













PubMedBERT:生物醫學自然語言處理領域的特定預訓練模型
作者:Sik-Ho Tsang
今年大語言模型的快速發展導致像BERT這樣的模型都可以稱作“小”模型了。Kaggle LLM比賽LLM Science Exam 的第四名就只用了deberta,這可以說是一個非常好的成績了。
今年大語言模型的快速發展導致像BERT這樣的模型都可以稱作“小”模型了。Kaggle LLM比賽LLM Science Exam 的第四名就只用了deberta,這可以說是一個非常好的成績了。所以說在特定的領域或者需求中,大語言模型并不一定就是最優的解決方案,“小”模型也有一定的用武之地,所以今天我們來介紹PubMedBERT,它使用特定領域語料庫從頭開始預訓練BERT,這是微軟研究院2022年發布在ACM的論文。

論文的主要要點如下:
對于具有大量未標記文本的特定領域,如生物醫學,從頭開始預訓練語言模型比持續預訓練通用領域語言模型效果顯著。提出了生物醫學語言理解與推理基準(BLURB)用于特定領域的預訓練。
PubMedBERT
1、特定領域Pretraining

研究表明,從頭開始的特定領域預訓練大大優于通用語言模型的持續預訓練,從而表明支持混合領域預訓練的主流假設并不總是適用。
2、模型
使用BERT。對于掩碼語言模型(MLM),全詞屏蔽(WWM)強制要求整個詞必須被屏蔽。
3、BLURB數據集
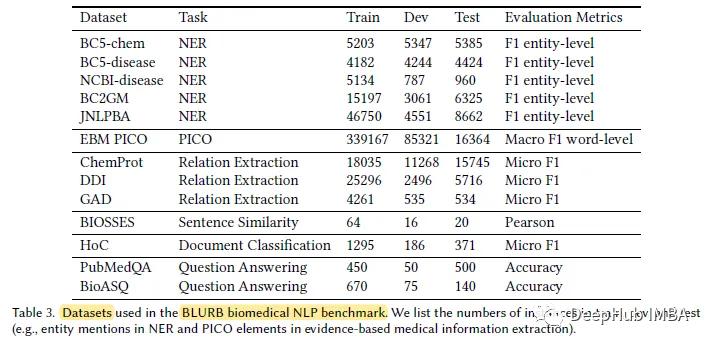
據作者介紹,BLUE[45]是在生物醫學領域創建NLP基準的第一次嘗試。但BLUE的覆蓋范圍有限。針對基于pubmed的生物醫學應用,作者提出了生物醫學語言理解與推理基準(BLURB)。

PubMedBERT使用更大的特定領域語料庫(21GB)。

結果展示
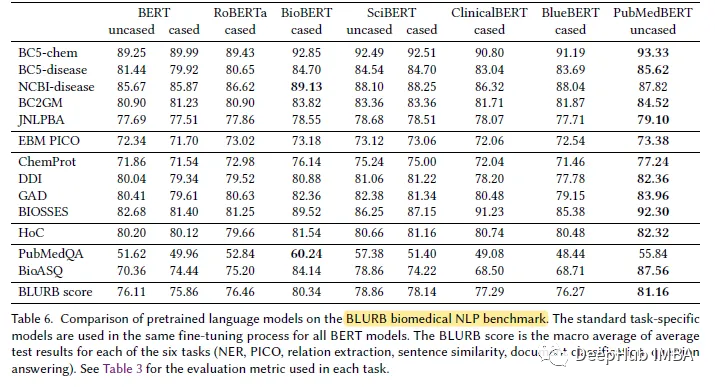
在大多數生物醫學NLP任務中,PubMedBERT始終優于所有其他BERT模型,并且通常具有顯著的優勢。
責任編輯:華軒
來源:
DeepHub IMBA



















