為什么游戲行業喜歡用 PolarDB
為什么游戲行業喜歡用PolarDB
游戲行業痛點
在我看來, 不同行業對數據庫使用有巨大的差別. 比如游戲行業沒有復雜的事務交易場景, 他有一個非常大的blob 字段用于存儲角色的裝備信息, 那么大Blob 字段的更新就會成為數據庫的瓶頸, 比如在線教育行業需要有搶課的需求, 因此會有熱點行更新的場景, 對熱點行如何處理會成為數據庫的瓶頸, 比如SaaS 行業, 每一個客戶有一個Database, 因此會有非常多的Table, 那么數據庫就需要對多表有很好的支持能力。
游戲行業和其他行業對數據庫的使用要求是不一樣的。
所以在支撐了大量游戲業務之后, 我理解游戲行業在使用自建MySQL 的時候有3個比較大的痛點
- 對備份恢復的需求
- 對寫入性能的要求
- 對跨region 容災的需求
接下來會分別講述這三個痛點PolarDB 是如何解決的。
備份恢復
筆者和大量游戲開發者溝通中, 游戲行業對備份恢復的需求是極其強烈的. 比如在電商行業, 是不可能存在將整個數據庫實例進行回滾到一天之前的數據, 這樣所有的用戶的購買交易信息都丟失了。
但是, 在游戲行業中, 這種場景確實存在的, 比如在發版的時候, 游戲行業是有可能發版失敗, 這個在其他行業出現概率非常低, 如果發版失敗, 那么整個實例就需要回滾到版本之前. 因此每次發版的時候都需要對數據庫實例進行備份. 因此當我們玩游戲的時候, 看到大版本需要停服更新, 那么就有可能是因為后臺需要備份數據等等一系列操作了。
還有一種場景, 當發生因為 漏洞, 參數配置錯誤等等場景下, 這種緊急情況游戲就需要回滾到出問題前的版本, 這樣就需要對整個實例進行回滾。
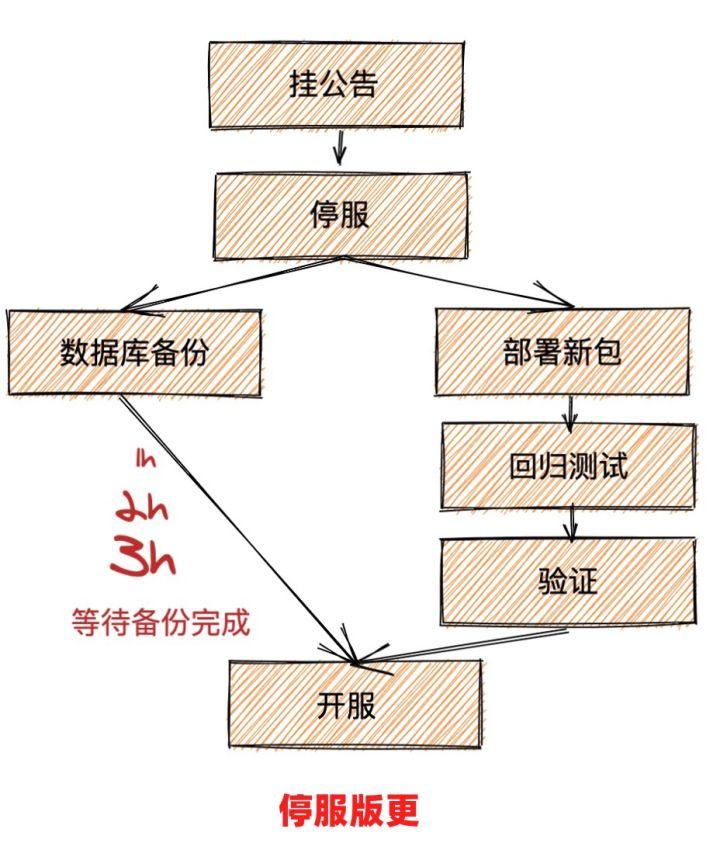
官方MySQL 由于是單機架構, 那么常見的備份方法是通過Xtrabackup 工具, 將數據備份到本地以后, 如果本地空間不夠, 就需要上傳到OSS 等遠端存儲中. 通常通過Xtrabackup 備份工具都需要1h 左右, 如果需要將數據上傳到遠端那么時間就更長了。
PolarDB 是天然的計存分離的架構, 那么備份的時候通過底下分布式存儲的快照能力, 備份可以不超過30s, 將備份時間大大縮短了。
核心思路是采用Redirect-on-Write 機制, 每次創建快照并沒有真正Copy數據, 只有建立快照索引, 當數據塊后期有修改(Write)時才把歷史版本保留給Snapshot, 然后生成新的數據塊, 被原數據引用(Redirect)。
另外一種場景是, 在游戲行業中, 有可能某一個玩家的裝備被盜號了, 那么玩家就會找游戲的運營人員投訴, 運營人員會找到游戲運維人員, 幫忙查詢玩家的歷史數據。
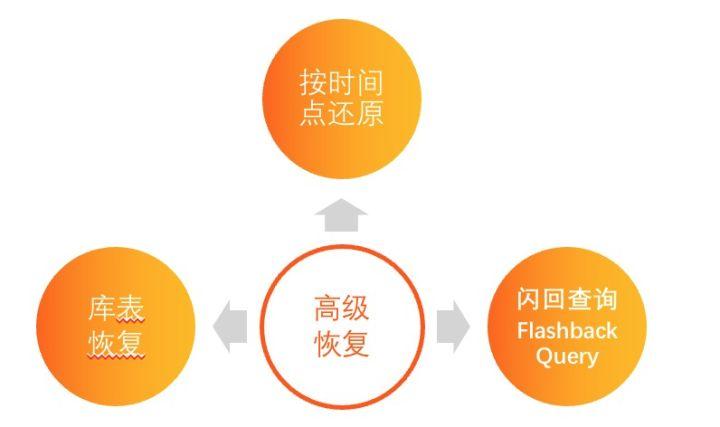
筆者之前就遇到某著名游戲多個玩家被盜號, 然后運維人員經常需要通過PolarDB 按時間的還原的能力恢復出某多個不同時間點的實例, 用來查詢這個玩家的具體裝備信息, 同時由于玩家對盜號的時間也不準確, 經常有時候需要還原出多個實例才可以。
針對這樣的場景, PolarDB 推出了Flashback Query, 就可以在當前實例查詢出任意時間點的歷史數據. 具體原理見文章 Flashback Query

整體而言, PolarDB 建立了一套非常完善的備份恢復能力, 從庫=>表=>行三個維度滿足的游戲行業對備份恢復的需求。
寫入性能
游戲行業使用數據庫的方式也與其他行業有較大區別, 是一種非常弱Schema 的使用方式, 其他行業通常對業務經常抽象, 建立表結構, 每個字段盡可能小, 不建議有大字段, 有大字段盡可能進行拆封等等.但是在游戲行業中, 由于需要滿足游戲快速迭代發展的需求, 玩家的裝備信息結構非常復雜, 因此常見的做法是將玩家裝備等級信息保存在一個大的blob字段中, 這個blob字段通過proto_buf 或者 json 進行編解碼, 每次在獲得裝備或者升級以后, 就進行整個字段更新, 在游戲開服初期玩家數據長度較短, 而隨著游戲版本更新版本, 游戲劇情, 運營活動的增多, 相對于游戲開服初期的數KB, blob字段的長度可能會膨脹到數百KB, 甚至達到MB級別, 因此可能只是獲得一個裝備, 就需要向數據庫寫入數百KB 大小的數據, 這樣的寫放大其實非常不合理。
目前也有像MongoDB 這樣的文檔數據庫, 讓用戶寫入的時候僅僅更新某個字段, 從而減少寫放大. 但是這樣影響了用戶的使用習慣, 需要用戶在業務邏輯上進行修改, 這是快速發展的游戲行業所不能接受的, 所以筆者看到盡管有客戶因為寫入問題轉向了MongoDB, 但是其實不多。
PolarDB 針對這樣的情況盡可能滿足用戶的使用習慣, 在數據庫內核層面優化數據庫的寫入能力. 通過 partition redo log, redo log cache, undo log readahead, early lock release, no blob latch 等等能力將寫入能力充分優化。
具體原理可以參考我們內核月報 和之前的文章PolarDB-cloudjump針對游戲場景, 我們修改了 sysbench 工具, 模擬游戲行業中大Blob 更新的workload, 放在 game-sysbench 工具中, 后續我們還會將更多行業比如Saas, 電商等等行業的workload 放在這個工具中。
在game_blob_update workload 中, 如果玩家的平均裝備信息是 300kb, 我們對比了PolarDB VS aurora VS 自建MySQL 的數據PolarDB 8.0 相對有最高的QPS 1877.44, 峰值QPS最高可以到2000, CPU bound場景PolarDB的性能大概是Aurora的5.7倍, 是自建 MySQL 本地盤的3倍. IO bound場景PolarDB的性能是Aurora的15倍。
CPU bound場景:
DB | 并發數據 | QPS |
PolarDB 8.0 | 5 | 1877.44 |
MySQL 8.0 本地盤 | 4 | 600.22 |
Aurora 8.0 | 200 | 328.47 |
IO bound場景:
DB | 并發數據 | QPS |
PolarDB 8.0 | 200 | 1035.30 |
MySQL 8.0 本地盤 | 200 | 610 |
Aurora 8.0 | 200 | 69.15 |
跨region 容災
目前游戲行業紛紛出海, 包含了游戲服和平臺服. 用戶在自建MySQL/RDS 的場景中, 用戶可能需要在另外一個region 建立一個新的實例, 然后通過同步工具或者DTS 進行跨region 備份. 用戶需要處理region 錯誤場景如何進行切換等等。
筆者認為對數據庫而言, 穩定性 > 易用性 > 性能.在這個場景中, 用戶如果使用云廠商的話, 使用的是云廠商提供的原子能力, 自己通過組裝這些原子能力實現容災的需求, 而PolarDB 針對這樣場景提出來PolarDB GlobalDataba 的解決方案, 將跨region 的容災放在解決方案中, 提供了一個更加易容的解決方案, 從而用戶可以關注自身的業務邏輯, 而不需要處理這些容災的場景。
在具體跨region 的同步場景方案中, PolarDB 是通過多通道物理復制能力, 從而保證跨region 的容災在1s 以內。