圖片遲遲加載不了、一片馬賽克?谷歌開源模型優(yōu)先顯示圖像受關(guān)注部分
當(dāng)觀察一副圖像時,你會先注意圖像的哪些內(nèi)容,或者說圖像中的哪些區(qū)域會首先吸引你的注意力,機(jī)器能否學(xué)會人類的這種注意力形式。在來自谷歌的一項研究中,他們開源的注意力中心模型(attention center model)可以做到這一點。并且該模型可用于 JPEG XL 圖像格式上。
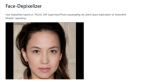
舉例來說,下圖是注意力中心模型的一些預(yù)測示例,其中綠點為預(yù)測的圖像的注意力中心點。

圖像來自 Kodak 圖像數(shù)據(jù)集:http://r0k.us/graphics/kodak/
注意力中心模型大小為 2MB,格式為 TensorFlow Lite。它以 RGB 圖像作為輸入,并輸出一個 2D 點,該點是圖像上的預(yù)測注意力中心點。
為了訓(xùn)練模型來預(yù)測注意力中心,首先需要一些來自注意力中心的真實數(shù)據(jù)。給定一張圖像,一些注意力點可以通過眼動儀收集,或者通過鼠標(biāo)點擊圖像來接近。該研究首先對這些注意點進(jìn)行時間濾波,只保留最初的注意力點,然后應(yīng)用空間濾波去除噪聲。最后,計算剩余注意力點的中心作為真值注意力中心。下面顯示了獲取真值過程的示例說明圖。

項目地址:https://github.com/google/attention-center
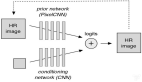
注意力中心模型架構(gòu)
注意力中心模型是一個深度神經(jīng)網(wǎng)絡(luò),以一張圖像為輸入,使用預(yù)訓(xùn)練分類網(wǎng)絡(luò)如 ResNet、MobileNet 等作為骨干。從骨干網(wǎng)絡(luò)輸出的幾個中間層被用作注意力中心預(yù)測模塊的輸入。這些不同的中間層包含不同的信息,例如,淺層通常包含較低層次的信息,如強(qiáng)度 / 顏色 / 紋理,而更深層次通常包含更高、更語義的信息,如形狀 / 目標(biāo)。
注意中心預(yù)測采用卷積、反卷積調(diào)整算子,并結(jié)合聚合和 sigmoid 函數(shù),生成注意力中心的權(quán)重圖。然后一個算子(在例子中是愛因斯坦求和算子)可用于從加權(quán)圖中計算中心。預(yù)測注意力中心和真實注意力中心之間的 L2 范數(shù)作為訓(xùn)練損失。

此外 JPEG XL 是一種新的圖像格式,允許用戶在對圖像編碼時,確保有趣的部分率先顯示。這樣做的好處是,當(dāng)用戶在網(wǎng)上瀏覽圖像時,圖像中吸引人的部分可以率先顯示出來,也就是用戶首先看到的部分,在理想情況下,一旦用戶看向圖片其余地方時,圖像的其他部分也已經(jīng)就位并已解碼。
在 JPEG XL 中,圖像通常被劃分為大小為 256 x 256 的矩陣, JPEG XL 編碼器將在圖像中選擇一個起始組,然后圍繞該組生成同心正方形。Chrome 瀏覽器從 107 版增加了對 JPEG XL 圖像的漸進(jìn)解碼功能。目前,JPEG XL 還是一個實驗性的產(chǎn)物,在 chrome://flags 中通過搜索 jxl 即可啟用。
要想了解漸進(jìn)式加載 JPEG XL 圖像的效果,可以訪問網(wǎng)址進(jìn)行查看:
https://google.github.io/attention-center/