













詳解異步任務:函數計算的任務觸發去重?
前言
無論是在大數據處理領域,還是在消息處理領域,任務系統都有一個很關鍵的能力 - 任務觸發去重的保障。這個能力對于一些準確性要求極高的場景中(如金融等)是必不可少的。作為 Serverless 化任務處理平臺,Serverless Task 也需要提供這類保障,在用戶應用層面及自身系統內部兩個維度具備任務的準確觸發語義。本文主要針對消息處理可靠性這一主題來介紹函數計算內部的一些技術細節,并展示如何在實際應用中使用函數計算所提供的這方面能力來增強任務執行的可靠性。
淺談任務去重
在討論異步消息處理系統時,消息處理的基本語義是無法繞開的話題。在一個異步的消息處理系統(任務系統)中,一條消息的處理流程簡化如下圖所示:
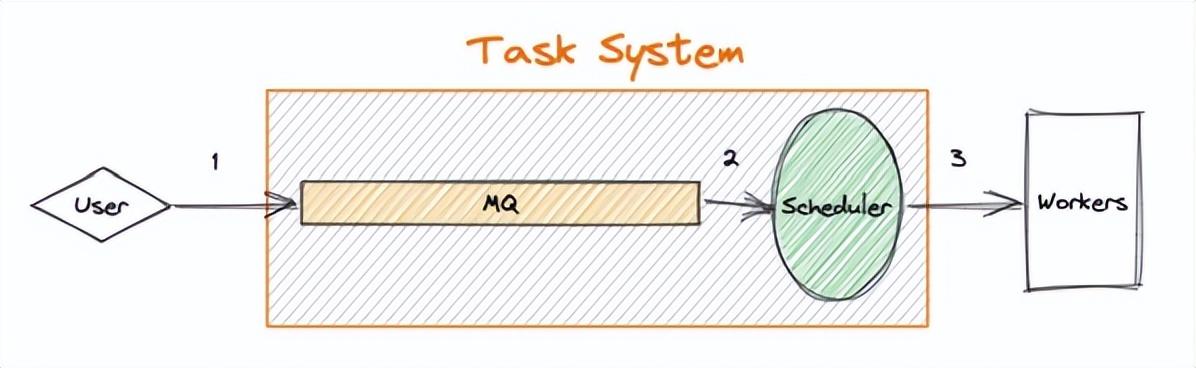
圖 1
用戶下發任務 - 進入隊列 - 任務處理單元監聽并獲取消息 - 調度到實際 worker 執行
在任務消息整個的流轉過程中,任何組件(環節)可能出現的宕機等問題會導致消息的錯誤傳遞。一般的任務系統會提供至多 3 個層級的消息處理語義:
●At-Most-Once:保證消息最多被傳遞一次。當出現網絡分區、系統組件宕機時,可能出現消息丟失;
●At-Least-Once:保證消息至少被傳遞一次。消息傳遞鏈路支持錯誤重試,利用消息重發機制保證下游一定收到上游消息,但是在宕機或者網絡分區的場景下,可能導致相同消息傳遞多次。
●Exactly-Once機制則可以保證消息精確被傳送一次,精確一次并不是意味著在宕機或網絡分區的場景下沒有重傳,而是重傳對于接受方的狀態不產生任何改變,與傳送一次的結果一樣。在實際生產中,往往是依賴重傳機制 & 接收方去重(冪等)來做到 Exactly Once。
函數計算能夠提供任務分發的 Exactly Once 語義,即無論在何種情況下,重復的任務將被系統認為是相同的觸發,進而只進行一次的任務分發。
結合圖 1,如果要做到任務去重,系統至少需要提供兩個維度的保障:
1、系統側保障:任務調度系統自身的 failover 不影響消息的傳遞正確性及唯一性;
2、提供給用戶一種機制,可以做到整個業務邏輯的觸發去重語義。
下面,我們將結合簡化的 Serverless Task 系統架構,談一談函數計算是如何做到上面的能力的。
函數計算異步任務觸發去重的實現
函數計算的任務系統架構如下圖所示
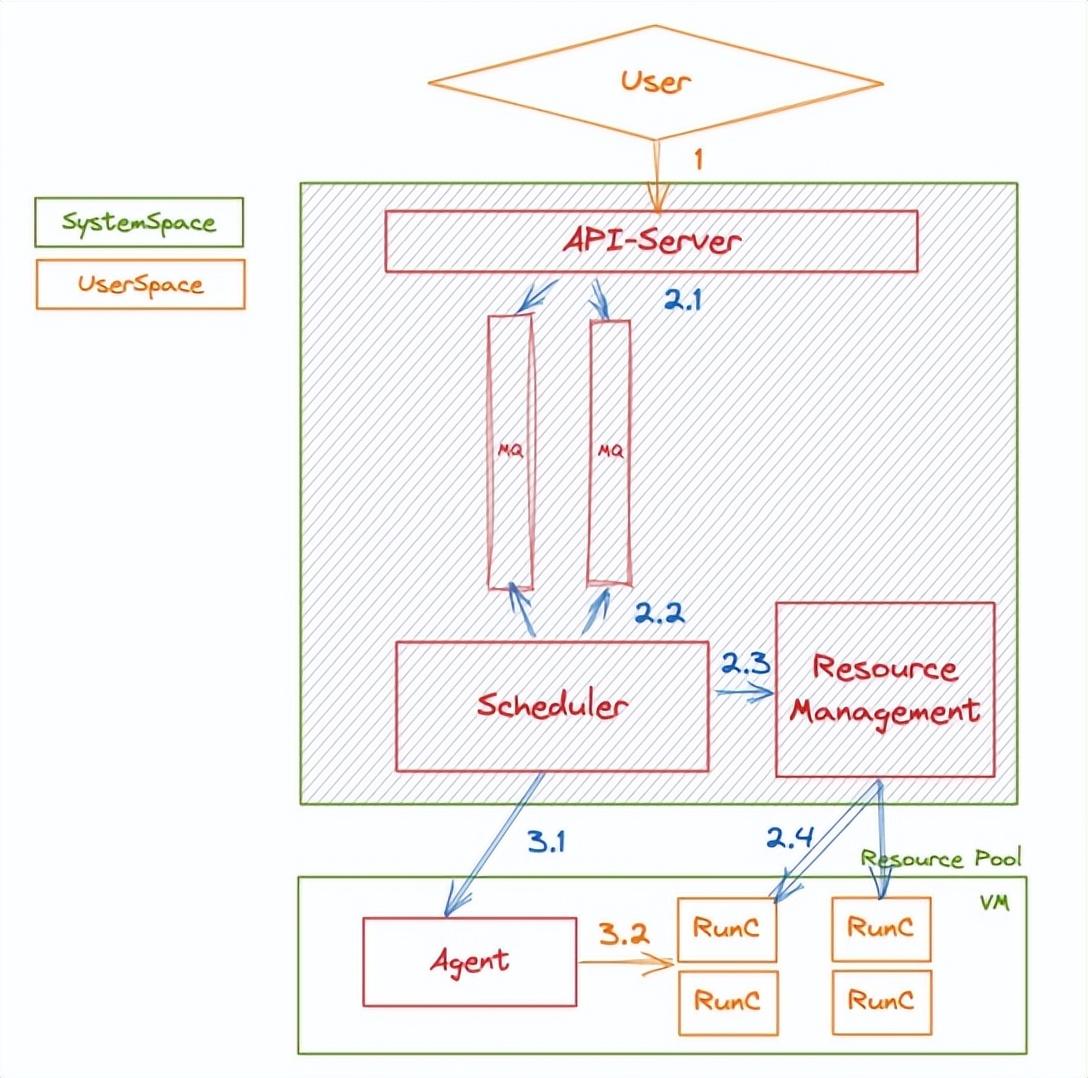
圖 2
首先,用戶調用函數計算 API 下發一個任務(步驟 1)進入系統的 API-Server 中,API-Server 進行校驗后將消息傳入內部隊列(步驟 2.1)。后臺有一個異步模塊實時監聽內部隊列(步驟 2.2),之后調用資源管理模塊獲取運行時資源(步驟 2.2-2.3)。獲取運行時資源后,調度模塊將任務數據下發到 VM 級別的客戶端中(步驟 3.1),并由客戶端將任務轉發至實際的用戶運行資源(步驟 3.2)。為了做到上文中所提到的兩個維度的保障,我們需要在以下層面進行支持:
1、系統側保障:在步驟 2.1 - 3.1 中,任何一個中間過程的 Failover 只能觸發一次步驟 3.2 的執行,即只會調度一次用戶實例的運行;
2、用戶側應用級別去重能力:能夠支持用戶多次反復執行步驟 1,但實際只會觸發一次 步驟 3.2 的執行。
系統側優雅升級 & Failover 時的任務分發去重保證
當用戶的消息進入函數計算系統中(即完成步驟 2.1)后,用戶的請求將收到 HTTP 狀態碼 202 的 Response,用戶可以認為已經成功提交一次任務。從該任務消息進入 MQ 起,其生命周期便由 Scheduler 維護,所以 Scheduler 的穩定性及 MQ 的穩定性將直接影響系統 Exactly Once 的實現方案。
在大多數開源消息系統中(如 MQ、Kafka)一般都提供消息多副本存儲及唯一消費的語義。函數計算所使用的消息隊列(最底層為 RocketMQ)也是同樣的,底層存儲的 3 副本實現使得我們無需關注消息存儲方面的穩定性。除此之外,函數計算所使用的的消息隊列還具有以下特性:
1、消費的唯一性:每一個隊列中的每一條消息當被消費后,會進入“不可見模式”。在此模式下,其他消費者無法獲取該消息;
2、每條消息的實際消費者需要實時更新該模式的不可見時間;當消費者消費完成后,需要顯示的刪除該消息。因此,消息在隊列中的的整個生命周期如下圖所示:
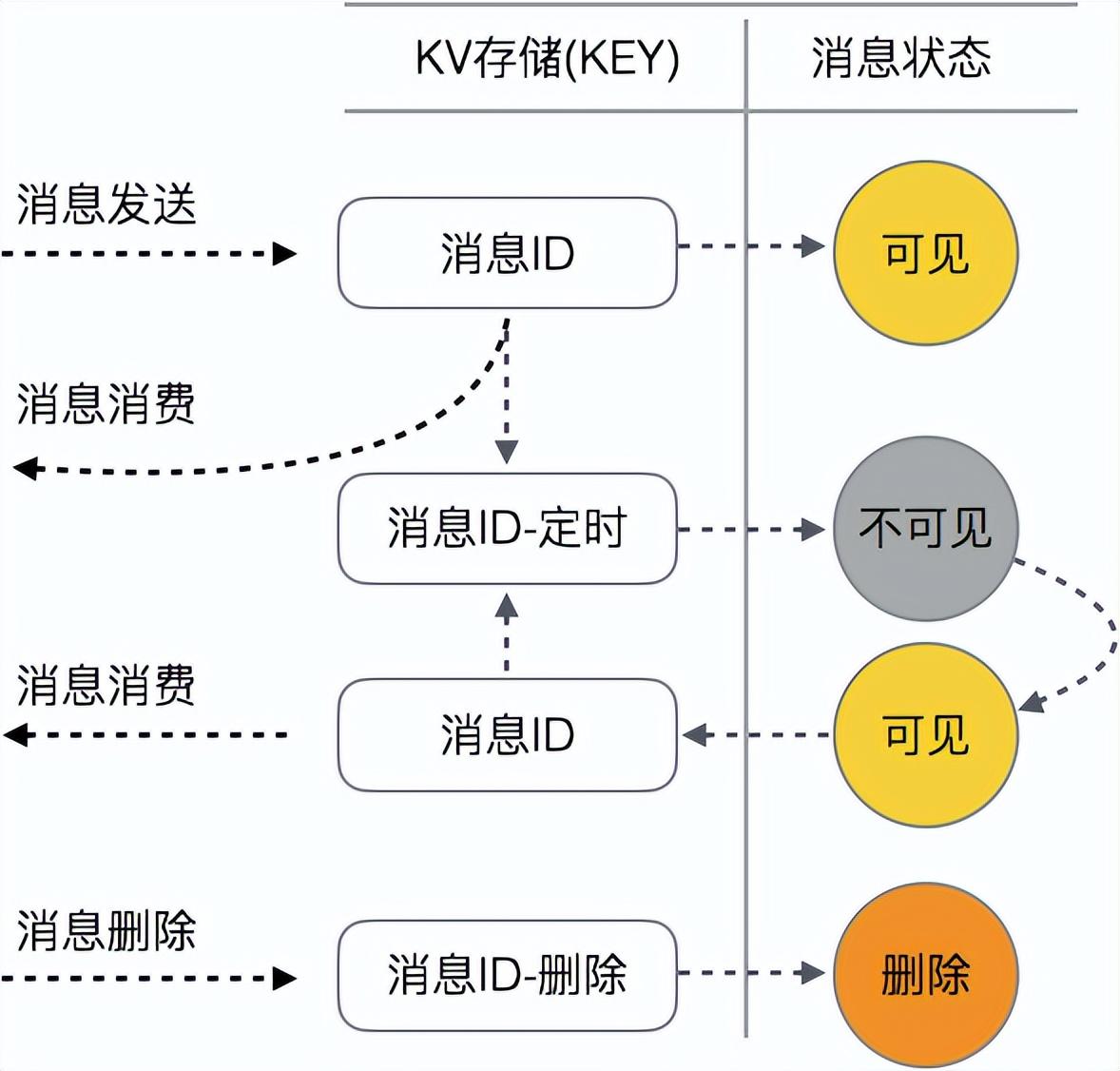
圖 3
Scheduler 主要負責消息的處理,其任務主要有以下幾個部分組成:
1、根據函數計算負載均衡模塊的調度策略,監聽自身所負責的隊列;
2、當隊列中出現消息后,拉取消息,并在內存中維持一個狀態:直到消息消費完成(用戶實例返回函數執行結果)前,不斷更新消息的可見時間,確保消息不會再次在隊列中出現;
3、當任務執行完成后,顯示刪除該消息。
在隊列的調度模型方面,函數計算對于普通用戶采用“單隊列”的管理模式;即每一個用戶的所有異步執行請求由一個獨立隊列相互隔離,并且由一個 Scheduler 固定負責。這個負載的映射關系由函數計算的負載均衡服務進行管理,如下圖所示(我們在后續文章中還會更為詳細的介紹這部分內容):
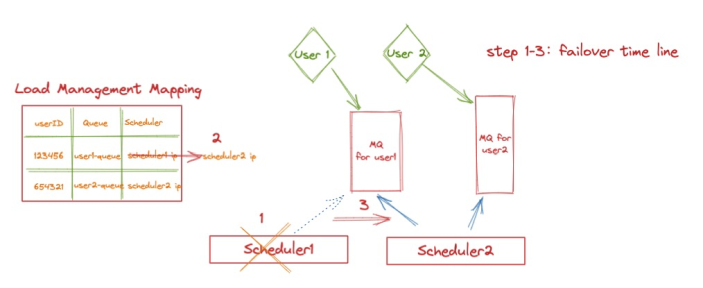
圖 4
當 Scheduler 1 發生宕機或升級時,任務由兩種執行狀態:
1、如果消息還未傳遞到用戶的執行實例中(圖 2 中的步驟 3.1 ~ 3.2),那么當這臺 Scheduler 負責的隊列被其他 Scheduler 拾起后,消息將在消費可見期后再次出現,因此 Scheduler 2 將再次獲取該消息,做到后續的觸發。
2、如果消息已經開始執行(步驟 3.2),當消息在 Scheduler 2 中再次出現后,我們依賴用戶 VM 中的 Agent 進行狀態管理。此時 Scheduler 2 將向對應的 Agent 發送執行請求;此時 Agent 發現該消息已經存在于內存中,那么將直接忽略執行請求,并將執行的結果在執行后通過此鏈接告知 Scheduler 2,進而完成 Failover 的恢復。
用戶側業務級別的分發去重實現
函數計算系統能夠做到對于單點故障下的每條消息準確的消費能力,但是如果用戶側對于同一條業務數據反復觸發函數執行的話,函數計算無法識別不同消息是否在邏輯上是同一個任務。這種情況往往發生在網絡分區。在圖 2 中,如果用戶調用 1 發生超時,此時有可能有兩種情況:
1、消息未到達函數計算系統,任務未成功提交;
2、消息已經到達函數計算并入隊,任務提交成功,但由于超時用戶無法得知提交成功的信息。
大多數情況下用戶會對此次的提交進行重試。如果是第 2 種情況,那么同一個任務將被提交并執行多次。因此函數計算需要提供一種機制,保證這種場景下業務的準確性。
函數計算提供了 TaskID 這一任務概念(StatefulAsyncInvocationID)。該 ID 全局唯一。用戶每次提交任務均可以指定這樣一個 ID。當發生請求超時時,用戶可以進行無限次重試。所有的重復重試將在函數計算側進行校驗。函數計算內部使用 DB 對任務 Meta 數據進行存儲;當有相同 ID 進入系統時該次請求將被拒絕,并返回 400 錯誤。此時客戶端即可得知任務的提交情況。
在實際使用中以 Go SDK 為例,您可以編輯如下觸發任務的代碼:
便提交了一個獨一無二的任務。
總結
本文介紹了函數計算 Serverless Task 對于任務觸發去重的相關技術細節,以便支持對于任務執行準確性有嚴格要求的場景。在使用 Serverless Task 后,您無需擔心任何系統組件的 Failover,您每次提交的任務將被準確執行一次。為了支持業務側語義的分發去重,您可以在提交任務時設置任務的全局唯一 ID,使用函數計算提供的能力幫您對任務進行去重處理。



















