













初探自然語(yǔ)言預(yù)訓(xùn)練技術(shù)演進(jìn)之路
精選人工智能的三個(gè)層次:
運(yùn)算職能:數(shù)據(jù)的存儲(chǔ)和計(jì)算能力,機(jī)器遠(yuǎn)勝于人類。
感知職能:視覺、聽覺等能力,機(jī)器在語(yǔ)音識(shí)別、圖像識(shí)別領(lǐng)域已經(jīng)比肩人類。
認(rèn)知智能:自然語(yǔ)言處理、常識(shí)建模與推理等任務(wù),機(jī)器還有很長(zhǎng)的路要走。
自然語(yǔ)言處理屬于認(rèn)知智能范疇,由于自然語(yǔ)言具有抽象性、組合性、歧義性、知識(shí)性、演化性等特點(diǎn),為機(jī)器處理帶來(lái)了極大的挑戰(zhàn),有人將自然語(yǔ)言處理稱為人工智能皇冠上的明珠。近些年來(lái),出現(xiàn)了以 BERT 為代表的預(yù)訓(xùn)練語(yǔ)言模型,將自然語(yǔ)言處理帶入了一個(gè)新紀(jì)元:預(yù)訓(xùn)練語(yǔ)言模型 + 特定任務(wù)精調(diào)。本文試圖梳理自然語(yǔ)言預(yù)訓(xùn)練技術(shù)的演進(jìn)之路,以期和大家相互交流學(xué)習(xí),不足、謬誤之處望批評(píng)指正。
1.古代 - 詞表示
1.1 One-hot Encoding
用一個(gè)詞表大小的向量表示一個(gè)詞,其中詞對(duì)應(yīng)位置的值為1,其余位置為0。缺點(diǎn):
- 高維稀疏性
- 無(wú)法表示語(yǔ)義相似性:兩個(gè)同義詞的 One-hot 向量相似度為0
1.2 分布式表示
分布式語(yǔ)義假設(shè):相似的詞具有相似的上下文,詞的語(yǔ)義可由上下文表示。基于該思想,可以利用每個(gè)詞的上下文分布對(duì)詞進(jìn)行表示。
1.2.1 詞頻表示
基于語(yǔ)料庫(kù),利用詞的上下文構(gòu)建共現(xiàn)頻次表,詞表的每一行代表了一個(gè)詞的向量表示。通過(guò)不同的上下文選擇可以捕獲到不同的語(yǔ)言信息,如用句子中詞的周圍固定窗口的詞作為上下文,會(huì)更多的捕捉到詞的局部信息:詞法、句法信息,若用所在文檔作為上下文,更多的捕捉到詞所表示的主題信息。缺點(diǎn):
- 高頻詞問(wèn)題。
- 無(wú)法反應(yīng)高階關(guān)系:(A, B) (B, C) (C, D) !=> (A, D)。
- 依然存在稀疏性問(wèn)題。
1.2.2 TF-IDF表示
將詞頻表示中的值,替換為 TF-IDF,主要緩解詞頻表示的高頻詞問(wèn)題。
1.2.3 點(diǎn)互信息表示
同樣是緩解詞頻表示的高頻詞問(wèn)題,將詞頻表示中的值替換為詞的點(diǎn)互信息:

1.2.4 LSA
通過(guò)對(duì)詞頻矩陣進(jìn)行奇異值分解 (Singular Value Decomposition,SVD),可以得到每個(gè)詞的低維、連續(xù)、稠密的向量表示,可認(rèn)為表示了詞的潛在語(yǔ)義,該方法也被稱為潛在語(yǔ)義分析 (Latent Semantic Analysis, LSA)。

LSA 緩解了高頻詞、高階關(guān)系、稀疏性等問(wèn)題,在傳統(tǒng)機(jī)器學(xué)習(xí)算法中效果還是不錯(cuò)的,但是也存在一些不足:
- 詞表大時(shí),SVD 速度比較慢。
- 無(wú)法追新,當(dāng)語(yǔ)料變化或新增語(yǔ)料時(shí),需要重新訓(xùn)練。
2. 近代——靜態(tài)詞向量
文本的有序性及詞與詞之間的共現(xiàn)關(guān)系為自然語(yǔ)言處理提供了天然的自監(jiān)督學(xué)習(xí)信號(hào),使得系統(tǒng)無(wú)需額外的人工標(biāo)注也能夠從文本中學(xué)到知識(shí)。
2.1 Word2Vec
2.1.1 CBOW
CBOW(Continous Bag-of-Words) 利用上下文(窗口)對(duì)目標(biāo)詞進(jìn)行預(yù)測(cè),將上下文的詞的詞向量取算術(shù)平均,然后預(yù)測(cè)目標(biāo)詞的概率。

2.1.2 Skip-gram
Skip-gram 通過(guò)詞預(yù)測(cè)上下文。

2.2 GloVe
GloVe(Global Vectors for Word Representation) 利用詞向量對(duì)詞的共現(xiàn)矩陣進(jìn)行預(yù)測(cè),實(shí)現(xiàn)了隱式的矩陣分解。首先根據(jù)詞的上下文窗口構(gòu)建距離加權(quán)的共現(xiàn)矩陣 X,再利用詞與上下文的向量對(duì)共現(xiàn)矩陣 X 進(jìn)行擬合:

損失函數(shù)為:

2.3 小結(jié)
詞向量的學(xué)習(xí)利用了語(yǔ)料庫(kù)中詞與詞之間的共現(xiàn)信息,底層思想還是分布式語(yǔ)義假設(shè)。無(wú)論是基于局部上下文的 Word2Vec,還是基于顯式全局共現(xiàn)信息的 GloVe,本質(zhì)都是將一個(gè)詞在整個(gè)語(yǔ)料庫(kù)中的共現(xiàn)上下文信息聚合到該詞的向量表示中,并都取得了不錯(cuò)的效果,訓(xùn)練速度也很快,但是缺點(diǎn)詞的向量是靜態(tài)的,即不具備隨上下文變化而變化的能力。
3. 現(xiàn)代——預(yù)訓(xùn)練語(yǔ)言模型
自回歸語(yǔ)言模型:根據(jù)序列歷史計(jì)算當(dāng)前時(shí)刻詞的條件概率。

自編碼語(yǔ)言模型:通過(guò)上下文重構(gòu)被掩碼的單詞。

表示被掩碼的序列
3.1 基石——Transformer

3.1.1 注意力模型
注意力模型可以理解為對(duì)一個(gè)向量序列進(jìn)行加權(quán)操作的機(jī)制,權(quán)重的計(jì)算。

3.1.2 多頭自注意力
Transformer 中使用的注意力模型可以表示為:

當(dāng) Q、K、V 來(lái)自同一向量序列時(shí),成為自注意力模型。
多頭自注意力:設(shè)置多組自注意力模型,將其輸出向量拼接,并通過(guò)一個(gè)線性映射映射到 Transformer 隱層的維度大小。多頭自注意力模型,可以理解為多個(gè)自注意力模型的 ensemble。


3.1.3 位置編碼
由于自注意力模型沒有考慮輸入向量的位置信息,但位置信息對(duì)序列建模至關(guān)重要。可以通過(guò)位置嵌入或位置編碼的方式引入位置信息,Transformer 里使用了位置編碼的方式。

3.1.4 其他
此外 Transformer block 里還使用了殘差連接、Layer Normalization 等技術(shù)。
3.1.5優(yōu)缺點(diǎn)
優(yōu)點(diǎn):
- 相比 RNN 能建模更遠(yuǎn)距離的依賴關(guān)系,attention 機(jī)制將詞與詞之間的距離縮小為了1,從而對(duì)長(zhǎng)序列數(shù)據(jù)建模能力更強(qiáng)。
- 相比 RNN 能更好的利用 GPU 并行計(jì)算能力。
- 表達(dá)能力強(qiáng)。
缺點(diǎn):
- 相比 RNN 參數(shù)大,增加了訓(xùn)練難度,需要更多的訓(xùn)練數(shù)據(jù)。
3.2 自回歸語(yǔ)言模型
3.2.1 ELMo
ELMo: Embeddings from Language Models
輸入層
對(duì)詞可以直接用詞的 embedding,也可以對(duì)詞中的字符序列通過(guò) CNN,或其他模型。

模型結(jié)構(gòu)

ELMo 通過(guò) LSTM 獨(dú)立的建模前向、后向語(yǔ)言模型,前向語(yǔ)言模型:

后向語(yǔ)言模型:

優(yōu)化目標(biāo)
最大化:

下游應(yīng)用
ELMo 訓(xùn)練好后,可以得到如下向量供下游任務(wù)使用。

是輸入層得到的 word embedding, 是前、后向 LSTM 輸出拼接的結(jié)果。
下游任務(wù)使用時(shí),可以加各層向量加權(quán)得到 ELMo 的一個(gè)向量表示,同時(shí)用一個(gè)權(quán)重對(duì) ELMo 向量進(jìn)行縮放。

不同層次的隱含層向量蘊(yùn)含了不同層次或粒度的文本信息:
- 頂層編碼了更多的語(yǔ)義信息
- 底層編碼了更多的詞法、句法信息
3.2.2 GPT 系列
GPT-1
模型結(jié)構(gòu)
在 GPT-1(Generative Pre-Training),是一個(gè)單向的語(yǔ)言模型,使用了12個(gè) transformer block 結(jié)構(gòu)作為解碼器,每個(gè) transformer 塊是一個(gè)多頭的自注意力機(jī)制,然后通過(guò)全連接得到輸出的概率分布。


- U: 詞的獨(dú)熱向量
- We:詞向量矩陣
- Wp:位置向量矩陣
優(yōu)化目標(biāo)
最大化:

下游應(yīng)用
下游任務(wù)中,對(duì)于一個(gè)有標(biāo)簽的數(shù)據(jù)集 ,每個(gè)實(shí)例有個(gè)輸入 token:,它對(duì)于的標(biāo)簽組成。首先將這些 token 輸入到訓(xùn)練好的預(yù)訓(xùn)練模型中,得到最終的特征向量。然后再通過(guò)一個(gè)全連接層得到預(yù)測(cè)結(jié)果:

下游有監(jiān)督任務(wù)的目標(biāo)則是最大化:

為了防止災(zāi)難性遺忘問(wèn)題,可以在精調(diào)損失中加入一定權(quán)重的預(yù)訓(xùn)練損失,通常預(yù)訓(xùn)練損失。


GPT-2
GPT-2 的核心思想概括為:任何有監(jiān)督任務(wù)都是語(yǔ)言模型的一個(gè)子集,當(dāng)模型的容量非常大且數(shù)據(jù)量足夠豐富時(shí),僅僅靠訓(xùn)練語(yǔ)言模型的學(xué)習(xí)便可以完成其他有監(jiān)督學(xué)習(xí)的任務(wù)。所以 GPT-2 并沒有對(duì) GPT-1 的網(wǎng)絡(luò)進(jìn)行過(guò)多的結(jié)構(gòu)的創(chuàng)新與設(shè)計(jì),只是使用了更多的網(wǎng)絡(luò)參數(shù)和更大的數(shù)據(jù)集,目標(biāo)旨在訓(xùn)練一個(gè)泛化能力更強(qiáng)的詞向量模型。
在8個(gè)語(yǔ)言模型任務(wù)中,僅僅通過(guò) zero-shot 學(xué)習(xí),GPT-2 就有7個(gè)超過(guò)了當(dāng)時(shí) state-of-the-art 的方法(當(dāng)然好些任務(wù)上還是不如監(jiān)督模型效果好)。GPT-2 的最大貢獻(xiàn)是驗(yàn)證了通過(guò)海量數(shù)據(jù)和大量參數(shù)訓(xùn)練出來(lái)的詞向量模型有遷移到其它類別任務(wù)中而不需要額外的訓(xùn)練。
同時(shí) GPT-2 表明隨著模型容量和訓(xùn)練數(shù)據(jù)量(質(zhì)量)的增大,其潛能還有進(jìn)一步開發(fā)的空間,基于這個(gè)思想,誕生了 GPT-3。
GPT-3
依舊模型結(jié)構(gòu)沒啥變化,增加模型容量、訓(xùn)練數(shù)據(jù)量及質(zhì)量,號(hào)稱巨無(wú)霸,效果也很好。
小結(jié)

從 GPT-1 到 GPT-3,隨著模型容量和訓(xùn)練數(shù)據(jù)量的增加,模型學(xué)到的語(yǔ)言知識(shí)也越豐富,自然語(yǔ)言處理的范式也從「預(yù)訓(xùn)練模型+精調(diào)」逐步向「預(yù)訓(xùn)練模型 + zero-shot/few-shot learning」轉(zhuǎn)變。GPT 的缺點(diǎn)是用的單向語(yǔ)言模型,BERT 已經(jīng)證明了雙向語(yǔ)言模型能提升模型效果。
3.2.3 XLNet
XLNet 通過(guò)排列語(yǔ)言模型 (Permutation Language Model) 引入了雙向的上下文信息,不引入特殊的 tag,避免了預(yù)訓(xùn)練和精調(diào)階段 token 分布不一致的問(wèn)題。同時(shí)使用 Transformer-XL 作為模型主體結(jié)構(gòu),對(duì)長(zhǎng)文本有更好的效果。
排列語(yǔ)言模型
排列語(yǔ)言模型的目標(biāo)是:

是文本序列所有可能的排列集合。
雙流自注意力機(jī)制
- 雙流自注意力機(jī)制 (Two-stream Self-attention)要達(dá)到的目的:通過(guò)改造Transformer,在輸入正常文本序列的情況下,實(shí)現(xiàn)排列語(yǔ)言模型:
- 內(nèi)容表示:包含的信息
- 查詢表示:只包含的信息


該方法使用了預(yù)測(cè)詞的位置信息。
下游應(yīng)用
下游任務(wù)應(yīng)用時(shí),不需要查詢表示,也不 mask。
3.3 自編碼語(yǔ)言模型
3.3.1 BERT
掩碼語(yǔ)言模型
掩碼語(yǔ)言模型(masked language model, MLM),隨機(jī)地屏蔽部分詞,然后利用上下文信息進(jìn)行預(yù)測(cè)。MLM 存在個(gè)問(wèn)題,預(yù)訓(xùn)練和 fine-tuning 之間不匹配,因?yàn)樵?fine-tuning 期間從未看到 [MASK] token。為了解決這個(gè)問(wèn)題,BERT 并不總是用實(shí)際的 [MASK] token 替換被「masked」的 word piece token。訓(xùn)練數(shù)據(jù)生成器隨機(jī)選擇15%的 token,然后:
- 80%的概率:用 [MASK] 標(biāo)記替換。
- 10%的概率:從詞表隨機(jī)一個(gè) token 替換。
- 10%的概率:token 保持不變。
原生 BERT 里對(duì) token 進(jìn)行 mask,可以對(duì)整詞或短語(yǔ)(N-Gram)進(jìn)行 mask。
下一句預(yù)測(cè)
下一句預(yù)測(cè)(NSP):當(dāng)選擇句子 A 和 B 作為預(yù)訓(xùn)練樣本時(shí),B 有50%的可能是 A 的下一個(gè)句子,也有50%的可能是來(lái)自語(yǔ)料庫(kù)的隨機(jī)句子。
輸入層

模型結(jié)構(gòu)

經(jīng)典的「預(yù)訓(xùn)練模型+精調(diào)」的范式,主題結(jié)構(gòu)是堆疊的多層 Transformer。
3.3.2 RoBERTa
RoBERTa(Robustly Optimized BERT Pretraining Approach) 并沒有大刀闊斧的改進(jìn) BERT,而只是針對(duì) BERT 的每一個(gè)設(shè)計(jì)細(xì)節(jié)進(jìn)行了詳盡的實(shí)驗(yàn)找到了 BERT 的改進(jìn)空間。
- 動(dòng)態(tài)掩碼:原始方式是構(gòu)建數(shù)據(jù)集的時(shí)候設(shè)置好掩碼并固定,改進(jìn)方式是每輪訓(xùn)練將數(shù)據(jù)輸入模型的時(shí)候才進(jìn)行隨機(jī)掩碼,增加了數(shù)據(jù)的多樣性。
- 舍棄 NSP 任務(wù):通過(guò)實(shí)驗(yàn)證明不使用 NSP 任務(wù)對(duì)大多數(shù)任務(wù)都能提升性能。
- 更多訓(xùn)練數(shù)據(jù),更大批次,更長(zhǎng)的預(yù)訓(xùn)練步數(shù)。
- 更大的詞表:使用 SentencePiece 這種字節(jié)級(jí)別的 BPE 詞表而不是 WordPiece 字符級(jí)別的 BPE 詞表,幾乎不會(huì)出現(xiàn)未登錄詞的情況。
3.3.3 ALBERT
BERT 參數(shù)量相對(duì)較大,ALBERT(A Lite BERT) 主要目標(biāo)是減少參數(shù):
- BERT 的詞向量維度和隱含層維度相同,詞向量上下文無(wú)關(guān),而BERT 的 Transformer 層需要并且可以學(xué)習(xí)充分的上下文信息,因此隱含層向量維度應(yīng)遠(yuǎn)大于詞向量維度。當(dāng)增大提高性能時(shí),沒有必要跟著變大,因?yàn)樵~向量空間對(duì)需要嵌入的信息量可能已經(jīng)足夠。
- 方案:,詞向量通過(guò)全連接層變換為H維。
- 詞向量參數(shù)分解(Factorized embedding parameterization)。
- 跨層參數(shù)共享(Cross-layer parameter sharing):不同層的Transformer block 共享參數(shù)。
- 句子順序預(yù)測(cè)(sentence-order prediction, SOP),學(xué)習(xí)細(xì)微的語(yǔ)義差別及語(yǔ)篇連貫性。
3.4 生成式對(duì)抗 - ELECTRA
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately) 引入了生成器和判別器的模式,把生成式的 Masked language model(MLM) 預(yù)訓(xùn)練任務(wù)改成了判別式的 Replaced token detection(RTD) 任務(wù),判斷當(dāng)前 token 是否被語(yǔ)言模型替換過(guò),比較類似 GAN 的思想。

生成器預(yù)測(cè)輸入文本中 mask 位置的 token:


判別器的輸入是生成器的輸出,判別器預(yù)測(cè)各個(gè)位置的詞是否是被替換過(guò)的:

此外,還做了些優(yōu)化:
- 生成器和判別器分別是一個(gè) BERT,縮放了生成器 BERT 參數(shù)。
- 詞向量參數(shù)分解。
- 生成器和判別器參數(shù)共享:輸入層參數(shù)共享,包括詞向量矩陣和位置向量矩陣。
在下游任務(wù)只使用判別器,不使用生成器。
3.5 長(zhǎng)文本處理 - Transformer-XL
Transformer 處理長(zhǎng)文本的常見策略是將文本切分為固定長(zhǎng)度的塊,并獨(dú)立編碼各個(gè)塊,塊與塊之間沒有信息交互。

為了優(yōu)化對(duì)長(zhǎng)文本的建模,Transformer-XL 使用了兩個(gè)技術(shù):狀態(tài)復(fù)用的塊級(jí)別循環(huán)(Segment-Level Recurrence with State Reuse)和相對(duì)位置編碼(Relative Positional Encodings)。
3.5.1 狀態(tài)復(fù)用的塊級(jí)別循環(huán)
Transformer-XL 在訓(xùn)練的時(shí)候也是以固定長(zhǎng)度的片段的形式進(jìn)行輸入的,不同的是 Transformer-XL 的上一個(gè)片段的狀態(tài)會(huì)被緩存下來(lái)然后在計(jì)算當(dāng)前段的時(shí)候再重復(fù)使用上個(gè)時(shí)間片的隱層狀態(tài),賦予了 Transformer-XL 建模更長(zhǎng)期的依賴的能力。
長(zhǎng)度為 L 的連續(xù)兩個(gè)片段 和。的隱層節(jié)點(diǎn)的狀態(tài)表示為,其中 d 是隱層節(jié)點(diǎn)的維度。 的隱層節(jié)點(diǎn)的狀態(tài)的計(jì)算過(guò)程為:

片段遞歸的另一個(gè)好處是帶來(lái)的推理速度的提升,對(duì)比 Transformer 的自回歸架構(gòu)每次只能前進(jìn)一個(gè)時(shí)間片,Transfomer-XL 的推理過(guò)程通過(guò)直接復(fù)用上一個(gè)片段的表示而不是從頭計(jì)算,將推理過(guò)程提升到以片段為單位進(jìn)行推理。

3.5.2 相對(duì)位置編碼
在 Transformer 中,自注意力模型可以表示為:

的完整表達(dá)式為:


Transformer 的問(wèn)題是無(wú)論對(duì)于第幾個(gè)片段,它們的位置編碼 都是一樣的,也就是說(shuō) Transformer的位置編碼是相對(duì)于片段的絕對(duì)位置編碼(absulate position encoding),與當(dāng)前內(nèi)容在原始句子中的相對(duì)位置是沒有關(guān)系的。
Transfomer-XL 在上式的基礎(chǔ)上做了若干變化,得到了下面的計(jì)算方法:

- 變化1:中,被拆分成立和,也就是說(shuō)輸入序列和位置編碼不再共享權(quán)值。
- 變化2:中,絕對(duì)位置編碼替換為了相對(duì)位置編碼
- 變化3:中引入了兩個(gè)新的可學(xué)習(xí)的參數(shù)來(lái)替換和 Transformer 中的 query 向量 。表明對(duì)于所有的 query 位置對(duì)應(yīng)的 query 位置向量是相同的。即無(wú)論 query 位置如何,對(duì)不同詞的注意偏差都保持一致。
- 改進(jìn)之后,各個(gè)部分的含義:
- 基于內(nèi)容的相關(guān)度(): 計(jì)算 query 和 key 的內(nèi)容之間的關(guān)聯(lián)信息
- 內(nèi)容相關(guān)的位置偏置():計(jì)算 query 的內(nèi)容和 key 的位置編碼之間的關(guān)聯(lián)信息
- 全局內(nèi)容偏置():計(jì)算 query 的位置編碼和 key 的內(nèi)容之間的關(guān)聯(lián)信息
- 全局位置偏置():計(jì)算 query 和 key 的位置編碼之間的關(guān)聯(lián)信息
3.6 蒸餾與壓縮 - DistillBert
知識(shí)蒸餾技術(shù) (Knowledge Distillation, KD):通常由教師模型和學(xué)生模型組成,將知識(shí)從教師模型傳到學(xué)生模型,使得學(xué)生模型盡量與教師模型相近,在實(shí)際應(yīng)用中,往往要求學(xué)生模型比教師模型小并基本保持原模型的效果。
DistillBert 的學(xué)生模型:
- 六層的 BERT, 同時(shí)去掉了標(biāo)記類型向量 (Token-type Embedding, 即Segment Embedding)。
- 使用教師模型的前六層進(jìn)行初始化。
- 只使用掩碼語(yǔ)言模型進(jìn)行訓(xùn)練,沒有使用 NSP 任務(wù)。
教師模型: BERT-base:
損失函數(shù):
有監(jiān)督 MLM 損失:利用掩碼語(yǔ)言模型訓(xùn)練得到的交叉熵?fù)p失:
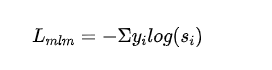
- 表示第個(gè)類別的標(biāo)簽,表示學(xué)生模型第個(gè)類別輸出的概率。
- 蒸餾MLM損失:利用教師模型的概率作為指導(dǎo)信號(hào),與學(xué)生模型的概率計(jì)算交叉熵?fù)p失:
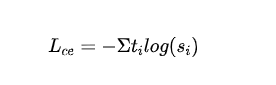
- 表示教師模型第個(gè)類別的標(biāo)簽。
- 詞向量余弦損失:對(duì)齊教師模型和學(xué)生模型的隱含層向量的方向,從隱含層維度拉近教師模型和學(xué)生模型的距離:
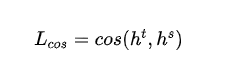
- 和分別表示教師模型和學(xué)生模型最后一層的隱含層輸出。
- 最終的損失:
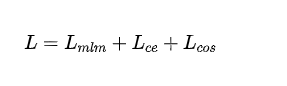
4. 參考資料
??https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer??
??https://arxiv.org/pdf/1706.03762.pdf??
??https://zhuanlan.zhihu.com/p/38130339??
??https://zhuanlan.zhihu.com/p/184970999??
??https://zhuanlan.zhihu.com/p/466841781??
??https://blog.csdn.net/Dream_Poem/article/details/122768058??
??https://aclanthology.org/N18-1202.pdf??
??https://zhuanlan.zhihu.com/p/350017443??
??https://life-extension.github.io/2020/05/27/GPT技術(shù)初探/language-models.pdf??
??https://arxiv.org/pdf/2005.14165.pdf??
??http://www.4k8k.xyz/article/abc50319/108544357??
??https://arxiv.org/pdf/1906.08237.pdf??
??https://zhuanlan.zhihu.com/p/103201307??
??https://arxiv.org/pdf/1810.04805.pdf??
??https://zhuanlan.zhihu.com/p/51413773??
??https://arxiv.org/pdf/1907.11692.pdf??
??https://zhuanlan.zhihu.com/p/103205929??
??https://arxiv.org/pdf/1909.11942.pdf??
??https://arxiv.org/pdf/2003.10555.pdf??
??https://segmentfault.com/a/1190000041107202??
??https://arxiv.org/pdf/1910.01108.pdf??
??https://zhuanlan.zhihu.com/p/271984518??



















