如 Istio、Linkerd,可以細粒度地控制服務間的流量,實現灰度發布。
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
服務全鏈路壓測設計
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
 圖片
圖片
責任編輯:武曉燕
來源:
二進制跳動