YOLOv8 詳解:從零開始理解目標檢測
YOLOv8,即廣泛使用的目標檢測算法You Only Look Once(YOLO)的第八次迭代,以其速度、準確性和效率而聞名。然而,理解其架構可能具有挑戰性,尤其是對于初學者。
在本文中,我們將分解驅動YOLOv8的關鍵組件,從卷積神經網絡和殘差塊等基本概念開始,逐步過渡到特征金字塔網絡和CSPDarknet53等高級結構。最后,你將清楚地理解這些元素如何結合在一起,創造出當今最強大的目標檢測模型之一。

1. 卷積架構
卷積神經網絡(CNN)基于一系列處理層,最基礎的是卷積層和池化層。卷積層使用卷積原理,這是一種圖像處理技術,涉及兩個矩陣之間的乘法操作。一個矩陣代表輸入圖像,另一個稱為核(或卷積濾波器),生成一個新矩陣,即過濾后的圖像。這個過程計算效率高,并有助于突出圖像特征,如邊緣。
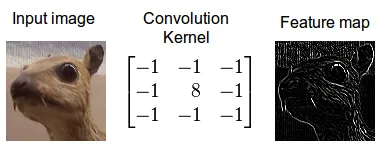
使用濾波器進行邊緣檢測的卷積過程
每次卷積后,通常應用池化層以通過在較小窗口內對信息進行分組來減小過濾圖像的大小,允許在保留基本特征的同時進行壓縮。一種常見的池化是最大池化,它取窗口中的最大值。
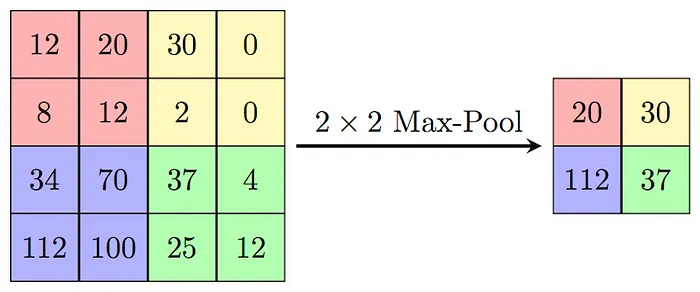
最大池化過程的示意圖
在CNN架構中,這種卷積和池化的循環多次重復,允許從圖像中逐步提取重要特征。輸出數據隨后被展平并通過全連接層的神經元。傳統上,這一層的輸出使用softmax函數處理以產生分類概率。
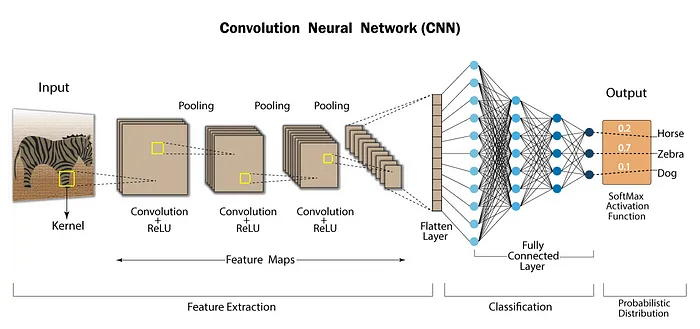
簡化的CNN架構圖
2. 特征金字塔網絡(FPN)
特征金字塔網絡(FPN)是一種旨在增強目標檢測和圖像分割性能的架構。它利用來自不同卷積層的輸出來創建特征的金字塔表示,允許更好地檢測不同尺度的物體。
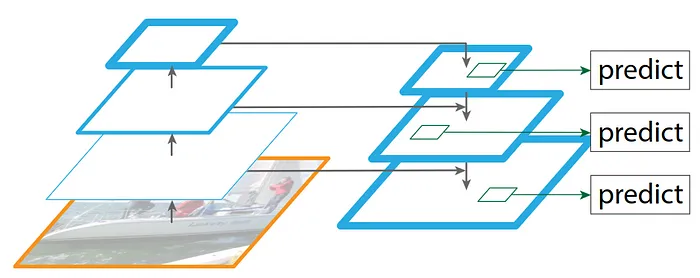
展示多尺度目標檢測的特征金字塔網絡(FPN)架構圖
當我們通過卷積網絡的層進行時,更深層的層傾向于捕捉細節,如小物體,而早期層關注更大物體的模式、形狀和邊緣。FPN的目標不僅是使用最終卷積層的輸出,還使用幾個中間層的輸出來檢測多個尺度的物體。這種多尺度檢測能力是FPN有效性的關鍵。
3. 路徑聚合網絡(PANet)
路徑聚合網絡(PANet)是對特征金字塔網絡(FPN)架構的改進。PANet加強了不同特征尺度之間的連接,并引入了額外的機制以更好地聚合信息。
為了更好地理解FPN和PANet之間的區別,想象一棟有好幾層的建筑。每層樓代表圖像中的不同細節層次:在底部,你看到細節(小物體),而在頂部,你得到一個更廣闊的視角(更大的物體)。
- FPN就像一部從底層(小細節)開始向上到頂層(全局視圖)的電梯。在每一層,它收集信息,允許模型在多個尺度上理解圖像。
- PANet增加了另一部從頂層返回底層的電梯,在下降過程中合并每一層的信息。簡而言之,PANet確保所有信息(來自頂部和底部)都被徹底聚合。
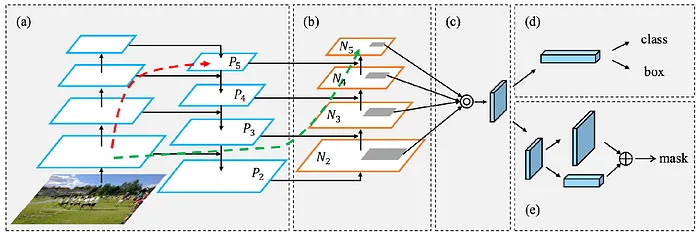
PANet結構
4. 殘差塊
殘差塊由ResNet(殘差網絡)架構引入。它們旨在解決訓練非常深的網絡時的挑戰,例如梯度退化和信息丟失。
殘差塊通常由兩個或三個卷積層組成,但其定義特征是包含一個直接連接(也稱為跳過連接),該連接繞過這些層并將塊的輸入直接鏈接到其輸出。這在下面的圖中有說明。輸入信息被加到卷積層的輸出上,然后傳遞到下一個階段。
簡單來說,如果塊的輸入由x表示,F(x)表示卷積層的變換函數,那么塊的輸出是F(x)+x。

帶有跳過連接的殘差塊
5. CSPNet(跨階段部分網絡)
CSPNet(跨階段部分網絡)是一種用于神經網絡的技術,以提高計算機視覺模型的效率和性能。它通過在通過網絡塊處理之前將特征圖分成兩部分來工作。一部分像往常一樣通過網絡流動,而另一部分稍后添加。這種方法減少了網絡的計算負載,使其更輕巧,而不會犧牲其處理能力。CSPNet有助于平衡準確性和速度之間的權衡,確保模型保持強大而高效。
6. Darknet53和CSPDarknet53
Darknet53(下圖,部分a)是一種卷積神經網絡(CNN),主要用作目標檢測模型中的主干(主干的概念將在下一節中解釋)。它最初是為YOLOv3開發的。Darknet53旨在快速準確,能夠從圖像中提取相關特征。
CSPDarknet53(下圖,部分b)是為YOLOv4開發的Darknet53的增強版本。它結合了CSPNet概念以優化特征學習和減少計算冗余。
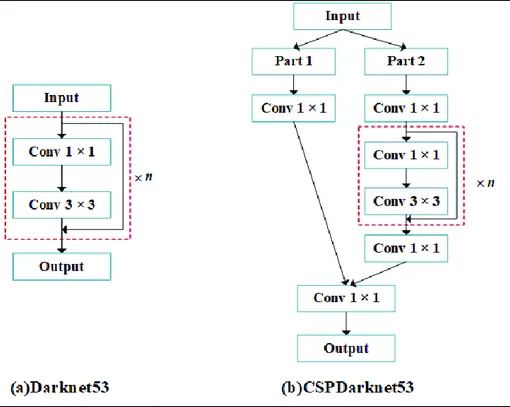
Darknet53(部分a)和CSPDarknet53(部分b)的架構
7. YOLOv8中的一切如何整合
一旦我們理解了這些方法,我們就能更好地理解YOLOv8中的每一層是如何工作的。
事實上,與前身相比,YOLOv8并沒有引入重大的技術革新。然而,其架構已經被簡化和簡化成塊。它由23個主要層組成,每個層都包含子層,子層又包含更多的子層。本質上,YOLOv8就像一個俄羅斯套娃層。
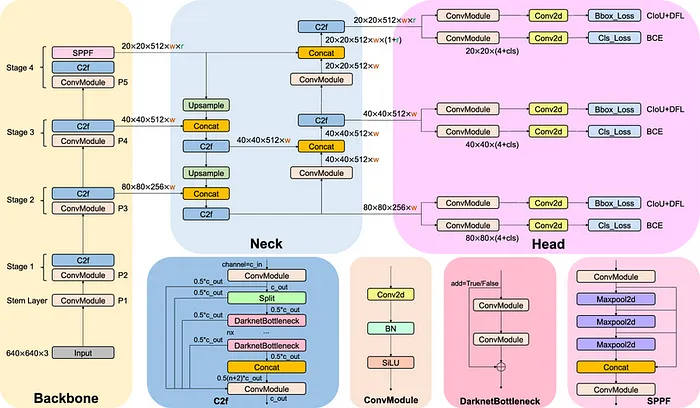
YOLOv8模型架構的詳細圖示。主干、頸部和頭部是我們模型的三個部分,C2f、ConvModule、DarknetBottleneck和SPPF是模塊
在線上的YOLOv8圖表有時乍一看可能過于復雜。為了更好地觀察這些層,模型層字典的分解可以揭示其完整的架構,并澄清它們是如何堆疊的。YOLOv8由七個“ConvModule”層、八個“C2f”層、一個“SPPF”層、兩個“Unsample”層、四個“Concat”層和一個最終檢測層組成。
import torch
model_path = "my_model.pt"
model_dict = torch.load(model_path, map_location=torch.device('cpu'))
model = model_dict['model']
print(model)通過可視化每層的組件,我們可以看到它們如何適應更廣泛的架構。YOLOv8可以分為三個關鍵部分:
- 主干:這部分負責從輸入圖像中提取特征。它使用CSPDarknet53的修改版本,旨在在早期層捕獲簡單的模式,如邊緣和紋理。當我們深入網絡時,它捕獲圖像的更詳細特征。
- 頸部:這部分負責融合主干提取的特征。它使用PANet(路徑聚合網絡)結合不同尺度的特征。卷積層P3、P4和P5被傳輸到金字塔的各個部分(層11、14和20),以確保模型可以檢測各種大小的物體。
- 頭部:這由三個檢測頭組成,它們連接到PANet的三個輸出。這些檢測頭生成邊界框,分配置信度分數,并根據其類別對框進行分類。它們還消除了對同一物體的冗余檢測,這些檢測可能出現在不同的尺度上。
Backbone:
ConvModule (Layer 0) - P1
ConvModule (Layer 1) - P2
ConvModule (Layer 2)
C2f (Layer 3)
ConvModule (Layer 4) - P3
C2f (Layer 5)
ConvModule (Layer 6) - P4
C2f (Layer 7)
SPPF (Layer 9)
Neck:
Upsample (Layer 10)
Concat (Layer 11)
C2f (Layer 12)
Upsample (Layer 13)
Concat (Layer 14)
C2f (Layer 15)
ConvModule (Layer 16)
Concat (Layer 17)
C2f (Layer 18)
Head:
ConvModule (Layer 19)
Concat (Layer 20)
C2f (Layer 21)
Detection Layer (Layer 22) 盡管Ultralytics(YOLOv8的開發者)在其官方模型表示中沒有明確標記這三個部分,但這種劃分被社區普遍接受,因為它反映了以前YOLO版本的結構,并有助于簡化模型的理解。