Wayformer: 一個實現運動預測簡單有效的注意網絡
arXiv論文“Wayformer: Motion Forecasting via Simple & Efficient Attention Networks“,2022年7月上傳,是谷歌Waymo的工作。

自動駕駛的運動預測是一項具有挑戰性的任務,因為復雜的駕駛場景會導致靜態和動態輸入的各種混合形式。如何最好地表示和融合有關道路幾何形狀、車道連通性、時變交通信號燈狀態以及智體的動態集及其交互的歷史信息,并將其轉換為有效的編碼,這是一個尚未解決的問題。為了對這組多樣輸入特征進行建模,有許多方法設計具有不同特定模態模塊集的同樣復雜系統。這導致系統難以擴展、規模化或以嚴格方式在質量和效率之間權衡。
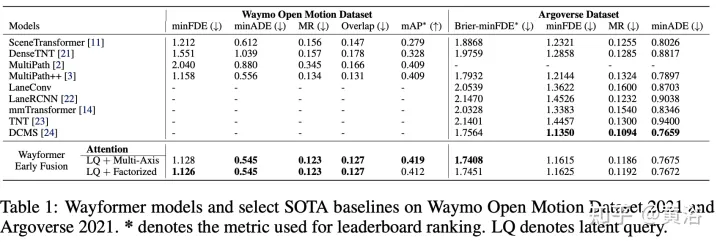
本文的Wayformer,是一系列簡單且同類的基于注意運動預測架構。Wayformer提供了一種緊湊的模型描述,由基于注意的場景編碼器和解碼器組成。在場景編碼器中,研究了輸入模式的前融合、后融合和分層融合的選擇。對于每種融合類型,探索通過分解注意或潛在query注意來權衡效率和質量的策略。前融合結構簡單,不僅模態不可知,而且在Waymo開放運動數據集(WOMD)和Argoverse排行榜上都實現了最先進的結果。
駕駛場景由多模態數據組成,例如道路信息、紅綠燈狀態、智體歷史和交互。對于模態,有一個上下文第4維,表示每個建模智體的“一組上下文目標”(即其他道路用戶的表示)。
智體歷史包含一系列過去的智體狀態以及當前狀態。對于每個時間步,考慮定義智體狀態的特征,例如x、y、速度、加速度、邊框等,還有一個上下文維度。
交互張量表示智體之間的關系。對于每個建模的智體,考慮建模智體周圍的固定數量最鄰近上下文。這些上下文智體表示影響建模智體行為的智體。
道路圖包含智體周圍的道路特征。道路圖線段表示為多段線,由其端點指定并用類型信息注釋的線段集合,可近似道路形狀。采用最接近建模智體的道路圖線段。請注意,道路特征沒有時間維度,可加入時間維度1。
對于每個智體,交通燈信息包含最接近該智體的交通信號狀態。每個交通信號點具有描述信號位置和置信度的特征。
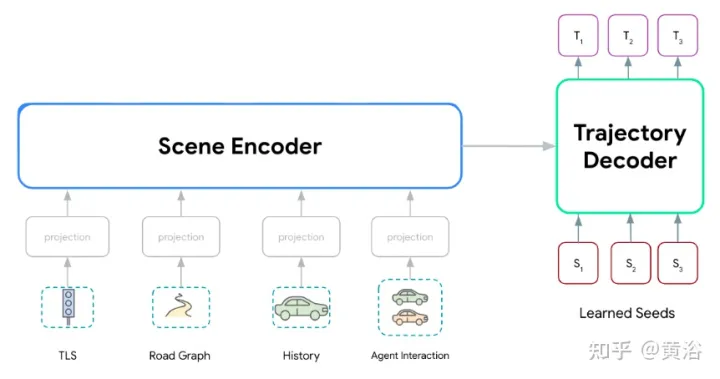
Wayformer模型系列,由兩個主要組件組成:場景編碼器和解碼器。場景編碼器主要由一個或多個注意編碼器組成,用于總結駕駛場景。解碼器是一個或多個標準transformer交叉注意模塊,其輸入學習的初始query,然后與場景編碼交叉注意生成軌跡。
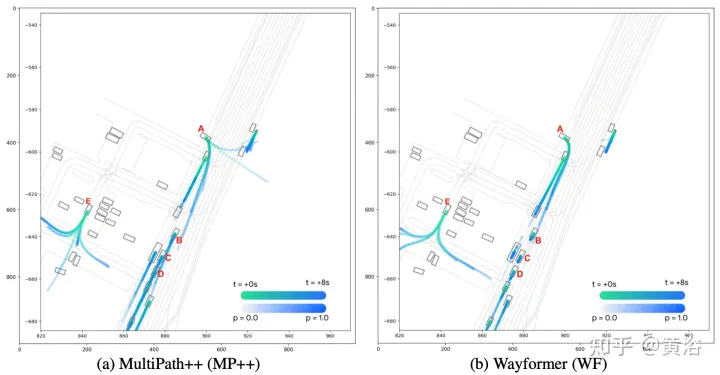
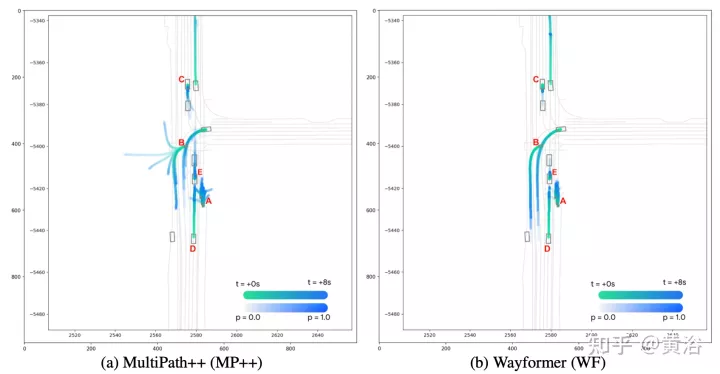
如圖顯示Wayformer模型處理多模態輸入產生場景編碼:該場景編碼用作解碼器的上下文,生成覆蓋輸出空間多模態的k條可能軌跡。
場景編碼器的輸入多樣性使這種集成變成一項不平凡的任務。模態可能不會以相同的抽象級別或尺度來表示:{像素pixels vs 目標 objects}。因此,某些模態可能需要比其他模態更多的計算。模態之間計算分解是取決于應用的,對于工程師來說非常重要。這里提出三個融合層次來簡化這個過程:{后,前,分級},如圖所示:
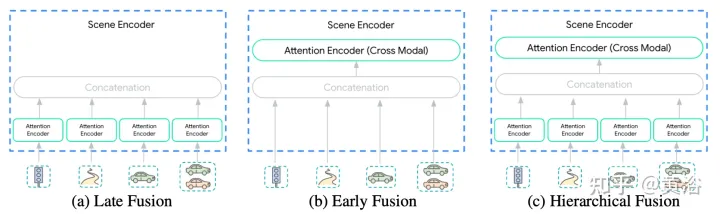
后融合是運動預測模型最常用的方法,其中每個模態都有自己的專用編碼器。將這些編碼器的寬度設置相等,避免在輸出中引入額外的投影層。此外,在所有編碼器中共享相同深度,探索空間縮小到可管理的范圍。只允許在軌跡解碼器的交叉注意層跨模態傳輸信息。
前融合不是將自注意編碼器專用于每個模態,而是減少特定模態的參數到投影層。圖中場景編碼器由單個自注意編碼器(“跨模態編碼器”)組成,網絡在跨模態分配重要性時具有最大的靈活性,同時具有最小的歸納偏差。
分層融合作為前兩個極端之間的折衷,體量以層次化的方式在模態特定的自注意編碼器和跨模態編碼器之間分解。正如在后融合所做的那樣,寬度和深度在注意編碼器和跨模態編碼器中共享。這有效地將場景編碼器的深度在模態特定編碼器和跨模態編碼器之間分攤。
由于以下兩個因素,Transformer網絡不能很好地擴展到大型多維序列:
- (a)自注意對輸入序列長度是二次方。
- (b) 位置前饋網絡是昂貴的子網絡。
下面討論加速方法,(S為空間維度,T為時域維度),其框架如圖所示:
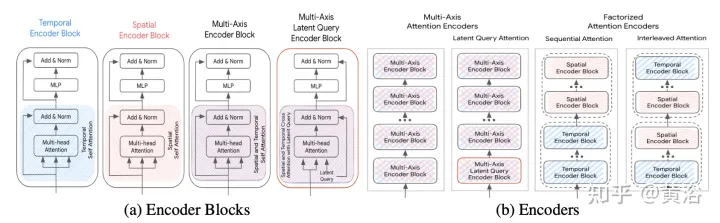
多軸注意(Multi-Axis Attention):這是指默認的transformer設置,同時在空間和時間維度上應用自注意,預計是計算成本最高的。具有多軸注意的前、后和分層融合的計算復雜度為O(Sm2×T2)。
分解注意 (Factorized attention):自注意的計算復雜度是輸入序列長度的二次方。這在多維序列中變得更加明顯,因為每個額外維度都會通過乘法因子增加輸入的大小。例如,一些輸入模態有時間和空間維度,因此計算成本規模為O(Sm2×T2)。為了緩解這種情況,考慮沿兩個維度分解注意。該方法利用輸入序列的多維結構,通過在每個維度單獨應用自注意,將自注意子網絡的成本從O(S2×T2)降低到O(S2)+O(T2)。
雖然與多軸注意相比,分解注意有可能減少計算量,但將自注意應用到每個維度的順序時引入復雜性。這里比較兩種分解注意范式:
- 順序注意(sequential attention):一個N層編碼器由N/2個時間編碼器塊和另一個N/2個空間編碼器塊組成。
- 交錯注意(Interleaved attention):N層編碼器由時間和空間編碼器塊交替N/2次組成。
潛查詢注意(Latent query attention):解決大輸入序列計算成本的另一種方法是在第一個編碼器塊中使用潛查詢,其中輸入映射到潛空間。這些潛變量由一系列編碼器塊做進一步處理,這些編碼器塊接收然后返回該潛空間。這樣可以完全自由地設置潛空間分辨率,減少每個塊中自注意分量和位置前饋網絡的計算成本。將縮減量(R=Lout/Lin)設置為輸入序列長度的百分比。在后融合和分層融合中,所有注意編碼器的折減因子R保持不變。
Wayformer預測器輸出高斯混合,表示智體可能采取的軌跡。為了生成預測,用Transformer解碼器,輸入一組k個學習的初始query(Si)并與編碼器的場景嵌入做交叉注意,為高斯混合的每個分量生成嵌入。
給定混合中一個特定成分的嵌入,一個線性投影層產生該成分的非規范對數似然,估計整個混合似然。為了生成軌跡,用另一個線性層投影,輸出4個時間序列,對應于每個時間步預測高斯的均值和對數標準偏差。
在訓練期間,將損失分解為各自分類和回歸損失。假設k個預測高斯,訓練混合似然,最大化真實軌跡的對數概率。
如果預測器輸出具有多個模式的混合高斯,則很難進行推理,基準測度通常會限制所考慮的軌跡數。因此,在評估過程中,應用軌跡聚合,減少所考慮的模態數量,同時仍保持原始輸出混合的多樣性。
實驗結果如下:
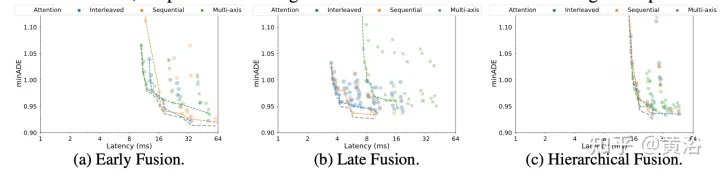
分解注意
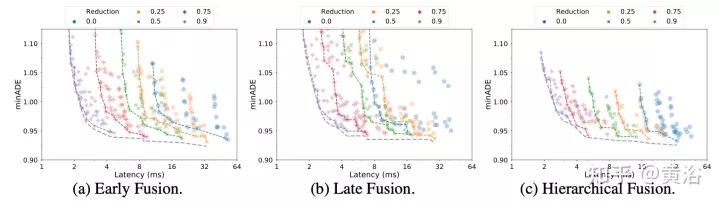
潛查詢