譯者| 朱先忠
審校 | 孫淑娟
YOLOv8是什么?
YOLOv8是Ultralytics公司推出的基于對象檢測模型的YOLO最新系列,它能夠提供截至目前最先進的對象檢測性能。
借助于以前的YOLO模型版本支持技術,YOLOv8模型運行得更快、更準確,同時為執行任務的訓練模型提供了統一的框架,這包括:
- 目標檢測
- 實例分割
- 圖像分類
在撰寫本文時,Ultralytics的YOLOv8存儲庫中其實還有很多功能有待添加,這包括訓練模型的整套導出功能等。此外,Ultralytics將計劃在Arxiv上發布一篇相關的論文,將對YOLOv8與其他最先進的視覺模型進行比較。
YOLOv8的新功能
Ultralytics為YOLO模型發布了一個全新的存儲庫(https://github.com/ultralytics/ultralytics)。該存儲庫被構建為用于訓練對象檢測、實例分割和圖像分類模型的統一框架。
以下列舉的是這個新版本的一些關鍵功能:
- 用戶友好的API(命令行+Python)。
- 更快、更準確。
- 支持:
- 目標檢測,
- 實例分割和
- 圖像分類。
- 可擴展到所有以前的版本。
- 新的骨干網絡。
- 新的Anchor-Free head對象檢測算法。
- 新的損失函數。
此外,YOLOv8也非常高效和靈活,它可以支持多種導出格式,而且該模型可以在CPU和GPU上運行。
YOLOv8中提供的子模型

YOLOv8模型的每個類別中共有五個模型,以便共同完成檢測、分割和分類任務。其中,YOLOv8 Nano是最快和最小的模型,而YOLOv8Extra Large(YOLOv8x)是其中最準確但最慢的模型。
YOLOv8這次發行中共附帶了以下預訓練模型:
- 在圖像分辨率為640的COCO檢測數據集上訓練的對象檢測檢查點。
- 在圖像分辨率為640的COCO分割數據集上訓練的實例分割檢查點。
- 在圖像分辨率為224的ImageNet數據集上預處理的圖像分類模型。
下面,讓我們來看看使用YOLOv8x進行檢測和實例分割模型的輸出效果,請參考下面的gif動畫。

如何使用YOLOv8?
為了充分發揮出YOLOv8的潛力,需要從存儲庫以及ultralytics包中安裝相應的需求。
要安裝這些需求,我們首先需要克隆一下該模型的存儲庫,命令如下:
git clone https://github.com/ultralytics/ultralytics.git接下來,安裝需求配置文件:
pip install -r requirements.txt在最新版本中,Ultralytics YOLOv8同時提供了完整的命令行界面(CLI)API和Python SDK,用于執行訓練、驗證和推理任務。
為了使用yolo命令行界面(CLI),我們需要安裝ultralytics包,命令如下:
pip install ultralytics如何通過命令行界面(CLI)使用YOLOv8?
安裝必要的軟件包后,我們可以使用yolo命令訪問YOLOv8 CLI。以下給出的是使用yolo CLI運行對象檢測推斷的命令行代碼示例:
yolo task=detect \
mode=predict \
model=yolov8n.pt \
source="image.jpg"其中,task參數可以接受三個參數值:detect、classify和segment,分別對應于檢測、分類和分段三種任務。類似地,mode參數可以有三個取值,分別是train、val或predict。此外,在導出訓練模型時,我們也可以將mode參數指定為export。
有關所有可能的yolo CLI標志和參數,有興趣的讀者可參考鏈接https://docs.ultralytics.com/config/。
如何通過Python API使用YOLOv8?
除了通過上面CLI方式使用YOLOv8外,我們還可以創建一個簡單的Python文件,導入YOLO模塊并執行我們選擇的任務。
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # 加載一個預訓練的YOLOv8n模型
model.train(data="coco128.yaml") #訓練模型
model.val() # 評估驗證集上的模型性能
model.predict(source="https://ultralytics.com/images/bus.jpg") #對圖像進行預測
model.export(format="onnx") # 將模型導出為ONNX格式例如,在上述代碼中首先在COCO128數據集上訓練YOLOv8 Nano模型,然后在驗證集上對其進行評估,最終對樣本圖像進行預測。
接下來,讓我們通過yolo CLI方式來使用對象檢測、實例分割和圖像分類模型進行推斷。
目標檢測的推斷結果
以下命令實現使用YOLOv8 Nano模型對視頻進行檢測。
yolo task=detect mode=predict model=yolov8n.pt source='input/video_3.mp4' show=True該推斷的運行硬件環境是在筆記本電腦GTX 1060 GPU上以幾乎105 FPS的速度運行的,最終我們得到以下輸出結果:

使用YOLOv8 Nano模型進行檢測推斷
需要說明的是,YOLOv8 Nano模型在幾幀內把貓和狗進行了混合。讓我們使用YOLOv8 Extra Large模型對同一視頻進行檢測并檢查輸出。
yolo task=detect mode=predict model=yolov8x.pt source='input/video_3.mp4' show=True注意:上面的YOLOv8 Extra Large模型在GTX 1060 GPU上以平均17 FPS的速度運行。

使用YOLOv8超大模型進行檢測推斷
盡管這一次的誤分類略有減少,但模型仍然在一些幀中進行了錯誤的檢測。
實例分割的推理結果
使用YOLOv8實例分割模型運行推理同樣是很簡單的。我們只需要在上面的命令中更改一下任務和模型名稱即可,結果如下:
yolo task=segment mode=predict model=yolov8x-seg.pt source='input/video_3.mp4' show=True因為實例分割與對象檢測是結合在一起的,所以這一次運行時的平均FPS約為13。

使用YOLOv8超大模型進行分割推斷
分割圖在輸出中看起來很干凈。即使當貓在最后幾幀隱藏在塊下時,模型也能夠檢測并分割它。
圖像分類的推理結果
最后,由于YOLOv8已經提供了預訓練的分類模型,讓我們使用yolov8x-cls模型對同一視頻進行分類推斷。這是截止目前存儲庫提供的最大分類模型。
yolo task=classify mode=predict model=yolov8x-cls.pt source='input/video_3.mp4' show=True
使用YOLOv8超大模型進行分類推斷
默認情況下,視頻用模型預測的前5個類進行標注。在沒有任何后期處理的情況下,標注部分直接使用了ImageNet類名。
YOLOv8 vs YOLOv7 vs YOLOv6 vs YOLOv5
可以看出,YOLOv8模型似乎比之前的YOLO模型表現更好;這不僅是相比于YOLOv5模型來說的,YOLOv8也優越于YOLOv7和YOLOv6模型。
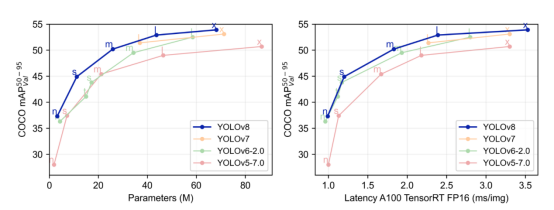
YOLOv8與其他YOLO模型性能相比。
由上圖可以看出,與以640圖像分辨率訓練的其他YOLO模型相比,所有YOLOv8模型在參數數量相似的情況下具有更好的吞吐量。
接下來,讓我們更為詳細了解一下最新的YOLOv8模型與Ultralytics公司的YOLOv5模型的性能差異。下面幾個表格顯示了YOLOv8和YOLOv5之間的綜合比較情況。
總體比較
YOLOv8和YOLOv5之間的性能比較
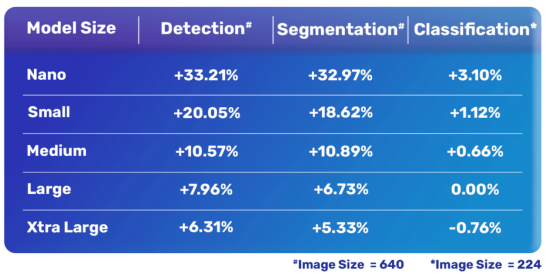
YOLOv8模型與YOLOv5模型性能比較表
對象檢測比較
YOLOv8模型與YOLOv5模型對象檢測性能比較情況見下表:
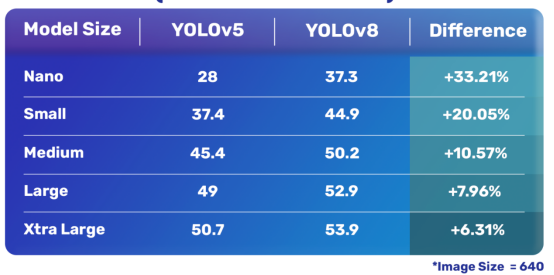
YOLOv8模型與YOLOv5模型對象檢測性能比較
實例分段比較
YOLOv8模型與YOLOv5模型實例分段性能比較情況見下表:
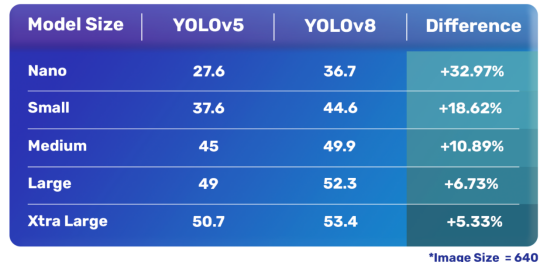
YOLOv8與YOLOv5實例分割模型性能比較
圖像分類比較
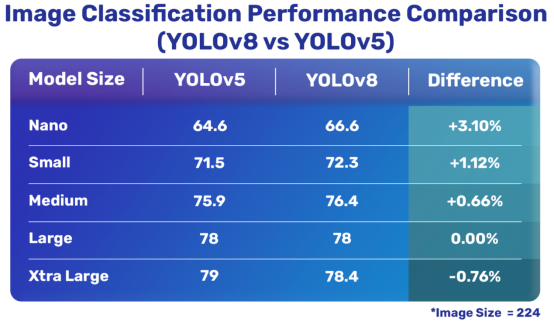
YOLOv8與YOLOv5圖像分類模型情況
整體來看,其實也很明顯,最新的YOLOv8模型比YOLOv5要好得多,除了一種分類模型外。
YOLOv8目標檢測模型的發展
下面給出的這張圖像顯示了YOLO目標檢測模型的時間線以及YOLOv8的演變情況。
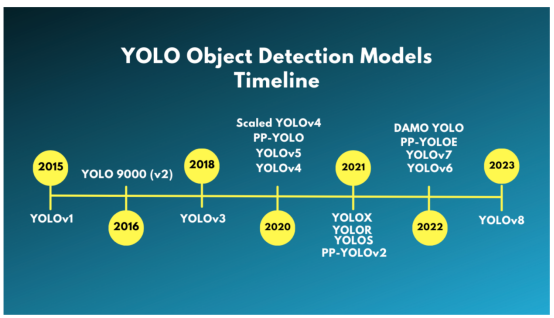
YOLOv8目標檢測模型的演變情況
YOLOv1模型
YOLO對象檢測的第一個版本,即YOLOv1,由Joseph Redmon等人于2015年發布。這是第一個產生SSD和所有后續YOLO模型的單級對象檢測(SSD)模型。
YOLO 9000(第2版)
YOLOv2,又稱YOLO 9000,由YOLOv1的原作者約瑟夫·雷蒙提出。它改進了原來的YOLOv1模型——引入了錨盒(Anchor Box)的概念和更好的主干(即Darknet-19)。
YOLOv3
2018年,約瑟夫·雷蒙和阿里·法哈迪公布了YOLOv3模型。其實,這不是一個架構上的飛躍,算是一份技術報告,但YOLO家族還是有了很大的進步。YOLOv3模型使用Darknet-53主干、殘差連接,并使用更好的預訓練和圖像增強技術來實現改進。
Ultralytics YOLO目標檢測模型
YOLOv3之前的所有YOLO對象檢測模型都使用C編程語言編寫,并使用Darknet框架。但是,新手們發現很難遍歷代碼庫并對模型進行微調。
于是,大約與YOLOv3模型發布的同時,Ultralytics發布了第一個使用PyTorch框架實現的YOLO(YOLOv3)。這個模型更為容易訪問,也更容易用于轉移學習領域。
發布YOLOv3模型后不久,約瑟夫·雷蒙離開了計算機視覺(Computer Vision)研究界。YOLOv4(Alexey等人)是最后一個用Darknet編寫的YOLO模型。之后,又相繼出現了其他許多的YOLO物體檢測模型,例如縮放版YOLOv4、YOLOX、PP-YOLO、YOLOv6和YOLOv7代表了其中較為突出的一些模型。
在YOLOv3之后,Ultralytics還發布了YOLOv5,它比所有其他YOLO模型更好、更快、更易于使用。
截至目前(2023年1月),Ultralytics在Ultralytics存儲庫下發布了YOLOv8,這可能是迄今為止最好的YOLO模型。

結論
在本文中,我們探討了YOLO模型的最新版本,即YOLOv8。其中,我們具體介紹了這款新模型的性能,以及軟件包附帶的命令行界面用法。除此之外,我們還對少數幾個視頻數據進行了推斷展示。
在以后的文章中,我們還將在自定義數據集上對YOLOv8模型進行微調。
最后,如果您自己也在進行任何有關YOLOv8模型的實驗,請在評論部分告訴我
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Ultralytics YOLOv8: State-of-the-Art YOLO Models,作者:Sovit Rath