億級異構任務調度框架設計與實踐
一、背景
阿里云日志服務作為云原生可觀測與分析平臺。提供了一站式的數據采集、加工、查詢分析、可視化、告警、消費與投遞等功能。全面提升用戶的研發、運維、運營、安全場景的數字化能力。
日志服務平臺作為可觀測性平臺提供了數據導入、數據加工、聚集加工、告警、智能巡檢、導出等功能,這些功能在日志服務被稱為任務,并且具有大規模的應用,接下來主要介紹下這些任務的調度框架的設計與實踐。

本次介紹主要分為四個部分:
- 任務調度背景
- 可觀測性平臺的億級任務調度框架設計
- 任務調度框架在日志服務的大規模應用
- 展望
任務調度背景
通用調度
調度在計算機里面是一個非常常見的技術,從單機到分布式再到大數據系統,調度的身影無處不在。這里嘗試總結出調度的一些共同特征。
- 操作系統:從單機操作系統Linux來看,內核通過時間片的方式來控制進程在處理器上的執行時間,進程的優先級與時間片掛鉤,簡單來說,進程的在單CPU或者某個CPU的執行由調度器來掌握;K8s被稱為分布式時代的操作系統,在Pod創建后,K8s的控制面調度器通過對節點進行打分排序,最終選出適合的Node來運行Pod。
- 大數據分析系統:從最早的MapReduce使用公平調度器支持作業的優先級和搶占,到SQL計算引擎Presto通過Coordinator的調度器將執行計劃中的任務分配到適合的worker上來執行,Spark通過DAGScheduler拆分成Stage,TaskScheduler將Stage對應的TaskSet最終調度到適合的Worker上來執行。
- 任務調度框架:在數據處理中常見的ETL處理任務、定時任務,這些任務具有多模的特點:定時執行、持續運行、一次性執行等。在任務執行過程中需要考慮任務的編排和狀態一致性問題。

這里簡單的對調度做一個抽象,如上圖所示,調度負責將不同的Task分配到不同的Resource上執行,Task可以是進程、Pod、子任務;Resource為具體執行Task任務的資源,可以是處理器、線程池、節點、機器。通過這個抽象,可以看出調度在系統中的位置。
調度的覆蓋面很廣,本文主要集中在任務調度框架的設計與實踐,這里先通過一些例子來看下任務調度的一些特點,以下主要講任務分為定時類的任務和依賴類的任務兩種來展開。
任務調度
定時類任務

定時執行可以理解為每個任務之間有時間先后順序,并且要在特定的時間點執行,比如每隔1小時對日志進行監控,00點的監控任務需要首先執行,01點的監控任務需要在01點準時執行;同樣,類似的定時場景,還有儀表盤訂閱、定時計算等。
?依賴類任務

除了定時執行,還有另外一種編排形式,比如順序依賴,各個任務之間有先后執行的依賴,也叫Pipeline方式,還有一種比較常見的編排形式,拓撲依賴,也稱為DAG,比如Task2/Task3需要等到Task1執行完成才可以執行,Task5需要等到Task3/Task4執行完才可以執行。
?任務調度特點
任務調度在執行的過程中需要盡可能均衡的將任務分派到合適的機器或者執行器上去執行,比如要根據執行器的當前負載情況,要根據任務自身的特征進行分派執行;在執行器執行的過程中也可能會崩潰,退出,這時候需要將任務遷移到其他的執行器中。整個調度過程需要考慮到調度策略、FailOver、任務遷移等。接下來來看下任務調度的一個簡單應用。
任務調度應用:一條日志的歷險

上圖中原始日志為一條Nginx訪問日志,其中包括IP、時間、Method、URL、UserAgent等信息,這樣一些原始日志并不利于我們進行分析,比如我們想統計訪問最高的Top 10 URL,通過命令處理是這樣的:
cat nginx_access.log |awk '{print $7}'| sort|uniq -c| sort -rn| head -10 | more拋開命令的復雜性和原始日志的數據量不談,即使需求稍微變化,命令就需要大量的改動,非常不利于維護,對日志進行分析的正確方式必然是使用分布式日志平臺進行日志分析,原始日志蘊含著大量“信息”,但是這些信息的提取是需要一系列的流程。
首先是數據采集、需要通過Agent對分布在各個機器上的數據進行集中采集到日志平臺,日志采集上來后需要進行清洗,比如對于Nginx訪問日志使用正則提取,將時間、Method、URL等重要信息提取出來作為字段進行存儲并進行索引構建,通過索引,我們可以使用類SQL的分析語法對日志進行分析、例如查看訪問的Top 10 URL,用SQL來表達就會非常簡潔清晰:
select url, count(1) as cnt from log group by url order by cnt desc limit 10
業務系統只要在服務,日志就會不斷產生,可以通過對流式的日志進行巡檢,來達到系統異常的檢測目的,當異常發生時,我們可以通過告警通知到系統運維人員。
?通用流程提取
從這樣一個日志分析系統可以提取出一些通用的流程,這些通用的流程可以概括為數據攝入、數據處理、數據監測、數據導出。
除了日志,系統還有Trace數據、Metric數據,它們是可觀測性系統的三大支柱。這個流程也適用于可觀測性服務平臺,接下來來看下一個典型的可觀測服務平臺的流程構成。
?典型可觀測服務平臺數據流程

- 數據攝入:在可觀測服務平臺首先需要擴展數據來源,數據源可能包括各類日志、消息隊列Kafka、存儲OSS、云監控數據等,也可以包括各類數據庫數據,通過豐富數據源的攝入,可以對系統有全方位的觀測。
- 數據處理:在數據攝入到平臺后,需要對數據進行清洗、加工,這個過程我們把他統稱數據處理,數據加工可以理解為數據的各種變換和富華等,聚集加工支持對數據進行定時rolling up操作,比如每天計算過去一天匯總數據,提供信息密度更高的數據。
- 數據監測:可觀測性數據本身反應了系統的運行狀態,系統通過對每個組件暴露特定的指標來暴露組件的健康程度,可以通過智能巡檢算法對異常的指標進行監控,比如QPS或者Latency的陡增或陡降,當出現異常時可以通過告警通知給相關運維人員,在指標的基礎上可以做出各種運維或者運營的大盤,在每天定時發送大盤到群里也是一種場景的需求。
- 數據導出:可觀測性數據的價值往往隨著時間產生衰減,那么對于長時間的日志類數據出于留檔的目的可以進行導出到其他平臺。
從以上四個過程我們可以抽象出各類任務,分別負責攝入、處理、檢測等,比如數據加工是一種常駐任務,需要持續對數據流進行處理,儀表盤訂閱是一種定時任務,需要定時發出儀表盤到郵件或者工作群中。接下來將要介紹對各類任務的調度框架。
可觀測性平臺的億級任務調度框架設計可觀測平臺任務特點
根據上面對可觀測平臺任務的介紹,可以總結一個典型的可觀測平臺的任務的特點:
- 業務復雜,任務類型多:數據攝入,僅數據攝入單個流程涉及數據源可能有幾十上百個之多。
- 用戶量大,任務數數量多:由于是云上業務,每個客戶都有大量的任務創建需求。
- SLA要求高:服務可用性要求高,后臺服務是升級、遷移不能影響用戶已有任務的運行。
- 多租戶:云上業務客戶相互直接不能有影響。?
可觀測平臺任務調度設計目標

根據平臺任務的特點,對于其調度框架,我們需要達到上圖中的目標
- 支持異構任務:告警、儀表盤訂閱、數據加工、聚集加工每種任務的特點不一樣,比如告警是定時類任務、數據加工是常駐類任務,儀表盤訂閱預覽是一次性任務。
- 海量任務調度:對于單個告警任務,假如每分鐘執行一次,一天就會有1440次調度,這個數量乘以用戶數再乘以任務數,將是海量的任務調度;我們需要達到的目標是任務數的增加不會對打爆機器的性能,特別是要做到水平擴縮容,任務數或者調度次數增加只需要線性增加機器即可。
- 高可用:作為云上業務,需要達到后臺服務升級或者重啟、甚至宕機對用戶任務運行無影響的目的,在用戶層面和后臺服務層面都需要具有任務運行的監控能力。
- 簡單高效的運維:對于后臺服務需要提供可視化的運維大盤,可以直觀的展示服務的問題;同時也要對服務進行告警配置,在服務升級、發布過程中可以盡量無人值守。
- 多租戶:云上環境是天然有多租戶場景,各個租戶之間資源要做到嚴格隔離,相互之間不能有資源依賴、性能依賴。
- 可擴展性:面對客戶的新增需求,未來需要支持更多的任務類型,比如已經有了MySQL、SqlServer的導入任務,在未來需要更多其他的數據庫導入,這種情況下,我們需要做到不修改任務調度框架,只需要修改插件即可完成。
- API化:除了以上的需求,我們還需要做到任務的API化管控,對于云上用戶,很多海外客戶是使用API、Terraform來對云上資源做管控,所以要做到任務管理的API化。?
可觀測平臺任務調度框架總體概覽

基于上述的調度設計目標,我們設計了可觀測性任務調度框架,如上圖所示,下面從下到上來介紹。
- 存儲層:主要包括任務的元數據存儲和任務運行時的狀態和快照存儲。任務的元數據主要包括任務類型,任務配置、任務調度信息,都存儲在了關系型數據庫;任務的運行狀態、快照存儲在了分布式文件系統中。
- 服務層:提供了任務調度的核心功能,主要包括任務調度和任務執行兩部分,分別對應前面講的任務編排和任務執行模塊。任務調度主要針對三種任務類型進行調度,包括常駐任務、定時任務、按需任務。任務執行支持多種執行引擎,包括presto、restful接口、K8s引擎和內部自研的ETL 2.0系統。
- 業務層:業務層包括用戶直接在控制臺可以使用到的功能,包括告警監控、數據加工、重建索引、儀表盤訂閱、聚集加工、各類數據源導入、智能巡檢任務、和日志投遞等。
- 接入層:接入層使用Nginx和CGI對外提供服務,具有高可用,地域化部署等特性。
- API/SDK/Terraform/控制臺:在用戶側,可以使用控制臺對各類任務進行管理,對于不同的任務提供了定制化的界面和監控,同時也可以使用API、SDK、Terraform對任務進行增刪改查。
- 任務可視化:在控制臺我們提供了任務執行的可視化和任務監控的可視化,通過控制臺用戶可以看出看到任務的執行狀態、執行歷史等,還可以開啟內置告警對任務進行監控。
任務調度框架設計要點
接下來從幾方面對任務調度框的設計要點進行介紹,主要包括以下幾方面來介紹:
- 異構任務模型抽象
- 調度服務框架
- 大規模任務支持
- 服務高可用設計
- 穩定性建設
任務模型抽象

接下來看下任務模型的抽象:
- 對于告警監控、儀表盤訂閱、聚集加工等需要定時執行的任務,抽象為定時任務,支持定時和Cron表達式設置。
- 對于數據加工、索引重建、數據導入等需要持續運行的任務,抽象為常駐任務,這類任務往往只需要運行一次,可以有也可以沒有結束狀態。
- 對于數據加工的預覽、儀表盤訂閱的預覽等功能,是在用戶點擊時才會需要創建一個任務來執行,執行完成即可退出,不需要保存任務狀態,這類任務抽象為DryRun類型,或者按需任務。
調度服務框架

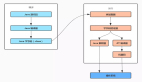
服務基礎框架使用了Master-Worker架構,Master負責任務的分派和Worker的管控,Master將數據抽象為若干Partitions,然后將這些Partitions分派給不同的Worker,實現了對任務的分而治之,在Worker執行的過程中Master還也可以根據Worker的負載進行Partitions的動態遷移,同時在Worker重啟升級過程中,Master也會對Partition進行移出和移入;
任務的調度主要在Worker層來實現,每個Worker負責拉取對應Partitions的任務,然后通過JobLoader對任務進行加載,注意:這里只會加載當前Worker對應Partitions的任務列表,然后Scheduler對任務進行調度的編排,這里會涉及常駐任務、定時任務、按需任務的調度,Scheduler將編排好的任務發送到JobExecutor進行執行,JobExecutor在執行的過程中需要實時對任務的狀態進行持久化保存到RedoLog中,在下次Worker升級重新啟動的過程中,需要從RedoLog中加載任務的狀態,從而保證任務狀態的準確性。
?大規模任務支持

通過任務服務框架的介紹,我們知道Partitions是Master與Worker溝通的橋梁,也是對大規模任務進行分而治之的介質。如上圖所示,假設有N個任務,按照一定的哈希算法將N個任務映射到對應的Partition,因為Worker關聯特定的Partition,這樣Worker就可以跟任務關聯起來,比如任務j1、j2對應的partition是p1,而p1對應的Worker是worker1,這樣j1、j2就可以在worker1上執行。需要說明的如下:
- Worker與Partition的對應關系并非一成不變,是一個動態的映射,在Worker重啟或者負載較高時,其對應的Partition會遷移到其他的Worker上,所以Worker需要實現Partition的移入和移出操作。
- 任務數量增加的時候,因為有Partition這個中間層,只需要增加Worker的數量就可以滿足任務增長時的需求,達到水平擴展的目的。增加新Worker后,可以分擔更多的Partition
服務高可用設計
服務的高可用主要是服務的可用性時間,作為后臺服務肯定有重啟、升級的需求,高可用場景主要涉及到Partition遷移的處理,在Worker重啟、Worker負載較高時、Worker異常時,都會有Partition遷移的需求,在Partition遷移的過程中,任務也需要進行遷移,任務的遷移就涉及到狀態的保留,類似CPU上進程的航線文切換。

對于任務的切換,我們使用了RedoLog的方式來保存任務的狀態,一個任務可以被分為多個階段,對應任務執行的狀態機,在每個階段執行時都對其進行內存Checkpoint的更新和RedoLog的更新,RedoLog是持久化到之前提到的分布式文件系統中,使用高性能的Append的方式進行順序寫入,在Partition遷移到新的Worker后,新的Worker在對RedoLog進行加載,就可以完成任務狀態的恢復。
這里涉及一個優化,RedoLog如果一直使用Append的方式進行寫入,勢必會造成RedoLog越來越膨脹,也會造成Worker加載Partition時速度變慢,對于這種情況,我們使用了Snapshot的方式,將過去一段時間的RedoLog進行合并,這樣只需要在加載Partition時,加載Snapshot和Snaphost之后的RedoLog就可以減少文件讀取的次數和開銷,提高加載速度。
穩定性建設
穩定性建設主要涉及以下幾方面內容:
- 發布流程:
- 從編譯到發布全Web端白屏化操作,模板化發布,每個版本都可跟蹤、回退。
- 支持集群粒度、任務類型粒度的灰度控制,在發布時可以進行小范圍驗證,然后全量發布。
- 運維流程:
- 提供內部運維API、Web端操作,對于異常Job進行修復、處理。減少人工介入運維。
- On-Call:
- 在服務內部,我們開發了內部巡檢功能,查找異常任務,例如某些任務啟動時間過長、停止時間過長都會打印異常日志,可以對異常日志進行跟蹤和監控。
- 通過異常日志,使用日志服務告警進行監控,出現問題可以及時通知運維人員。
- 任務監控:
- 用戶側:在控制臺我們針對各類任務提供了監控儀表盤和內置告警配置。
- 服務側:在后臺,可以看到集群粒度任務的運行狀態,便于后臺運維人員進行服務的監控。
- 同時,對于任務的執行狀態和歷史都會存入特定的日志庫中,以便出現問題時進行追溯和診斷。
下面是一些服務側的部分大盤示例,展示的是告警的一些執行狀態。

下面是用戶側的任務監控狀態和告警的展示。


大規模應用
在日志服務,任務的調度已經有了大規模的應用,下面是某地域單集群的任務的運行狀態,因為告警是定時執行且使用場景廣泛,其單日調度次數達到了千萬級別,聚集加工在Rolling up場景中有很高場景的應用,也達到了百萬級別;對于數據加工任務因為是常駐任務,調度頻率低于類似告警類的定時任務。
接下來以一個聚集加工為例來看下任務的調度場景。
典型任務:聚集加工

聚集加工是通過定時對一段時間的數據進行聚集查詢,然后將結果存入到另一個庫中,從而將高信息密度的信息進行提取,相對于原始數據具有降維、低存儲、高信息密度的特點。適合于定時分析、全局聚合的場景。

這里是一個聚集加工的執行狀態示例,可以看到每個時間區間的執行情況,包括處理行數、處理數據量、處理結果情況,對于執行失敗的任務,還可以進行手動重試。
對于聚集加工并非定時執行這么簡單的邏輯,在過程中需要處理超時、失敗、延遲等場景,接下來對每種場景進行一個簡單介紹。
?調度場景一:實例延遲執行
無論實例是否延遲執行,實例的調度時間都是根據調度規則預先生成的。雖然前面的實例發生延遲時,可能導致后面的實例也延遲執行,但通過追趕執行進度,可逐漸減少延遲,直到恢復準時運行。

調度場景二:從某個歷史時間點開始執行聚集加工作業
在當前時間點創建聚集加工作業后,按照調度規則對歷史數據進行處理,從調度的開始時間創建補運行的實例,補運行的實例依次執行直到追上數據處理進度后,再按照預定計劃執行新實例。 
調度場景三:固定時間內執行聚集加工作業
如果需要對指定時間段的日志做調度,則可設置調度的時間范圍。如果設置了調度的結束時間,則最后一個實例(調度時間小于調度結束時間)執行完成后,不再產生新的實例。

調度場景四:修改調度配置對生成實例的影響
修改調度配置后,下一個實例按照新配置生成。一般建議同步修改SQL時間窗口、調度頻率等配置,使得實例之間的SQL時間范圍可以連續。

調度場景五:重試失敗的實例
- 自動重試
- 如果實例執行失敗(例如權限不足、源庫不存在、目標庫不存在、SQL語法不合法),系統支持自動重試
- 手動重試
- 當重試次數超過您配置的最大重試次數或重試時間超過您配置的最大運行時間時,重試結束,該實例狀態被置為失敗,然后系統繼續執行下一個實例。
展望
- 動態任務類型:增加對于動態任務類型的支持,例如更復雜的具有任務間依賴關系的任務調度。
- 多租戶優化:目前對于任務使用簡單的Quota限制,未來對多租戶的QoS進行的進一步細化,以支持更大的Quota設置。
- API優化、完善:目前的任務類型也在快速更新中,任務API的迭代速度還有些差距,需要增強任務API的優化,達到增加一種任務類型,不需要修改或者少量更新API的目的。