Python 實現(xiàn)棧的幾種方式及其優(yōu)劣

一、棧的概念
棧由一系列對象對象組織的一個集合,這些對象的增加和刪除操作都遵循一個“后進先出”(Last In First Out,LIFO)的原則。
在任何時刻只能向棧中插入一個對象,但只能取得或者刪除只能在棧頂進行。比如由書構成的棧,唯一露出封面的書就是頂部的那本,為了拿到其他的書,只能移除壓在上面的書,如圖:
棧的幾種方式及其優(yōu)劣-開源基礎軟件社區(qū)")
棧的實際應用
實際上很多應用程序都會用到棧,比如:
- 網絡瀏覽器將最近瀏覽的網址存放在一個棧中。每當用戶訪問者訪問一個新網站時,這個新網站的網址就被壓入棧頂。這樣,每當我們在瀏覽器單擊“后退”按鈕時(或者按鍵盤快捷鍵 CTRL+Z ,大部分撤銷快捷鍵),就可以彈出當前最近一次訪問的網址,以回到其先前訪問的瀏覽狀態(tài)。
- 文本編輯器通常會提供一個“撤銷”機制以取消最近的編輯操作并返回到先前狀態(tài)。這個撤銷操作也是通過將文本的變化狀態(tài)保存在一個棧中得以實現(xiàn)。
- 一些高級語言的內存管理,JVM 的棧、Python 棧還用于內存管理、嵌套語言特性的運行時環(huán)境等
- 回溯(玩游戲,尋找路徑,窮舉搜索)
- 在算法中使用,如漢諾塔、樹形遍歷、直方圖問題,也用于圖算法,如拓撲排序
- 語法處理:
- 參數(shù)和局部變量的空間是用堆棧在內部創(chuàng)建的。
- 編譯器對大括號匹配的語法檢查
- 對遞歸的支持
- 在編譯器中像后綴或前綴一樣的表達式
二、棧的抽象數(shù)據(jù)類型
任何數(shù)據(jù)結構都離不開數(shù)據(jù)的保存和獲得方式,如前所述,棧是元素的有序集合,添加和操作與移除都發(fā)生在其頂端(棧頂),那么它的抽象數(shù)據(jù)類型包括:
- Stack() :創(chuàng)建一個空棧,它不需要參數(shù),且會返回一個空棧。
- push(e): 將一個元素 e 添加到棧 S 的棧頂,它需要一個參數(shù) e,且無返回值。
- pop() : 將棧頂端的元素移除,它不需要參數(shù),但會返回頂端的元素,并且修改棧的內容。
- top(): 返回棧頂端的元素,但是并不移除棧頂元素;若棧為空,這個操作會操作。
- is_empty(): 如果棧中不包含任何元素,則返回一個布爾值True。
- size():返回棧中元素的數(shù)據(jù)。它不需要參數(shù),且會返回一個整數(shù)。在 Python 中,可以用__len__ 這個特殊方法實現(xiàn)。
棧的幾種方式及其優(yōu)劣-開源基礎軟件社區(qū)")
Python 棧的大小可能是固定的,也可能有一個動態(tài)的實現(xiàn),即允許大小變化。在大小固定棧的情況下,試圖向已經滿的棧添加一個元素會導致棧溢出異常。同樣,試圖從一個已經是空的棧中移除一個元素,進行 ??pop()?? 操作這種情況被稱為下溢。
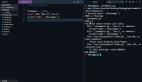
三、用 Python 的列表實現(xiàn)棧
在學習 Python 的時候,一定學過 Python 列表 ??list?? , 它能通過一些內置的方式實現(xiàn)棧的功能:
- 通過append 方法用于添加一個元素到列表尾部,這種方式就能模擬push() 操作。
- 通過pop() 方法用于模擬出棧操作。
- 通過L[-1] 模擬top()操作。
- 通過判斷l(xiāng)en(L)==0 模擬isEmpty() 操作。
- 通過len() 函數(shù)實現(xiàn)size() 函數(shù)。
棧的幾種方式及其優(yōu)劣-開源基礎軟件社區(qū)")
代碼如下:
運行該程序,結果:
除了將列表的隊尾作為棧頂,也可以通過將列表的頭部作為棧的頂端。不過在這種情況下,便無法直接使用 pop() 方法和 append()方法,但是可以通過 pop() 和 insert() 方法顯式地訪問下標為 0 的元素,即列表的第一個元素,代碼如下:
雖然我們改變了抽象數(shù)據(jù)類型的實現(xiàn),卻保留了其邏輯特征,這種能力體現(xiàn)了抽象思想。不管,雖然兩種方法都實現(xiàn)了棧,但兩者的性能方法有差異:
- append()? 和pop() 方法的時間復雜度都是 *O(1),*常數(shù)級別操作
- 第二種實現(xiàn)的性能則受制于棧中的元素個數(shù),這是因為insert(0)? 和pop(0) 的時間復雜度都是O(n),元素越多就越慢。?
四、用 collections.deque 實現(xiàn)棧
在 Python 中,collections 模塊有一個雙端隊列數(shù)據(jù)結構 deque,這個數(shù)據(jù)結構同樣實現(xiàn)了 append() 和 pop() 方法:
為什么有了 list 還需要 deque?
可能你可以看到 deque 和列表 list 對元素的操作差不多,那么為什么 Python 中有列表還增加了 deque 這一個數(shù)據(jù)結構呢?
那是因為,Python 中的列表建立在連續(xù)的內存塊中,意味著列表的元素是緊挨著存儲的。
棧的幾種方式及其優(yōu)劣-開源基礎軟件社區(qū)")
這對一些操作來說非常有效,比如對列表進行索引。獲取 myList[3] 的速度很快,因為 Python 確切地知道在內存中尋找它的位置。這種內存布局也允許切片在列表上很好地工作。
毗連的內存布局是 list 可能需要花費更多時間來 .append() 一些對象。如果連續(xù)的內存塊已經滿了,那么它將需要獲得另一個內存塊,先將整體 copy 過去,這個動作可能比一般的 .append() 操作花費更多的時間。
棧的幾種方式及其優(yōu)劣-開源基礎軟件社區(qū)")
而雙端隊列 deque 是建立在一個雙鏈表的基礎上。在一個鏈接列表結構中,每個條目都存儲在它自己的內存塊中,并有一個對列表中下一個條目的引用。
雙鏈表也是如此,只是每個條目都有對列表中前一個和后一個條目的引用。這使得你可以很容易地在列表的兩端添加節(jié)點。
在一個鏈接列表結構中添加一個新的條目,只需要設置新條目的引用指向當前堆棧的頂部,然后將堆棧的頂部指向新條目。
棧的幾種方式及其優(yōu)劣-開源基礎軟件社區(qū)")
棧的幾種方式及其優(yōu)劣-開源基礎軟件社區(qū)")
然而,這種在棧上不斷增加和刪除條目的時間是有代價的。獲取 myDeque[3] 的速度要比列表慢,因為 Python 需要走過列表的每個節(jié)點來獲取第三個元素。
幸運的是,你很少想在棧上做隨機索引元素或進行列表切片操作。棧上的大多數(shù)操作都是 push 或 pop。
如果你的代碼不使用線程,常數(shù)時間的 .append() 和 .pop() 操作使 deque 成為實現(xiàn) Python 棧的一個更好的選擇。
五、用 queue.LifoQueue 實現(xiàn)棧
Python 棧在多線程程序中也很有用,我們已經學習了 list 和 deque 兩種方式。對于任何可以被多個線程訪問的數(shù)據(jù)結構,在多線程編程中,我們不應該使用 list,因為列表不是線程安全的。deque 的 .append() 和 .pop() 方法是原子性的,意味著它們不會被不同的線程干擾。
因此,雖然使用 deque 可以建立一個線程安全的 Python 堆棧,但這樣做會使你自己在將來被人誤用,造成競態(tài)條件。
好吧,如果你是多線程編程,你不能用 list 來做堆棧,你可能也不想用 deque 來做堆棧,那么你如何為一個線程程序建立一個 Python 堆棧?
答案就在 queue 模塊中:queue.LifoQueue。還記得你是如何學習到棧是按照后進先出(LIFO)的原則運行的嗎?嗯,這就是 LifoQueue 的 "Lifo "部分所代表的含義。
雖然 list 和 deque 的接口相似,但 LifoQueue 使用 .put() 和 .get() 來從棧中添加和刪除數(shù)據(jù)。
與 deque 不同,LifoQueue 被設計為完全線程安全的。它的所有方法都可以在線程環(huán)境中安全使用。它還為其操作添加了可選的超時功能,這在線程程序中經常是一個必須的功能。
然而,這種完全的線程安全是有代價的。為了實現(xiàn)這種線程安全,LifoQueue 必須在每個操作上做一些額外的工作,這意味著它將花費更長的時間。
通常情況下,這種輕微的減速對你的整體程序速度并不重要,但如果你已經測量了你的性能,并發(fā)現(xiàn)你的堆棧操作是瓶頸,那么小心地切換到 deque 可能是值得做的。
六、選擇哪一種實現(xiàn)作為棧
一般來說,如果你不使用多線程,你應該使用 deque。如果你使用多線程,那么你應該使用 LifoQueue,除非你已經測量了你的性能,發(fā)現(xiàn) push 和 pop 的速度的小幅提升會帶來足夠的差異,以保證維護風險。
你可以對列表可能很熟悉,但需要謹慎使用它,因為它有可能存在內存重新分配的問題。deque 和 list 的接口是相同的,而且 deque 沒有線程不安全問題。
七、總結
本文介紹了棧這一數(shù)據(jù)結構,并介紹了在現(xiàn)實生活中的程序中如何使用它的情況。在文章的中,介紹了 Python 中實現(xiàn)棧的三種不同方式,知道了 deque 對于非多線程程序是一個更好的選擇,如果你要在多線程編程環(huán)境中使用棧的話,可以使用 LifoQueue。