推薦系統中基于深度學習的混合協同過濾模型
近些年,深度學習在語音識別、圖像處理、自然語言處理等領域都取得了很大的突破與成就。相對來說,深度學習在推薦系統領域的研究與應用還處于早期階段。
攜程在深度學習與推薦系統結合的領域也進行了相關的研究與應用,并在國際人工智能***會議AAAI 2017上發表了相應的研究成果《A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems》,本文將分享深度學習在推薦系統上的應用,同時介紹攜程基礎BI團隊在這一領域上的實踐。
一、推薦系統介紹
推薦系統的功能是幫助用戶主動找到滿足其偏好的個性化物品并推薦給用戶。推薦系統的輸入數據可以多種多樣,歸納起來分為用戶(User)、物品(Item)和評分(Ratings)三個層面,它們分別對應于一個矩陣中的行、列、值。對于一個特定用戶,推薦系統的輸出為一個推薦列表,該列表按照偏好得分順序給出了該用戶可能感興趣的物品。

圖1. 推薦系統問題描述
如圖1右邊所示,推薦問題一個典型的形式化描述如下:我們擁有一個大型稀疏矩陣,該矩陣的每一行表示一個User,每一列表示一個Item,矩陣中每個“+”號表示該User對Item的Rating,(該分值可以是二值化分值,喜歡與不喜歡;也可以是0~5的分值等)。
現在需要解決的問題是:給定該矩陣之后,對于某一個User,向其推薦那些Rating缺失的Item(對應于矩陣中的“?”號)。有了如上的形式化描述之后,推薦系統要解決的問題歸結為兩部分,分別為預測(Prediction)與推薦(Recommendation)。
“預測”要解決的問題是推斷每一個User對每一個Item的偏愛程度,“推薦”要解決的問題是根據預測環節所計算的結果向用戶推薦他沒有打過分的Item。但目前絕大多數推薦算法都把精力集中在“預測”環節上,“推薦”環節則根據預測環節計算出的得分按照高低排序推薦給用戶,本次分享介紹的方案主要也是”預測”評分矩陣R中missing的評分值。
二、基于協同過濾的推薦
基于協同過濾的推薦通過收集用戶過去的行為以獲得其對物品的顯示或隱式信息,根據用戶對物品的偏好,發現物品或者用戶的相關性,然后基于這些關聯性進行推薦。
其主要可以分為兩類:分別是memory-based推薦與model-based推薦。其中memory-based推薦主要分為Item-based方法與User-based方法。協同過濾分類見圖2。

圖2. 協同過濾分類
Memory-based推薦方法通過執行最近鄰搜索,把每一個Item或者User看成一個向量,計算其他所有Item或者User與它的相似度。有了Item或者User之間的兩兩相似度之后,就可以進行預測與推薦了。

圖3. 矩陣分解示意圖
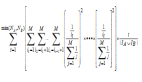
Model-based推薦最常見的方法為Matrix factorization,其示意圖見圖3左邊。矩陣分解通過把原始的評分矩陣R分解為兩個矩陣相乘,并且只考慮有評分的值,訓練時不考慮missing項的值,如圖3右邊所示。R矩陣分解成為U與V兩個矩陣后,評分矩陣R中missing的值就可以通過U矩陣中的某列和V矩陣的某行相乘得到。矩陣分解的目標函數見圖3,U矩陣與V矩陣的可以通過梯度下降(gradient descent)算法求得,通過交替更新u與v多次迭代收斂之后可求出U與V。
矩陣分解背后的核心思想,找到兩個矩陣,它們相乘之后得到的那個矩陣的值,與評分矩陣R中有值的位置中的值盡可能接近。這樣一來,分解出來的兩個矩陣相乘就盡可能還原了評分矩陣R,因為有值的地方,值都相差得盡可能地小,那么missing的值通過這樣的方式計算得到,比較符合趨勢。
協同過濾中主要存在如下兩個問題:稀疏性與冷啟動問題。已有的方案通常會通過引入多個不同的數據源或者輔助信息(Side information)來解決這些問題,用戶的Side information可以是用戶的基本個人信息、用戶畫像信息等,而Item的Side information可以是物品的content信息等。例如文獻[1]提出了一個Collective Matrix Factorization(CMF)模型,如圖4所示。

圖4. Collective Matrix Factorization模型
CMF模型通過分別分解評分矩陣R,User的side information矩陣,Item的side information矩陣,其中User或者Item出現在多個矩陣中,其所分解的隱向量都是一致的。
三、深度學習在推薦系統中的應用
Model-based方法的目的就是學習到User的隱向量矩陣U與Item的隱向量矩陣V。我們可以通過深度學習來學習這些抽象表示的隱向量。
Autoencoder(AE)是一個無監督學習模型,它利用反向傳播算法,讓模型的輸出等于輸入。文獻[2]利用AE來預測用戶對物品missing的評分值,該模型的輸入為評分矩陣R中的一行(User-based)或者一列(Item-based),其目標函數通過計算輸入與輸出的損失來優化模型,而R中missing的評分值通過模型的輸出來預測,進而為用戶做推薦,其模型如圖5所示。

圖5. Item-based AutoRec模型
Denoising Autoencoder(DAE)是在AE的基礎之上,對輸入的訓練數據加入噪聲。所以DAE必須學習去除這些噪聲而獲得真正的沒有被噪聲污染過的輸入數據。因此,這就迫使編碼器去學習輸入數據的更加魯棒的表達,通常DAE的泛化能力比一般的AE強。Stacked Denoising Autoencoder(SDAE)是一個多層的AE組成的神經網絡,其前一層自編碼器的輸出作為其后一層自編碼器的輸入,如圖6所示。

圖6. SDAE
文獻[3]在SDAE的基礎之上,提出了Bayesian SDAE模型,并利用該模型來學習Item的隱向量,其輸入為Item的Side information。該模型假設SDAE中的參數滿足高斯分布,同時假設User的隱向量也滿足高斯分布,進而利用概率矩陣分解來擬合原始評分矩陣。該模型通過***后驗估計(MAP)得到其要優化的目標函數,進而利用梯度下降學習模型參數,從而得到User與Item對應的隱向量矩陣。其圖模型如圖7所示。

圖7. Bayesian SDAE for Recommendation Sysytem
在已有工作的基礎之上,攜程基礎BI算法團隊通過改進現有的深度模型,提出了一種新的混合協同過濾模型,并將其成果投稿與國際人工智能***會議AAAI 2017并被接受。該成果通過利用User和Item的評分矩陣R以及對應的Side information來學習User和Item的隱向量矩陣U與V,進而預測出評分矩陣R中missing的值,并為用戶做物品推薦。
")
圖8. Additional Stacked Denoising Autoencoder(aSDAE)
該成果中提出了一種Additional Stacked Denoising Autoencoder(aSDAE)的深度模型用來學習User和Item的隱向量,該模型的輸入為User或者Item的評分值列表,每個隱層都會接受其對應的Side information信息的輸入(該模型靈感來自于NLP中的Seq-2-Seq模型,每層都會接受一個輸入,我們的模型中每層接受的輸入都是一樣的,因此最終的輸出也盡可能的與輸入相等),其模型圖見圖8。
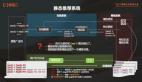
結合aSDAE與矩陣分解模型,我們提出了一種混合協同過濾模型,見圖9所示。該模型通過兩個aSDAE學習User與Item的隱向量,通過兩個學習到隱向量的內積去擬合原始評分矩陣R中存在的值,其目標函數由矩陣分解以及兩個aSDAE的損失函數組成,可通過stochastic gradient descent(SGD)學習出U與V,詳情大家可以閱讀我們的paper《A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems》[4]。

圖9. 混合協同過濾模型
我們利用RMSE以及RECALL兩個指標評估了我們模型的效果性能,并且在多個數據集上和已有的方案做了對比實驗。實驗效果圖如圖10所示,實驗具體詳情可參看我們的paper。

圖10. 實驗效果對比
在今年的推薦系統***會議RecSys上,Google利用DNN來做YouTube的視頻推薦[5],其模型圖如圖11所示。通過對用戶觀看的視頻,搜索的關鍵字做embedding,然后在串聯上用戶的side information等信息,作為DNN的輸入,利用一個多層的DNN學習出用戶的隱向量,然后在其上面加上一層softmax學習出Item的隱向量,進而即可為用戶做Top-N的推薦。

圖11. YouTube推薦模型圖
此外,文獻[6]通過卷積神經網絡(CNN)提出了一種卷積矩陣分解,來做文檔的推薦,該模型結合了概率矩陣分解(PMF)與CNN模型,圖見圖12所示。該模型利用CNN來學習Item的隱向量,其對文檔的每個詞先做embedding,然后拼接所有詞組成一個矩陣embedding矩陣,一篇文檔即可用一個二維矩陣表示,其中矩陣的行即為文檔中詞的個數,列即為embedding詞向量的長度,然后在該矩陣上做卷積、池化以及映射等,即可得到item的隱向量。User的隱向量和PMF中一樣,假設其滿足高斯分布,其目標函數由矩陣分解以及CNN的損失函數組成。

圖12. 卷積矩陣分解模型
四、總結
本文介紹了一些深度學習在推薦領域的應用,我們發現一些常見的深度模型(DNN, AE, CNN等)都可以應用于推薦系統中,但是針對不同領域的推薦,我們需要更多的高效的模型。隨著深度學習技術的發展,我們相信深度學習將會成為推薦系統領域中一項非常重要的技術手段。
本文由攜程技術中心投遞,ID:ctriptech。作者:董鑫,攜程基礎業務部BI團隊高級算法工程師,博士畢業于上海交通大學計算機科學與技術系。