一次由groovy引起的fullGC問題排查

一、問題背景
二、分析過程
- 2.1 參數配置
- 2.2 定位過程
- 2.3 JVM分析
- 2.4 問題分析
三、解決方案
一、問題背景
prometheus監控報警生效后,某服務每天的上午 8-12 點間會有fullGC的報警;
排查并解決該問題;
二、分析過程
2.1 參數配置
JVM 參數配置如下:
新生代大小:1G;
新生代垃圾收集器:ParNewGC;
老年代大小:2G;
老年代垃圾收集器:ConcMarkSweepGC;
CMS觸發條件:老年代內存占用達到80%及以上;
2.2 定位問題
1.由于報警的時間點都集中在上午的 8-12 點之間,懷疑是由于某個定時任務造成的;
2.定位具體的定時任務,有兩個定時任務的時間設置基本滿足;
3.確定具體的任務
確認的兩個思路:
1.通過日志確認定時任務的執行時長等;
2.將2個定時任務分別指定不同的機器執行觀察;
排查任務執行時間:
任務1 : 很快,幾乎不處理業務邏輯;
任務2: 執行約35分鐘時間;
8:10分開始,8:45分結束;
基本確定為第二個定時任務導致FullGC;
2.3 JVM分析
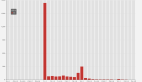
2.3.1 單天監控圖
內存趨勢
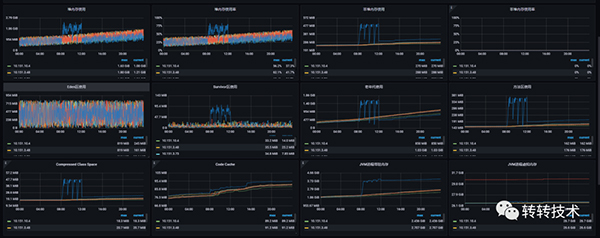
GC趨勢
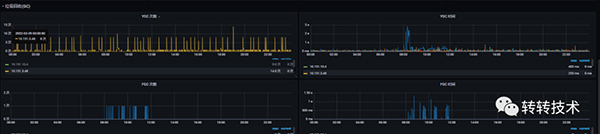
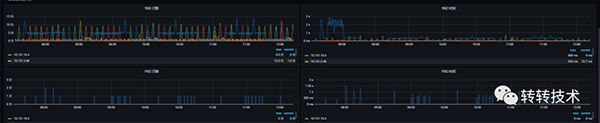
2.3.2 報警時間段監控圖
內存趨勢
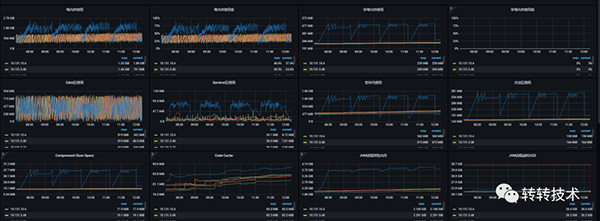
GC趨勢
2.3.3 圖表分析
2.3.3.1 老年代變化
現象
1.任務執行過程中:老年代有明顯增長,并且FullGC后并沒有特別明顯的下降,只有些許下降;
2.任務執行結束后:下次任務開始執行,進行FullGC后,會降到跟其他機器一樣的水平,甚至內存占用更低;
備注
新生代到老年代的幾種情況
1:大對象;
2:年齡足夠長,cms沒有設置,默認是6,通過jinfo確認也是6;
3:suvivor區不足以存放YGC后的存活對象,直接使用擔保策略晉升到老年代;
分析
任務執行過程中,YGC平均1分鐘執行5次,很多對象都會達到最大晉升年齡6,晉升到老年代;
并且由于任務沒有結束,對象還有引用,所以FullGC之后并沒有明顯下降;
上次任務結束后,老年代并沒有像suvivor區一樣有一段時間的低內存占用,主要是直到下次任務開始后才會觸發新一次的FullGC,觸發后,老年代的對象由于任務結束后沒有引用了,所以會正常回收;
2.3.3.2 survivor區變化
suvivor區內存總共100M,任務執行過程中,平均占用 80M;高的時候會飆升到90以上,所以這個過程中YGC也變得很頻繁,平均1分鐘5次;
2.3.3.3 非堆內存/方法區/compressed class cach變化
使用 jstat 分別統計了兩臺機器的gc統計,兩者最大的區別在于 執行過定時任務的機器的MC(方法區大小) 以及 CCSC(壓縮類空間大小) 明顯比沒有執行過定時任務的機器高很多;

任務執行過程中方法區的內存占用會跟老年代的曲線保持一致,這幾個區的回收也是靠老年代,這個通過grafana平臺的監控圖也可以看出來;
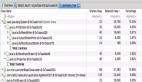
2.3.3.4 dump文件分析
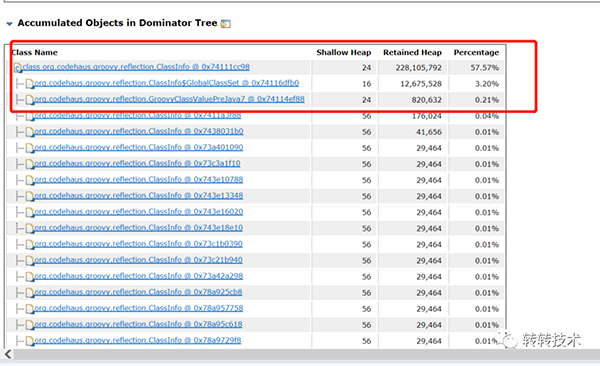
groovy相關的類占比57.57%;
2.4 參數配置
java 與 groovy 版本
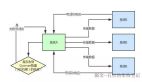
代碼中使用到groovy的地方:同樣是這個定時任務,下發任務時,表達式檢驗是否滿足下發條件,表達式是用groovy進行處理的;
基本上可以定位問題在groovy腳本的加載處,groovy不合理使用會導致,動態生成很多新類,使得metaspace的不斷被占用;
class 對象在 1.8 及以后存放在 metaspace 中,也就是堆外內存。
groovy每執行一次,會將傳入的文本動態加載成一個腳本類,入參是文本時,生成的文件名中包含了一個自增的數值,也就是每執行一次都會動態生成一個新類,1個用戶7個任務規則校驗 * 15962個用戶 = 111734個
GroovyShell 在內部,它使用groovy.lang.GroovyClassLoader,這是在運行時編譯和加載類的核心。
GroovyClassLoader 保留對其創建的所有類的引用,而 class 對象只有在被加載的 classloader 被回收的時候才會被回收,因此很容易造成內存泄漏;
綜上分析,groovy 錯誤的使用方式導致 class 對象常駐堆外內存且隨著調用頻率增長。
三、解決方案
1、每個腳本共用一個 GroovyShell 對象,不能使用 for 的方式,循環創建使用;
2、每次執行完釋放對象 shell.getClassLoader().clearCache();