譯者 | 朱先忠
審校 | 孫淑娟
簡介
神經網絡嵌入能夠實現輸入數據的低維表示,從而服務于各種類型的神經網絡應用程序。嵌入有一些有趣的功能,因為它們可以捕獲數據點的語義。這對于圖像和視頻等非結構化數據尤其有用,這樣不僅可以對像素相似性進行編碼,還可以對一些更復雜的關系進行編碼。
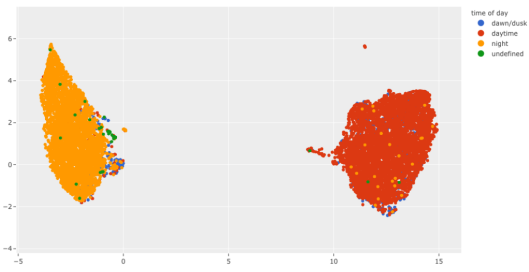
使用FiftyOne和Plotly可視化針對BDD100K數據集的嵌入
在這些嵌入上執行搜索可以應用于許多場景下,如分類任務、建立推薦系統,甚至是異常檢測任務。對嵌入執行最近鄰搜索以完成這些任務的主要好處之一是,無需為每個新問題創建自定義網絡;您可以經常使用預先訓練的模型。而且,使用某些公開可用模型生成的嵌入是完全可能的,而無需任何進一步的微調。
雖然有很多涉及嵌入的強大使用場景,但在執行嵌入搜索的工作流中往往都存在一些不同程度的挑戰。具體而言,在大型數據集上執行最近鄰搜索,然后有效地對搜索結果采取行動——例如執行自動標記數據等工作流,都存在技術和工具方面的挑戰。為此,借助于Qdrant和FiftyOne這兩個開源軟件可以幫助簡化這些工作流任務。
- Qdrant是一個開源的向量數據庫,旨在對密集的神經嵌入執行近似最近鄰搜索(ANN),這對于任何預計將擴展到大數據量的生產就緒系統都是非常必要的。
- FiftyOne是一個開源數據集管理和模型評估工具,允許開發人員有效地管理和可視化數據集,生成嵌入并改進模型結果。
在本文中,我們將MNIST數據集加載到FiftyOne中,并基于ANN進行分類。數據點將通過從訓練數據集中的K個最近點中選擇最常見的參考答案標簽進行分類。換句話說,對于每個測試樣本,我們將使用選定的距離函數選擇其K個最近的鄰居,然后通過投票選擇最佳標簽。另一方面,向量空間中的所有搜索都將使用Qdrant來完成,以加快速度。然后,我們將在FiftyOne中評估該分類的結果。
安裝
如果您想開始使用Qdrant的語義搜索,您需要運行它的一個實例,因為該工具以客戶機—服務器方式工作。要做到這一點,最簡單的方法是使用一個官方Docker映像,只需一個命令即可啟動Qdrant:
運行該命令后,我們將運行Qdrant服務器,端口6333處暴露HTTP API,端口6334處暴露gRPC接口。
此外,我們還需要安裝一些Python包。我們將使用FiftyOne來可視化數據、它們的參考答案標簽以及嵌入相似性模型預測的數據。嵌入將通過torchvision中提供的MobileNet v2創建。當然,我們也需要以某種方式與Qdrant服務器通信,因為我們將使用Python,所以Qdrant_client是實現這一任務的首選方式。
整體任務流程
1. 加載數據集
2. 生成嵌入
3. 將嵌入加載到Qdrant
4. 最近鄰分類
5. FiftyOne評估
加載數據集
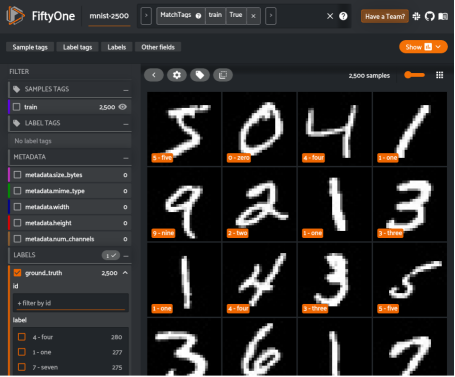
為了使事情順利進行,我們需要采取幾個步驟。首先,我們需要加載??MNIST數據集??,并從中提取訓練樣本,因為我們將在搜索操作中使用它們。為了使一切更快,我們不打算使用所有的樣本,只使用2500個樣本。我們可以使用??FiftyOne數據集Zoo??,并通過一行代碼來加載所需的MNIST子集。
接下來,讓我們仔細分析一下FiftyOne應用程序中所使用的數據集。
生成嵌入
下一步是在數據集中的樣本上生成嵌入。這始終可以在FiftyOne之外使用您的自定義模型完成。然而,FiftyOne也在其中的FiftyOneModelZoo中提供了各種模型,這些模型可以直接用于生成嵌入。
在本例中,我們使用在ImageNet上訓練的MobileNetv2來計算每個圖像的嵌入。
將嵌入結果加載到Qdrant
Qdrant不僅可以存儲向量,還可以存儲一些相應的屬性——每個數據點都有一個相關的向量,還可以選擇附帶一個JSON類型的屬性項。我們想用這個來傳遞參考答案標簽,以確保我們可以在稍后做出預測。
創建嵌入后,我們可以開始與Qdrant服務器進行通信了。需要說明的是,QdrantClient有一個類實例比較有用,因為它包含了所有必需的方法。讓我們連接并創建一個名為“mnist”的點集合。向量大小取決于模型輸出;因此,如果我們想在以后使用不同的模型進行實驗,我們需要導入不同的模型,但其余的將保持不變。最終,在確保集合存在后,我們可以發送所有向量及其包含其真實標簽的有效載荷。
最近鄰分類
現在對數據集執行推斷。我們可以為測試數據集創建嵌入,但忽略基本事實,并嘗試使用ANN找到它,然后比較兩者是否匹配。讓我們一步一步地從創建嵌入開始。
是時候“施展魔法”了。讓我們遍歷測試數據集的樣本和相應的嵌入,并使用搜索操作從訓練集中找到15個最接近的嵌入。我們還需要選擇有效載荷,因為它們包含找到特定點附近最常見標簽所需的參考答案標簽。借助于Python的Counter類,我們可以避免再重寫任何樣板代碼。最常見的標簽將作為“ann_production”存儲在FiftyOne中的每個測試樣本上。
這些內容都體現在下面這個函數中。該函數將使用嵌入向量作為輸入,并使用Qdrant搜索功能查找與測試嵌入最近的鄰居,生成類型預測,并返回一個FiftyOne Classification對象,我們可以將其存儲在FiftyOne數據集中。
我們通過計算屬于最常見標簽的樣本分數來估計置信度。這給了我們一種直覺,即我們在預測每種情況的標簽時有多么確定,并且可以在FiftyOne中使用,輕松找出令人困惑的樣本。
FiftyOne評估
現在是取得一些成果的時候了!讓我們從可視化這個分類器的表現開始。我們可以輕松啟動??FiftyOne應用程序??來查看參考答案標簽、預測結果和圖像。
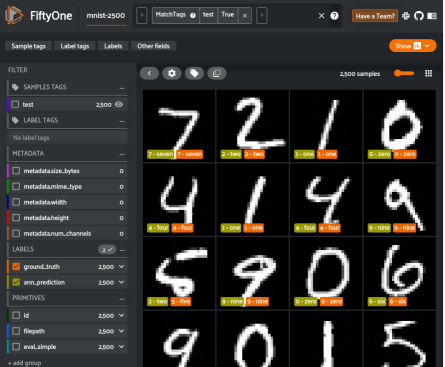
FiftyOne提供了各種內置方法來評估模型預測,包括圖像和視頻數據集上的回歸、分類、檢測、多邊形、實例和語義分割。通過下面兩行代碼,我們即可以計算并打印分類器的評估報告。
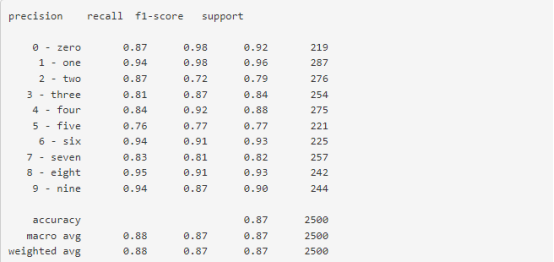
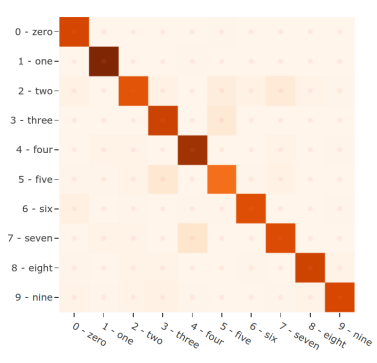
在評估FiftyOne之后,我們可以使用results對象生成一個交互式混淆矩陣(https://voxel51.com/docs/fiftyone/user_guide/plots.html#confusion-matrices),允許我們點擊單元格并自動更新應用程序以顯示相應的樣本。
我們還可以再深入一點。我們可以使用FiftyOne復雜的??查詢語言??,輕松找到所有與實際情況不匹配的預測,但預測的可信度很高。這些通常是數據集中最令人困惑的樣本,不過也是我們可以從中獲得最深刻見解的樣本。
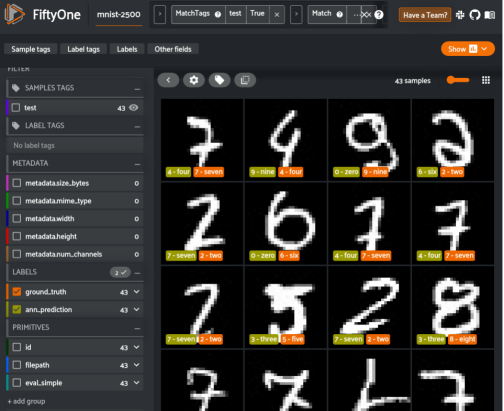
上圖中展示了模型中最令人困惑的樣本,正如您所看到的,與數據集中的其他圖像相比,它們非常不規則。我們可以采取的改進模型性能的下一步可能是使用FiftyOne來添加與這些類似的精確樣本。然后,可以通過FiftyOne與CVAT,以及Labelbox等工具之間的集成對這些樣本進行注釋。此外,我們可以使用更多的向量進行訓練,或者通過相似性學習對模型進行微調,例如,使用三元組損失算法。但現在,這個使用FiftyOne和Quadrant進行向量相似性分類的示例已經能夠很好地工作了。
就這么簡單,我們使用FiftyOne和Qdrant作為嵌入后端創建了一個ANN分類模型,因此查找向量之間的相似性可以不再像傳統k-NN那樣成為我們任務的瓶頸了。
請自己試試看
最后,Github代碼倉庫中的??筆記本文件??包含了你在本文中看到的所有內容的源代碼。此外,它還包括該過程的一個實際用例,以在BDD100K道路場景數據集上執行夜間和白天屬性的預注釋。
總之,FiftyOne和Qdrant兩個開源庫可以一起使用,有效地對嵌入執行最近鄰居搜索,并對圖像和視頻數據集的結果進行操作。這個過程的美妙之處在于它的靈活性和可重復性。您可以輕松地將新字段的附加參考答案標簽加載到FiftyOne和Qdrant中,并使用現有嵌入重復此預注釋過程。這可以快速降低注釋成本,并更快地生成更高質量的數據集。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:??Nearest Neighbor Embeddings Search With Qdrant and FiftyOne??,作者:Eric Hofesmann