10億+/秒!看阿里如何搞定實時數倉高吞吐實時寫入與更新
原創作者 | 胡一博(上唐)
數據實時入倉所面臨的挑戰:高性能、可更新、大規模
大數據場景下,實時數據如何寫入實時數倉永遠是一個比較大的話題,根據業務場景需求,常見的寫入類型有:
- Append only:傳統日志類數據(日志、埋點等)中,記錄(Record)和記錄之間沒有關聯性,因此新來的記錄只需要append到系統中就好了。這是傳統大數據系統最擅長的一種類型。
- Insert or Replace:根據設置的主鍵(Primary Key, PK)進行檢查,如果系統中不存在此PK,就把這行記錄append進系統; 如果存在,就把系統中舊的記錄用新的記錄整行覆蓋。典型的使用場景有:
上游數據庫通過Binlog實時同步,這種寫入就是Insert or Replace。
Flink的結果實時寫出。Flink持續刷新結果,需要Insert or Replace的寫目標表。
Lambda架構下的離線回刷。Lambda架構下離線鏈路T+1回刷實時結果表中昨天的記錄。
- Insert or Update:通常使用在多個應用更新同一行數據的不同字段,實現多個數據源的JOIN。如果這行記錄存在,各個應用直接根據PK去update各自的字段;但如果這行記錄不存在,那么第一個要寫入這行記錄的應用就需要INSERT這行記錄。典型的使用場景:
畫像類應用。這類應用在實時風控、實時廣告投放等非常常見。上游多個Flink Job實時計算畫像的不同維度,并實時寫入到同一行記錄的不同字段中。
實時離線數據整合。在需要同時用到實時和離線計算的場合,把同一個PK的實時和離線結果放在同一行記錄的不同字段中,就可以方便的同時取到實時和離線的計算結果。

下文中,我們把Insert or Replace和Insert or Update統稱為Upsert。
而要保持非常高效的寫入性能,實時數倉技術都面臨著非常大的挑戰,典型的挑戰有以下幾個方面:
挑戰一:Merge on Read還是Merge on Write?
Upsert模式下,新舊數據的合并發生在什么時候,如果希望查詢性能好,那么肯定希望合并發生在寫入時(Merge on Write)。這樣,在系統中任何時刻任一主鍵都只有一條記錄;而如果希望寫入性能好,那么就是寫入不做合并,查詢時再做合并(Merge on Read)。這對于查詢是非常不友好的,極大限制查詢性能。
Merge on Read原理示例:

Merge on Write原理示例:

挑戰二:是否支持主鍵(Primary Key)模型?
實時數倉在數據模型上是不是支持主鍵對于Upsert的實時寫入是至關重要的。如果沒有主鍵,在寫入側數據的更新就很容易退化成全表更新,性能非常差,在查詢側,Merge On Read也無從做起。
挑戰三:是否保證寫入的Exactly Once?
如果上游因為failover等因素導致寫入重復執行,能不能保證系統中只有一條記錄(Merge on Write)或者查詢時等效只有一條數據(Merge on Read)且是最新的數據?大數據系統復雜,上游系統failover是常態,不能因為上游failover,就導致實時數倉數據重復。
問題四:數據是否寫入即可見?
數據寫入的時效性也是實時數倉的重要能力之一。對于BI類等延遲不敏感的業務查詢,如果寫入時延幾秒甚至幾分鐘可能是可以接受的。而對于很多生產系統,如實時風控、實時大屏等場景,要求數據寫入即可見。如果寫入出現延遲,就會查詢不到最新的數據,嚴重影響線上業務決策。
挑戰五:如何支持超大的數據量和超高的RPS實時寫入(每秒記錄數,Record Per Second)?
如果數據量小,寫入RPS要求低,一個傳統的數據庫就能很好的解決這個問題。但是在大數據場景下,當RPS達到幾十萬幾百萬時,如何更好支持數據的實時寫入?同時,如果目標表中已經有海量數量(十億、百億甚至更多)時,Upsert要求訪問和訂正已有數據,這時是否還能支持高性能的Upsert?
Hologres的實時寫入模型與性能
Hologres是阿里自研的一站式大數據實時數倉,在設計之初就對實時寫入場景進行了充分的考慮,主要有以下幾個方面:
- 支持主鍵,可以高效利用主鍵更新、刪除數據。
- 支持Upsert:完整支持高性能的Append Only、Insert or Replace、Insert or Update 3種能力,可根據業務場景選擇寫入模式。
- 對于列存表,自動使用Merge on Write方案。對于行存表,自動使用Merge on Read方案,原因如下:
對于列存表,主要是做復雜的OLAP分析,因此查詢性能最重要。
對于行存表來說,查詢主要是點查,此時Merge on Read單行的開銷足夠小,因此重點考慮寫入性能。在阿里很多點查場景,寫入要求非常高的RPS。
- 支持Exactly Once。通過單行SQL事務和主鍵PK自動去重來實現。無論是批量數據寫入(一次更新幾億條記錄),還是逐條記錄實時寫入,Hologres都是保證單條SQL的原子性(ACID)。而對于上游Flink等failover造成的SQL重發,Hologres通過目標表的主鍵,實現自動覆蓋或者忽略(對于Upsert是自動覆蓋;對于append,是自動忽略Insert or Ignore)。因此,目標表是冪等的。
- 寫入即可見。Hologres沒有類似ElasticSearch的build過程,也沒有類似ClickHouse或者Greenplum的攢批過程,數據通過SQL寫入時,SQL返回即表示寫入完成,數據即可查詢。因此通過Flink等實時寫入(背后也是SQL寫入)能滿足寫入即可見,無延遲。
這5個設計選取也是傳統數據庫的選擇。經驗證明,這對于用戶來說是最自然、最友好的使用方式。Hologres的創新在于把這個方案成功的應用于大數據領域(超高RPS寫入和超大存儲量)。
下圖為Hologres 128C實例下,10個并發實時寫入20列的列存表的測試結果。其中豎軸表示每秒寫入記錄數,4個場景分別為:
- case1:寫入無主鍵表;
- case2:寫入有主鍵表(Insert or Replace),并且每次INSERT的主鍵和表已有數據都不沖突;
- case3:寫入有主鍵表(Insert or Replace),并且每次INSERT的主鍵和表已有數據均沖突,表中數據量為2億。
- case4:寫入有主鍵表(Insert or Replace),并且每次INSERT的主鍵和表已有數據均沖突,表中數據量為20億。

結果解讀:
- 對比case1和case2,可以看到Hologres判斷主鍵是否存在性能損失較小;
- 對比case2,case3,case4,可以看到主鍵沖突時,hologres定位數據所在文件并標記DELETE基本不隨數據規模上漲而上漲,可以應對海量數據下的高速Upsert。
與常見產品對比
寫入方式 | 更新/刪除方式 | 更新刪除對查詢的影響 | |
ClickHouse | 攢批寫入,每個批次完成才能查詢到數據 | merge on read | 查詢明細時相同pk可能多次出現,取決于compaction時機 |
Doris | 攢批寫入,每個批次完成才能查詢到數據 | merge on read | 查詢時要進行合并,性能有損失 |
Hudi/iceberg/delta lake等數據湖產品 | 攢批寫入,每個批次完成才能查詢到數據 | merge on read或copy on write,大多會造成全量數據重寫,導致IO放大 | merge on read,查詢時要進行合并,性能有損失;copy on write,查詢性能沒有影響 |
Hologres | 流式寫入,寫入即可查詢,低延遲 | Merge on write強主鍵模型,更新/刪除成本非常低。 | 通過delete bitmap技術實現Merge on Write,更新/刪除對查詢沒有影響 |
Merge on Write模式下 實時寫入與更新的常見原理
一個典型的Upsert(Insert or Replace)場景如下,一張用戶表,通過INSERT INTO ON CONFLICT執行插入新用戶/更新老用戶操作:
CREATE TABLE users (
id int not null,
name text not null,
age int,
primary key(id)
);
INSERT INTO users VALUES (?,?,?)
ON CONFLICT(id) DO UPDATE
SET name = EXCLUDED.name, sex = EXCLUDED.sex, age = EXCLUDED.age;
性能最高的實現方式是寫入時APPEND ONLY不斷寫入新文件,在查詢時進行數據邏輯合并(Merge on Read)。但這種對查詢的性能打擊是致命的,每次查詢要多個版本的數據join過才能獲取到一行最新的值。實時數倉在寫時合并(Merge on Write)方案下,Upsert的實現一般分為三步:
- 定位舊數據所在文件。
- 處理舊數據
- 寫入新數據
要實現高RPS的實時Upsert,本質就是要把這3個步驟都做快。
1.定位舊數據所在文件
快速定位舊數據文件,有如下幾種做法:
1)bloom過濾器
bloom過濾器原理上是為每個key生成若干個hash值,通過hash碰撞來判斷是否存在相同的key。為每個文件生成一個bloom過濾器,可以明確排除不存在該key的文件。Bloom過濾器可以以很高的精度(99%甚至更高)確定一個Key不在一個文件中。
2)范圍過濾器
范圍過濾器就是記錄文件內列的最大最小值,是一個代價非常小的過濾方式,當key基本處于一個遞增態勢是可以得到一個非常好的過濾效果。
3)外部索引
Hudi支持HBase索引,在HBase中保存PK->file_id的映射。HBase LSM-tree的存儲結構對于key-value的查詢非常高效,Hudi通過這種方式也不再需要去猜測哪些文件可能包含了這個PK。但是這里有兩個問題:
- HBase狀態和Hudi表狀態的一致性,因為HBase和Hudi是獨立的兩套系統,一方如果發生故障可能導致索引失效。
- 性能上限是HBase的PK點查性能。要取得更好的寫入性能是困難的。
2.處理舊數據+寫入新數據
常見的是兩種處理方法:
1)刷新數據文件
定位到數據所在文件后,將文件和新數據合并后生成一個新的數據文件覆蓋舊文件。(Copy on Write)。Iceberg支持這種模式。這會導致非常嚴重的寫放大。
2)引入delta文件
定位到數據所在文件后:
- 在數據文件對應的delta文件中標記該行舊數據為刪除狀態。
- 在delta中追加新數據的信息。
這種方式沒有寫放大,但是在查詢時需要將數據文件和對應的delta文件做join操作。
Hologres 基于Memtable的寫入原理
Hologres的實時寫入與更新基本遵循Merge on Write的原理。對于實時數倉場景下的record級別的更新/插入,Hologres采用強主鍵的方式來讓單行更新/插入足夠輕量化,采用memtable + wal log的方式,支持高頻次的寫入操作。
1.文件模型
Hologres每張列存表底層會保存三種文件:
第一種是主鍵索引文件,采用行存結構存儲,提供高速的key-value服務,索引文件的key為表的主鍵,value為unique_id和聚簇索引。unique_id每次Upsert自動生成,單調遞增。主鍵索引文件實現高效的主鍵沖突判定并輔助數據文件定位;
第二種是數據文件,采用列存結構存儲,文件內按照聚簇索引+unique_id生成稀疏索引,并對unique_id生成范圍過濾器;
第三種是delete bitmap文件,每個file id對應一個bitmap,bitmap中第N位為1表示file id中的第N行標記為刪除。delete bitmap在列存模型下,相當于是表的一列數據。Update時只刷新bitmap信息既保留了Merge on Write對查詢性能幾乎零破壞的優點,又極大降低了IO的開銷。
三類文件都是先寫入memtable,memtable達到特定大小后轉為不可變的memtable對象,并生成新的memtable供后續寫入使用。不可變的memtable對象由異步的flush線程將其持久化為磁盤上的文件。
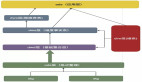
2.Upsert流程
通過這個流程圖可以看到:
- 如果主鍵沒有發生沖突,那么一次Upsert的的開銷= 一次索引查詢 + 兩次內存寫入操作;
- 如果主鍵發生了沖突,那么一次Upsert的開銷=一次索引查詢 + 一次文件及行號定位 +三次內存寫入操作。

3.Upsert示例
下面通過示例來展示一次Upsert的過程。假設pk為id,cluserting key為name,數據列為age。(deleted信息物理上存儲于delete bitmap中,但邏輯上等同與表的一列,下文將合并在數據文件中一同描述)
CREATE TABLE users (
id text not null,
name text not null,
age int,
primary key(id)
);
表初始數據如下:
id | name | age |
u0 | 張三 | 10 |
u1 | 李四 | 11 |
u2 | 王五 | 12 |

此時執行如下SQL:
INSERT INTO users VALUES ('u1','新李四',12)
ON CONFLICT(id) DO UPDATE
SET name = EXCLUDED.name
, age = EXCLUDED.age;
更新過程如下:

更新完成后表數據如下:
id | name | age |
u0 | 張三 | 10 |
u1 | 新李四 | 12 |
u2 | 王五 | 12 |
Hologres寫入全鏈路優化,雕琢細節
Hologres在接口上完全兼容PostgreSQL(包括語法、語義、協議等),所以可以直接使用PostgreSQL的JDBC Driver連接Hologres進行數據讀寫。除了寫入原理上的創新性外,Hologres也針對寫入進行了全鏈路的優化,以達到更高性能的吞吐。
1.Fixed Plan:降低、避免SQL解析與優化器的開銷
- Query Optimizer進行shortcut
對于符合pattern的Upsert sql,Hologres的Query Optimizer進行了相應的short cut,Upsert Query并不會進入Opimizer的完整流程。Query進入FrontEnd后它會交由Fixed Planner進行處理,并由其生成對于的Fixed Plan(Upsert的物理Plan),Fixed Planner非常輕,無需經過任何的等價變換、邏輯優化、物理優化等步驟,僅僅是基于AST樹進行了一些簡單的分析并構建出對應的Fixed Plan,從而盡量規避掉優化器的開銷。
- Prepared Statement
盡管Query Optimizer對Upsert Query進行了short cut,但是Query進入到FrontEnd后的解析開銷依然存在、Query Optimizer的開銷也沒有完全避免。
Hologres兼容Postgres,Postgres的前、后端通信協議有extended協議與simple協議兩種:
1) simple協議:是一次性交互的協議,Client每次會直接發送待執行的SQL給Server,Server收到SQL后直接進行解析、執行,并將結果返回給Client。simple協議里Server無可避免的至少需要對收到的SQL進行解析才能理解其語義。
2)extended協議:Client與Server的交互分多階段完成,整體大致可以分成兩大階段。
- 第一階段:Client在Server端定義了一個帶名字的Statement,并且生成了該Statement所對應的generic plan(不與特定的參數綁定的通用plan)。

- 第二階段:用戶通過發送具體的參數來執行第一階段中定義的Statement。第二階段可以重復執行多次,每次通過帶上第一階段中所定義的Statement名字,以及執行所需要的參數,使用第一階段生成的generic plan進行執行。由于第二階段可以通過Statement名字和附帶的參數來反復執行第一個階段所準備好的generic plan,因此第二個段在Frontend的開銷幾乎等同于0。
為此Hologres基于Postgres的extended協議,支持了Prepared Statement,做到了Upsert Query在Frontend上的開銷接近于0。
2.高性能的內部通信
- Reactor模型、全程無鎖的異步操作
內部通信原理類似reactor模型,每個目標shard對應一個eventloop,以“死循環”的方式處理該shard上的請求。由于HOS(Hologres Operation System)對調度執行單元的抽象,即使是shard很多的情況下,這種工作方式的基礎消耗也足夠低。
- 高效的數據交換協議binary row
通過自定義一套內部的數據通信協議binary row來減少整個交互鏈路上的內存的分配與拷貝。
- 反壓與湊批
BHClient可以感知后端的壓力,進行自適應的反壓與湊批,在不影響原有Latency的情況下提升系統吞吐。
3.穩定可靠的后端實現
- 基于C++純異步的開發
Hologres采用C++進行開發,相較于Java,native語言使得我們能夠追求到更極致的性能。同時基于HOS提供的異步接口進行純異步開發,HOS通過抽象ExecutionContext來自我管理CPU的調度執行,能夠最大化的利用硬件資源、達到吞吐最大化。
- IO優化與豐富的Cache機制
Hologres實現了非常豐富的Cache機制row cache、block cache、iterator cache、meta cache等,來加速熱數據的查找、減少IO訪問、避免新內存分配。當無可避免的需要發生IO時,Hologres會對并發IO進行合并、通過wait/notice機制確保只訪問一次IO,減少IO處理量。通過生成文件級別的詞典及壓縮,減少文件物理存儲成本及IO訪問。
總結
Hologres是阿里巴巴自主研發的一站式實時數倉引擎,支持海量數據實時寫入、實時更新、實時分析,支持標準SQL(兼容PostgreSQL協議),支持PB級數據多維分析(OLAP)與即席分析(Ad Hoc),支持高并發低延遲的在線數據服務(Serving),并在阿里巴巴雙11等大促核心場景上,Hologres寫入峰值達11億條+/秒,經過大規模數據生產驗證。
常見的數據倉庫產品,大多都會犧牲讀性能或者犧牲寫性能,并且它們往往文件作為訪問介質,這天然約束了數據更新的頻率。Hologres 通過memtable使數據可以高頻更新,通過delete map讓讀操作避免了join操作保持了良好的讀性能,通過主鍵模型解決了寫操作時的效率問題,做到了讀寫性能的兼顧。同時Hologres同Flink、Spark等計算框架原生集成,通過內置Connector,支持高通量數據實時寫入與更新,支持源表、結果表、維度表多種場景,支持多流合并等復雜操作。?
從阿里集團誕生到云上商業化,隨著業務的發展和技術的演進,Hologres也在持續不斷優化核心技術競爭力,為了讓大家更加了解Hologres,我們計劃持續推出Hologres底層技術原理揭秘系列,從高性能存儲引擎到高效率查詢引擎,高吞吐寫入到高QPS查詢等,全方位解讀Hologres,請大家持續關注!