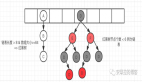
面試官:請設計一個能支撐百萬連接的系統架構!

1、到底什么是連接?
假如說現在你有一個系統,他需要連接很多很多的硬件設備,這些硬件設備都要跟你的系統來通信。
那么,怎么跟你的系統通信呢?
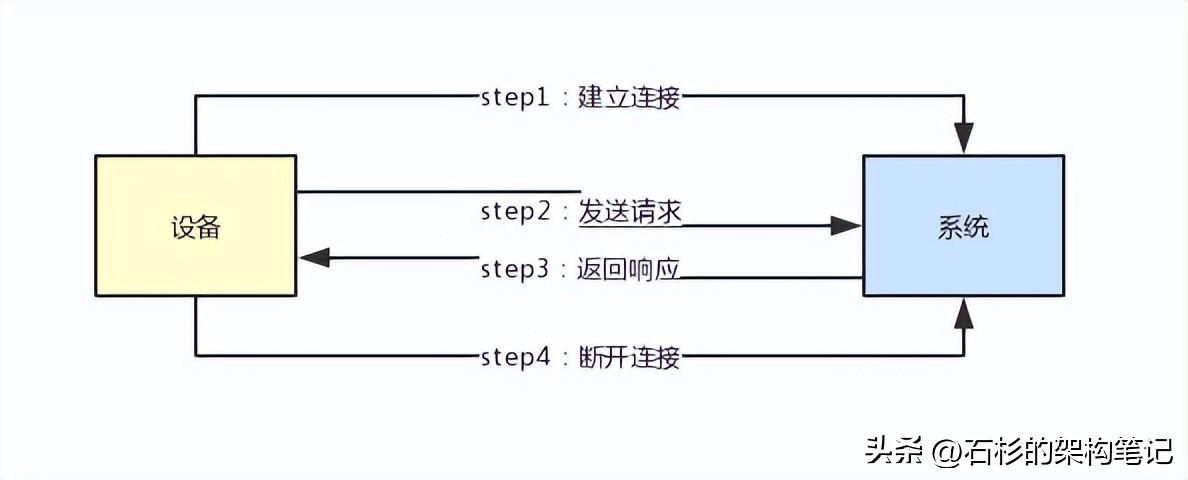
首先,他一定會跟你的系統建立連接,然后會基于那個連接發送請求給你的系統。
接著你的系統會返回響應給那個系統,最后是大家一起把連接給斷開,釋放掉網絡資源。
所以我們來看一下下面的那個圖,感受一下這個所謂的連接到底是個什么概念。
2、為什么每次發送請求都要建立連接?
但是大家看著上面的那個圖,是不是感覺有一個很大的問題。
什么問題呢?那就是為啥每次發送請求,都必須要建立一個連接,然后再斷開一個連接?
要知道,網絡連接的建立和連接涉及到多次網絡通信,本質是一個比較耗費資源的過程。
所以說咱們完全沒必要每次發送請求都要建立一次連接,斷開一次連接。
我們完全可以建立好一個連接,然后設備就不停的發送請求過來,系統就通過那個連接返回響應。
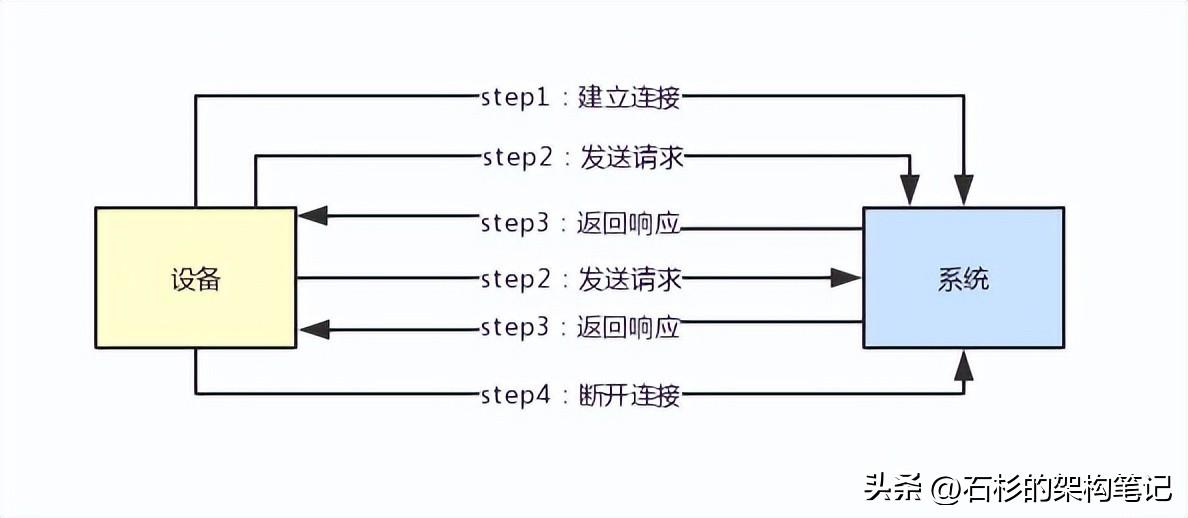
大家完全可以多次通過一個連接發送請求和返回響應,這就是所謂的長連接。
也就是說,如果你一個連接建立之后,然后發送請求,接著就斷開,那這個連接維持的時間是很短的,這個就是所謂的短連接。
那如果一個設備跟你的系統建立好一個連接,然后接著就不停的通過這個連接發送請求接收響應,就可以避免不停的創建連接和斷開連接的開銷了。
大家看下面的圖,體驗一下這個過程。在圖里面,兩次連接之間,有很多次發送請求和接收響應的過程,這樣就可以利用一個連接但是進行多次通信了。
3、長連接模式下需要耗費大量線程資源
但是現在問題又來了,長連接的模式確實是不錯的,但是如果說每個設備都要跟系統長期維持一個連接,那么對于系統來說就需要搞一個線程,這個線程需要去維護一個設備的長連接,然后通過這個連接跟一個設備不停的通信,接收人家發送過來的請求,返回響應給人家。
大家看下面的圖,每個設備都要跟系統維持一個連接,那么對于每個設備的連接,系統都會有一個獨立的線程來維護這個連接。
因為你必須要有一個線程不停的嘗試從網絡連接中讀取請求,接著要處理請求,最后還要返回響應給設備。
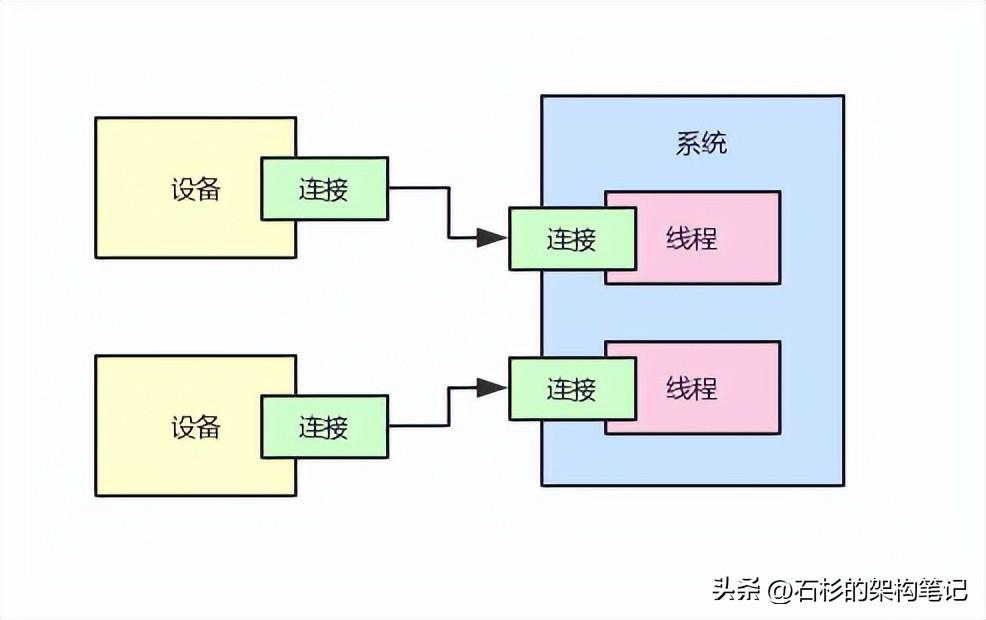
那么這種模式有什么缺點呢?
缺點是很顯而易見的,假如說此時你有上百萬個設備要跟你的系統進行連接,假設你的系統做了集群部署一共有100個服務實例,難道每個服務實例要維持1萬個連接支撐跟1萬個設備的通信?
如果這樣的話,每個服務實例不就是要維持1萬個線程來維持1萬個連接了嗎?大家覺得這個事兒靠譜嗎?
根據線上的生產經驗,一般4核8G的標準服務用的虛擬機,自己開辟的工作線程在一兩百個就會讓CPU負載很高了,最佳的建議就是在幾十個工作線程就差不多。
所以要是期望每個服務實例來維持上萬個線程,那幾乎是不可能的,所以這種模式最大的問題就在于這里,沒法支撐大量連接。
4、Kafka遇到的問題:應對大量客戶端連接
實際上,對于大名鼎鼎的消息系統Kafka來說,他也是會面對同樣的問題,因為他需要應對大量的客戶端連接。
有很多生產者和消費者都要跟Kafka建立類似上面的長連接,然后基于一個連接,一直不停的通信。
舉個例子,比如生產者需要通過一個連接,不停的發送數據給Kafka。然后Kafka也要通過這個連接不停的返回響應給生產者。
消費者也需要通過一個連接不停的從Kafka獲取數據,Kafka需要通過這個連接不停的返回數據給消費者。
大家看下面的圖,感受一下Kafka的生產現場。
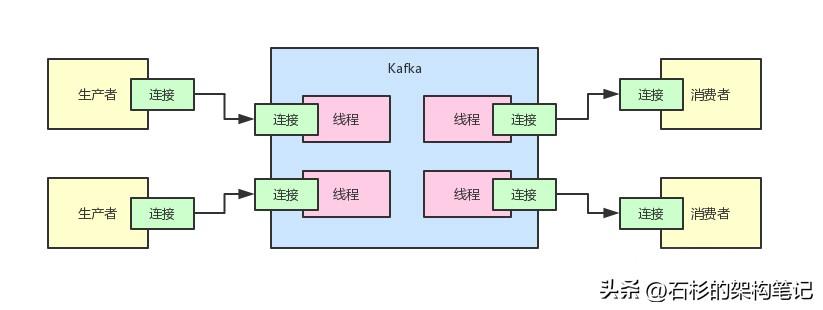
那假如Kafka就簡單的按照這個架構來處理,如果你的公司里有幾萬幾十萬個的生產者或者消費者的服務實例,難道Kafka集群就要為了幾萬幾十萬個連接來維護這么多的線程嗎?
同樣,這是不現實的,因為線程是昂貴的資源,不可能在集群里使用那么多的線程。
5、Kafka的架構實踐:Reactor多路復用
針對這個問題,大名鼎鼎的Kafka采用的架構策略是Reactor多路復用模型。
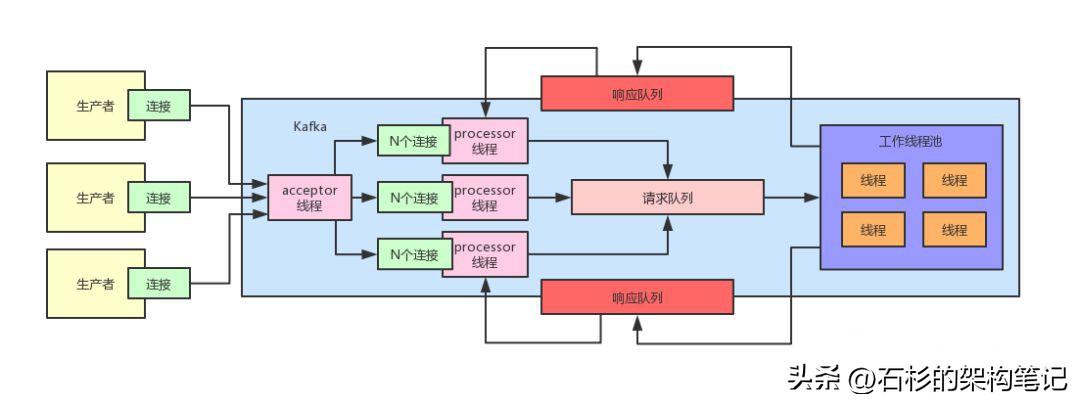
簡單來說,就是搞一個acceptor線程,基于底層操作系統的支持,實現連接請求監聽。
如果有某個設備發送了建立連接的請求過來,那么那個線程就把這個建立好的連接交給processor線程。
每個processor線程會被分配N多個連接,一個線程就可以負責維持N多個連接,他同樣會基于底層操作系統的支持監聽N多連接的請求。
如果某個連接發送了請求過來,那么這個processor線程就會把請求放到一個請求隊列里去。
接著后臺有一個線程池,這個線程池里有工作線程,會從請求隊列里獲取請求,處理請求,接著將請求對應的響應放到每個processor線程對應的一個響應隊列里去。
最后,processor線程會把自己的響應隊列里的響應發送回給客戶端。
說了這么多,還是來一張圖,大家看下面的圖,就可以理解上述整個過程了。
6、優化后的架構是如何支撐大量連接的?
那么上面優化后的那套架構,是如何支撐大量連接的呢?
其實很簡單。這里最關鍵的一個因素,就是processor線程是一個人維持N個線程,基于底層操作系統的特殊機制的支持,一個人可以監聽N個連接的請求。
這是極為關鍵的一個步驟,就僅此一個步驟就可以讓一個線程支持多個連接了,不需要一個連接一個線程來支持。
而且那個processor線程僅僅是接收請求和發送響應,所有的請求都會入隊列排隊,交給后臺線程池來處理。
比如說按照100萬連接來計算,如果有100臺機器來處理,按照老的模式,每臺機器需要維持1萬個線程來處理1萬個連接。
但是如果按照這種多路復用的模式,可能就比如10個processor + 40個線程的線程池,一共50個線程就可以上萬連接。
在這種模式下,每臺機器有限的線程數量可以抗住大量的連接。
因此實際上我們在設計這種支撐大量連接的系統的時候,完全可以參考這種架構,設計成多路復用的模式,用幾十個線程處理成千上萬個連接,最終實現百萬連接的處理架構。